A medida que las aplicaciones de IA y los Agentes de IA evolucionan con rapidez, cada vez más sistemas adoptan arquitecturas multimodelo. Los modelos de IA difieren notablemente en capacidad de razonamiento, velocidad de respuesta y estructura de costes. Utilizar un solo modelo para todas las tareas suele provocar costes elevados o baja eficiencia. Por ello, el enrutamiento de modelos de IA se ha convertido en un elemento esencial de la infraestructura de IA moderna.
Un AI Router permite distribuir tareas de forma inteligente entre varios modelos, lo que aporta mayor flexibilidad, escalabilidad y estabilidad a los sistemas de IA. Este enfoque colaborativo multimodelo se ha consolidado como arquitectura base en plataformas SaaS de IA, Agentes de IA y soluciones automatizadas.
¿Qué es el enrutamiento de modelos de IA?
El enrutamiento de modelos de IA es una técnica para gestionar solicitudes entre múltiples modelos de IA. Su objetivo es seleccionar el modelo más adecuado para cada solicitud según los requisitos de la tarea.
Tradicionalmente, las aplicaciones de IA se conectan a un solo modelo. Por ejemplo, un chatbot puede utilizar únicamente una API de modelo de lenguaje grande específica. Sin embargo, las necesidades de las tareas pueden variar considerablemente:
- La generación de resúmenes o preguntas y respuestas simples rara vez requiere razonamiento avanzado.
- El análisis lógico complejo o la generación de código exige modelos más potentes.
- La traducción multilingüe puede requerir modelos especialmente optimizados.
Si todas las tareas dependen de un modelo de alto rendimiento, los costes aumentan de forma significativa. Por el contrario, recurrir a un modelo básico para tareas complejas puede afectar la calidad de los resultados.
El enrutamiento de modelos de IA analiza cada solicitud y la asigna dinámicamente al modelo más apropiado, equilibrando rendimiento y costes.
¿Por qué las aplicaciones de IA necesitan varios modelos?
La tecnología de IA avanza y los modelos se especializan cada vez más en capacidades y casos de uso. Muchas aplicaciones de IA adoptan arquitecturas multimodelo para aprovechar estas diferencias.
En primer lugar, cada modelo destaca en áreas distintas. Algunos ofrecen mejor razonamiento complejo, otros son más rápidos o económicos. Combinando varios modelos, el sistema puede seleccionar el más adecuado para cada tarea.
En segundo lugar, una arquitectura multimodelo ayuda a reducir costes operativos. Las tareas sencillas se ejecutan en modelos económicos, mientras que las complejas se asignan a modelos avanzados, lo que reduce el gasto total.
En tercer lugar, los entornos multimodelo refuerzan la fiabilidad. Si un modelo falla o no está disponible, las solicitudes pueden redirigirse a otros, garantizando la continuidad del servicio.
¿Cómo funciona el enrutamiento de modelos de IA?
Los sistemas de enrutamiento de modelos de IA suelen utilizar un Motor de Enrutamiento para decidir qué modelo debe procesar cada solicitud. El motor evalúa varios factores:
Complejidad de la tarea: El sistema analiza la solicitud (como la longitud del prompt o el tipo de tarea) para determinar si se necesita un modelo más avanzado.
Capacidades del modelo: Cada modelo de IA tiene un rendimiento distinto en tareas específicas, como generación de código o procesamiento multimodal.
Velocidad de respuesta: En aplicaciones en tiempo real, como chatbots o Agentes de IA, la latencia es crucial.
Coste de invocación: Las diferencias de precio entre APIs de modelos de IA hacen que el coste sea un factor clave en el enrutamiento.
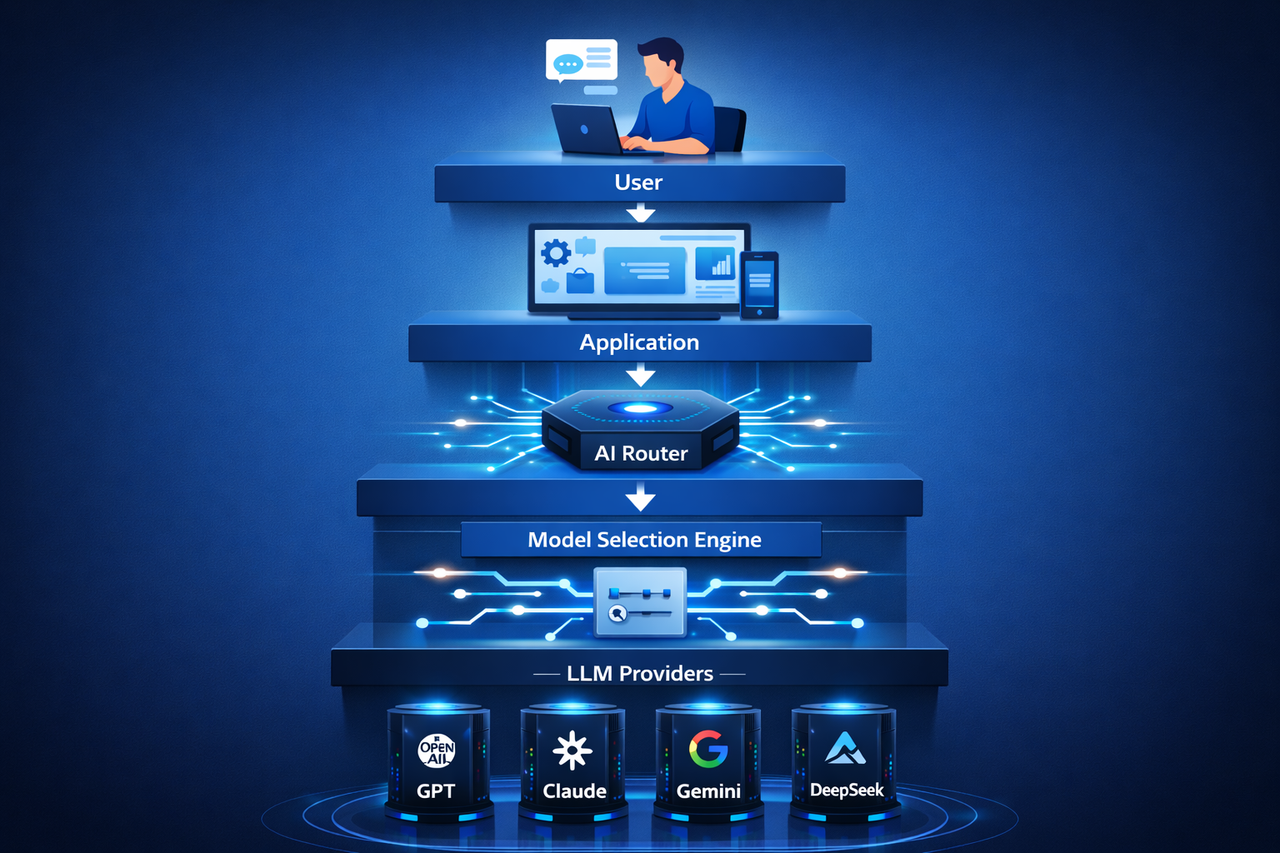
Cuando un usuario o Agente de IA envía una solicitud, el AI Router analiza la tarea, selecciona el modelo óptimo y devuelve el resultado a la aplicación.
Comparación de estrategias de enrutamiento de IA más utilizadas
La infraestructura de IA moderna utiliza diversas estrategias de enrutamiento para optimizar el rendimiento:
Estrategia orientada al coste: El sistema prioriza modelos económicos para la mayoría de tareas y recurre a modelos de alto rendimiento solo cuando es necesario.
Estrategia orientada al rendimiento: En este enfoque se valora la calidad del resultado, eligiendo el modelo más capaz aunque sea más costoso.
Estrategia híbrida: Muchos AI Routers combinan criterios de coste, rendimiento y velocidad de respuesta.
Estrategia específica por tarea: Algunos sistemas seleccionan modelos optimizados para tareas concretas, como generación de código o procesamiento multimodal.
La estrategia óptima depende de la aplicación de IA, por lo que los sistemas de enrutamiento deben adaptarse a las necesidades reales.
Enrutamiento de modelos de IA vs. API Gateway de IA
El enrutamiento de modelos de IA y los API Gateways tradicionales cumplen funciones diferentes:
API Gateway de IA: Gestiona principalmente solicitudes API (autenticación, control de tráfico y seguridad), pero no selecciona el modelo de IA.
AI Model Router: Se encarga de elegir el mejor modelo de IA para cada solicitud y de enrutarla.
En la práctica, los desarrolladores suelen combinar ambos: el API Gateway gestiona las solicitudes y el AI Router selecciona el modelo.
Casos de uso habituales del enrutamiento de modelos de IA
Con la madurez del ecosistema de IA, el enrutamiento de modelos se utiliza en múltiples escenarios, permitiendo la colaboración entre modelos para mejorar la eficiencia.
Agentes de IA: Los agentes suelen requerir distintos modelos para tareas complejas como recuperación de información, análisis y generación de contenido. El enrutamiento de modelos permite que los agentes seleccionen automáticamente el modelo más adecuado.
Plataformas SaaS de IA: Muchas plataformas SaaS ofrecen acceso a varios modelos, por ejemplo, diferentes modelos de lenguaje grande. Un AI Router puede gestionar estas APIs de forma centralizada.
Análisis de datos de IA: En el análisis de datos, distintos modelos pueden encargarse del parsing, el razonamiento lógico y la generación de resultados.
Arquitectura típica de la infraestructura de AI Router
Un sistema de AI Router robusto integra varios componentes esenciales:
Capa de acceso API: Recibe solicitudes de aplicaciones o Agentes de IA.
Capa de decisión de enrutamiento: Analiza cada solicitud para determinar qué modelo de IA utilizar.
Capa de ejecución de modelos: Conecta con varios proveedores de modelos, como servicios de modelos de lenguaje grande.
Sistema de monitorización y optimización: Supervisa el rendimiento, los tiempos de respuesta y los costes de invocación de los modelos, optimizando continuamente las estrategias de enrutamiento.
Esta arquitectura permite asignar tareas de manera eficiente entre modelos y soporta una infraestructura de IA flexible.
El papel de GateRouter en el ecosistema de AI Router
Con el auge de las aplicaciones de IA multimodelo, han surgido plataformas AI Router especializadas que ayudan a los desarrolladores a gestionar múltiples modelos.
Algunos proveedores de infraestructura de IA ofrecen interfaces unificadas de acceso a modelos, como la plataforma GateRouter, que gestiona varios servicios de modelos de lenguaje grande.
A diferencia de los API Gateways tradicionales, GateRouter se orienta a escenarios automatizados de IA, facilitando el acceso a modelos, la invocación automatizada y la ejecución de tareas por parte de los Agentes de IA. GateRouter también integra el protocolo x402 para autopagos de Agentes de IA, permitiendo que las máquinas completen pagos automáticamente al acceder a servicios.
Resumen
El enrutamiento de modelos de IA es una tecnología esencial para arquitecturas multimodelo. Al distribuir tareas entre modelos de forma dinámica, los AI Routers ayudan a las aplicaciones a equilibrar rendimiento, costes y velocidad de respuesta.
Con la expansión de los Agentes de IA y la automatización, las arquitecturas multimodelo están definiendo el futuro de los sistemas de IA. El enrutamiento de modelos incrementa la eficiencia y refuerza la estabilidad y flexibilidad.
En este contexto, las plataformas AI Router se convierten en infraestructura clave, conectando modelos de IA, desarrolladores y aplicaciones automatizadas.
Preguntas frecuentes
¿Qué es el enrutamiento de modelos de IA?
El enrutamiento de modelos de IA es una tecnología que selecciona dinámicamente el mejor modelo entre varios modelos de IA para procesar una solicitud.
¿Cuál es la diferencia entre un AI Router y un LLM Router?
Un LLM Router se dedica normalmente a modelos de lenguaje grande, mientras que un AI Router gestiona una gama más amplia de modelos de IA.
¿Por qué las aplicaciones de IA necesitan arquitecturas multimodelo?
Los modelos de IA difieren en capacidad, coste y velocidad. Una arquitectura multimodelo permite seleccionar el modelo más adecuado para cada tarea.
¿Cómo reduce costes el enrutamiento de modelos de IA?
El enrutamiento asigna tareas sencillas a modelos económicos y tareas complejas a modelos de alto rendimiento, lo que reduce los gastos operativos generales.








