The rapid development of AI models is driving a sharp increase in global GPU demand. As large language models (LLMs), AI Agents, and automated applications continue to expand, traditional centralized AI cloud platforms are increasingly facing problems such as high costs, concentrated resources, and mounting pressure to scale. Against this backdrop, decentralized GPU networks have become an important area of exploration for Web3 AI infrastructure.
Dolphin Network is an AI inference network that has emerged from this trend. Its core goal is to aggregate scattered GPU resources around the world into open AI infrastructure, while using the POD incentive mechanism to coordinate the relationship among developers, GPU nodes, and the network.
What Is the Core Structure of Dolphin Network?
Dolphin Network is built around three core components: AI inference requesters, the GPU node network, and the validation coordination mechanism.
Developers or applications can submit AI inference requests to the network, such as text generation, chat inference, model calls, or AI Agent tasks. Based on GPU node status, task requirements, and resource availability, the network dynamically assigns each request to suitable nodes for processing.
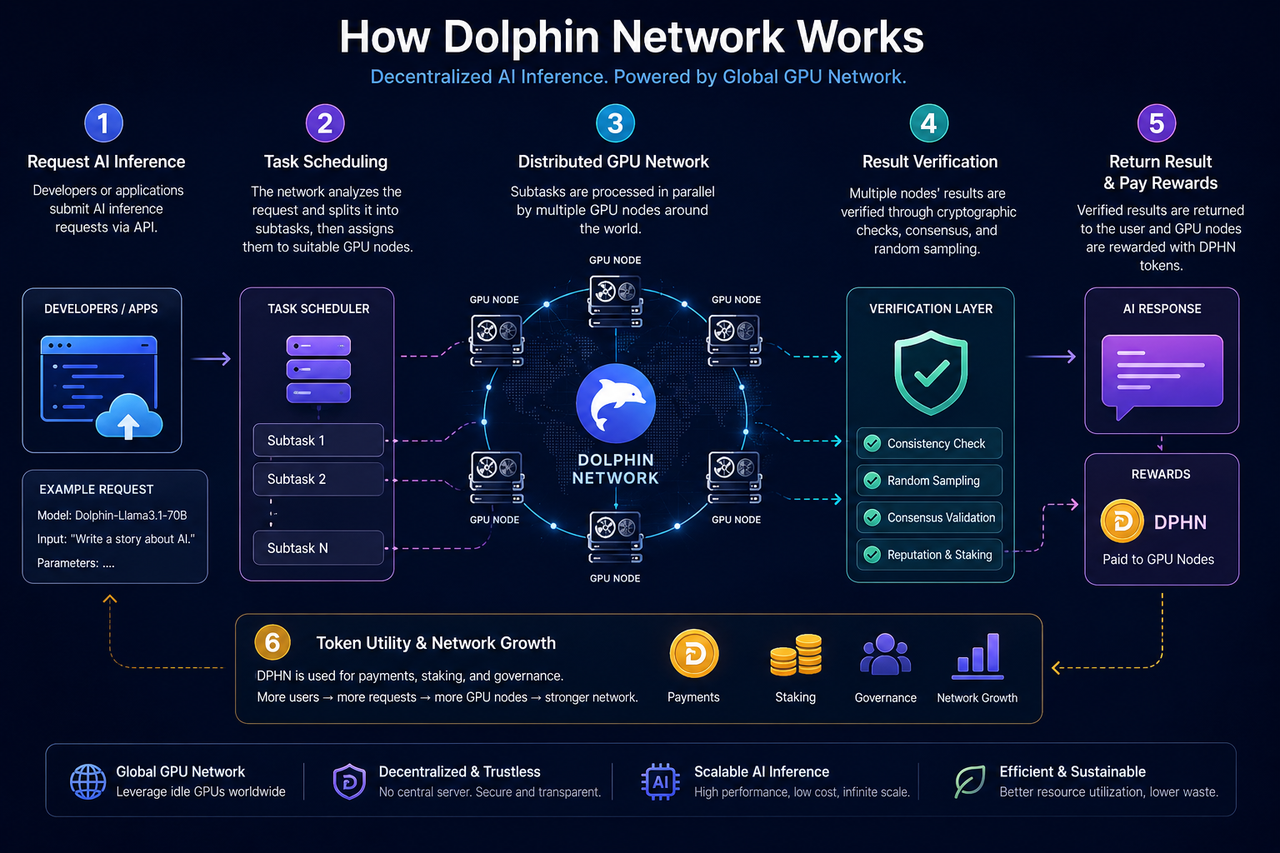
GPU nodes are provided by users around the world. Users can connect idle GPUs to the network, run inference tasks locally, and receive token rewards based on their contribution.
To ensure that results are trustworthy, Dolphin also uses validation and economic mechanisms to coordinate node behavior. These designs include random sampling validation, task review, and staking mechanisms.
How Do AI Inference Requests Enter the Network?
When a developer calls Dolphin Network, the request first enters the task scheduling layer.
This stage is mainly responsible for analyzing the task type, GPU requirements, and model resources. For example, different AI models may require different VRAM configurations, inference speeds, and computing capabilities, so the network must dynamically match tasks based on node status.
In centralized AI cloud platforms, this process is usually handled by a single data center. In Dolphin, however, tasks are assigned to a distributed network of GPU nodes.
Some tasks may also be split into multiple smaller inference requests to improve overall processing efficiency and network concurrency.
How Do GPU Nodes Process AI Inference Tasks?
GPU nodes are the core computing resource of Dolphin Network.
Node operators usually need to deploy designated software and allow the system to call their local GPUs to execute AI inference tasks. Once a task is distributed, the node downloads the relevant model or inference parameters and completes the computation locally.
After completing the task, the node must return the inference result to the network and wait for the validation process to confirm that the result is valid. Only tasks that pass validation are eligible for token rewards.
This model is different from traditional GPU mining. Traditional PoW networks mainly perform hash calculations, while Dolphin’s GPU nodes execute real AI inference tasks, making the system closer to a market for usable computing power.
How Does Dolphin Validate AI Inference Results?
AI inference is different from ordinary blockchain transactions because its results usually cannot be directly verified through simple mathematical formulas. As a result, Dolphin needs additional mechanisms to prevent nodes from submitting incorrect results.
One common method is random sampling validation. The system randomly selects some tasks for review and checks whether multiple nodes return consistent results. If a node repeatedly submits abnormal data, its reputation may be reduced, or it may lose eligibility for rewards.
In addition, some decentralized AI networks also combine staking mechanisms. Nodes must stake a certain amount of tokens to participate in the network, and when malicious behavior occurs, the staked assets may be penalized.
At its core, this mechanism uses economic incentives to constrain node behavior and improve network trustworthiness.
How Is Dolphin Different from Traditional AI Cloud Inference?
Traditional AI cloud platforms usually rely on large centralized data centers, where GPU clusters, model deployment, and API services are controlled by a single company.
Dolphin, by contrast, uses an open GPU network structure. GPU nodes are jointly provided by users around the world, allowing developers to call AI inference services in a more open environment and reduce dependence on a single platform.
Dolphin also places greater emphasis on open AI models and resource sharing. Some networks also support open source model deployment, custom system rules, and open AI Agent scenarios.
However, distributed AI networks also face challenges such as stability, network latency, and uneven node quality. For that reason, the sector is still in an early stage of development.
What Challenges Does Dolphin Network Face?
Although decentralized AI inference networks offer openness and resource sharing advantages, they still face several practical challenges.
First, GPU node performance can vary widely. Differences in VRAM, bandwidth, and inference capability across devices may affect overall network stability.
Second, validating AI inference results remains complex. Compared with blockchain transactions, AI outputs are probabilistic, which makes verification more costly.
In addition, as AI models continue to grow in scale, efficiently scheduling large scale GPU clusters across a distributed network has become an important problem that AI DePIN projects need to solve.
The regulatory environment is also uncertain. Open AI models may involve issues related to data, copyright, and content generation, so AI infrastructure networks will continue to face long term regulatory challenges.
Summary
Dolphin Network is a decentralized AI inference network that combines AI and DePIN. Its core goal is to build open AI infrastructure through GPU nodes around the world. The network coordinates the relationship between developers and GPU nodes through task scheduling, distributed inference, random validation, and the DPHN incentive mechanism.
Compared with traditional centralized AI cloud platforms, Dolphin places greater emphasis on openness, resource sharing, and censorship resistance. For this reason, it is regarded as one of the important directions for Web3 AI infrastructure.
FAQs
How Does Dolphin Use GPU Nodes?
GPU owners can deploy nodes and contribute idle GPU resources to execute AI inference tasks, earning DPHN rewards in return.
What Steps Are Included in Dolphin’s AI Inference Process?
The main stages include task submission, node scheduling, GPU inference execution, result validation, and reward distribution.
Why Is Dolphin Considered a DePIN Project?
Because its core resources are real world GPU hardware, and it uses token incentives to coordinate the operation of distributed infrastructure.
Traditional AI cloud platforms rely on centralized data centers, while Dolphin uses an open GPU network to provide distributed AI inference services.
What Is the Role of DPHN in the Network?
DPHN is used for AI inference payments, node rewards, staking, and economic incentives within the network.








