Après la progression fulgurante des capacités des grands modèles, les entreprises se concentrent désormais moins sur « la disponibilité d’un modèle » que sur « sa fiabilité et sa pérennité dans des environnements commerciaux réels ». Si les clusters d'entraînement permettent d'agréger la puissance de hachage, les systèmes de production doivent gérer les requêtes continues, la latence de queue, l’itération des versions, les droits d’accès aux données et la responsabilité en cas d’incident. En somme, le cœur de la bataille pour l’IA en entreprise se déplace vers l’inférence et les frameworks opérationnels. Les agents accentuent ce déplacement, en élargissant les défis du « Q&R en une seule étape » vers des « tâches multi-étapes, invocation d’outils et gestion d’état », ce qui élève considérablement les exigences en matière d’infrastructure et de gouvernance.
Si l’on considère l’infrastructure IA comme une chaîne continue, des puces jusqu’aux centres de données, puis aux services et à la gouvernance, cet article se concentre sur l’extrémité de la chaîne : les services d’inférence, l’accès aux données et la gouvernance organisationnelle. Les sujets en amont tels que HBM, l’alimentation et les centres de données relèvent de discussions sur l’offre ; cet article part du principe que les lecteurs disposent déjà d’une compréhension de base des architectures en couches.
Pourquoi « inférence en production » et « puissance de hachage d’entraînement » sont des défis distincts
Même si l’entraînement et l’inférence partagent des composants matériels comme les GPU, les réseaux et le stockage, leurs objectifs d’optimisation diffèrent. L’entraînement privilégie le débit et le parallélisme prolongé ; l’inférence met l’accent sur la concurrence, la latence de queue, le coût par requête et le rythme des versions et des rollbacks. Pour les entreprises, les distinctions suivantes influent directement sur les choix architecturaux et les limites de procurement :
- Structure des coûts : L’entraînement correspond généralement à une dépense d’investissement par phase, tandis que les coûts d’inférence augmentent linéairement avec le volume d’activité et sont davantage sensibles au caching, au batching, au routage et au choix du modèle.
- Définition de la disponibilité : Les tâches d’entraînement peuvent être mises en file d’attente et relancées ; l’inférence en ligne est généralement soumise à des SLA, nécessitant la limitation du débit, la dégradation et des stratégies multi-répliques.
- Fréquence des changements : Les mises à jour du modèle, des prompts, des politiques d’outils et des bases de connaissances sont plus fréquentes, ce qui exige des processus de publication auditables plutôt que des déploiements uniques.
- Limites des données : Les données d’entraînement sont généralement contenues dans des environnements contrôlés, tandis que l’inférence accède souvent à des données client, des documents internes et des interfaces de systèmes métiers, ce qui impose des droits d’accès plus stricts et un masquage des données.
Ainsi, lors de l’évaluation de l’infrastructure IA en entreprise, il est plus pertinent de se concentrer sur les capacités de la couche service — gateways, routage, observabilité, publication, droits d’accès et audit — plutôt que de comparer simplement la taille des clusters d’entraînement.
Stack d’inférence de niveau production : de l’entrée à l’observabilité
Un stack d’inférence solide inclut généralement au moins les modules suivants. Les fournisseurs peuvent utiliser différents noms de produits, mais les fonctions principales restent identiques.
API Gateway et gouvernance du trafic
Un point d’entrée unifié pour l’authentification, les quotas, la limitation du débit et la terminaison TLS ; lors de l’exposition des capacités du modèle vers l’extérieur, la gateway constitue la première ligne de défense pour la sécurité et la stratégie commerciale.
Routage des modèles et gestion des versions
Les entreprises exécutent souvent plusieurs modèles simultanément (pour différentes tâches, coûts et niveaux de conformité). Le routage doit permettre le détournement par locataire, scénario et niveau de risque, ainsi que les publications grises et les rollbacks, afin d’éviter les échecs liés à des remplacements « tout-en-un ».
Sérialisation, batching et caching
Sous forte concurrence, la sérialisation/désérialisation, les stratégies de batching et la conception du cache KV ou sémantique influent fortement sur la latence de queue et le coût. Le caching introduit aussi des risques de cohérence, nécessitant des politiques claires d’invalidation et de gestion des données sensibles.
Recherche vectorielle et intégration RAG (si applicable)
La génération augmentée par recherche relie étroitement l’inférence et les systèmes de données : mises à jour d’index, filtrage par autorisation, affichage de fragments de référence et contrôle du risque d’hallucination font partie intégrante du framework opérationnel, et non des « add-ons » externes au modèle.
Observabilité, journalisation et gestion des coûts
Au minimum, l’utilisation des tokens, les percentiles de latence et les types d’erreurs doivent être détaillés par locataire, version de modèle et politique de routage. Sans cela, la planification de capacité est difficile et les revues post-incidents ne permettent pas d’identifier précisément si les problèmes proviennent du modèle, des données ou de la gateway.
Ces modules déterminent la stabilité des expériences en ligne, la maîtrise des coûts et la traçabilité des problèmes. L’absence d’un composant conduit souvent à des systèmes performants en démonstration à faible charge, mais qui révèlent des défauts lors des pics ou des changements.
Déploiement multi-modèles et hybride : routage, coût et souveraineté des données
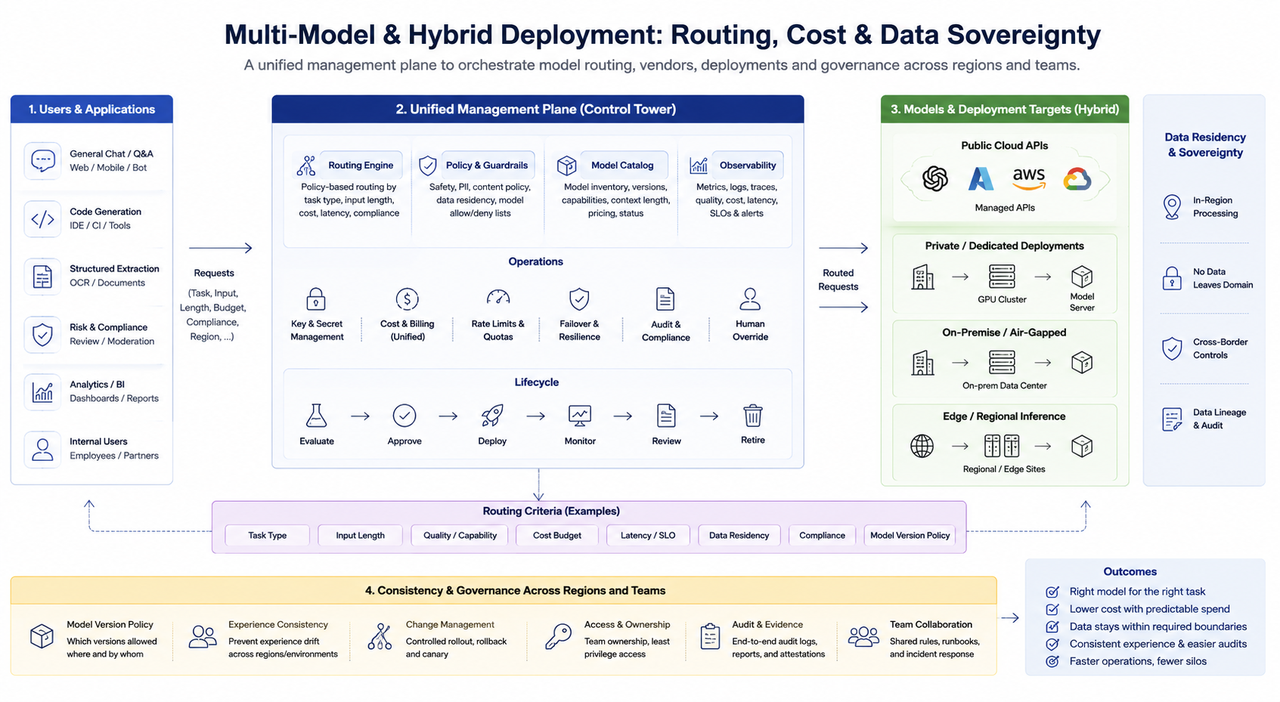
Dans les environnements d’entreprise, il est courant que plusieurs modèles coexistent : des tâches telles que la conversation générale, le code, l’extraction structurée et la revue de contrôle des risques ne conviennent pas à un seul modèle ou à une seule stratégie de paramètres. Les principaux défis d’ingénierie des configurations multi-modèles incluent :
- Stratégie de routage : Sélectionner les modèles selon le type de tâche, la longueur d’entrée, les contraintes de coût et les exigences de conformité ; cela requiert des stratégies par défaut interprétables et des interventions manuelles opérationnelles.
- Mix de fournisseurs : Les API cloud publiques, les déploiements sur site et les clusters dédiés peuvent coexister ; une gestion unifiée des clés, des standards de facturation et du failover est essentielle pour éviter que « plusieurs fournisseurs deviennent des silos isolés ».
- Cloud hybride et résidence des données : Les opérations financières, gouvernementales et transfrontalières exigent souvent que les données restent dans un domaine ou une juridiction ; le déploiement d’inférence façonne l’architecture réseau et le placement du cache, interagissant avec l’infrastructure de troisième couche comme les centres de données, l’alimentation et les réseaux régionaux.
- Gouvernance de la cohérence : Des politiques claires sont nécessaires pour déterminer si la même activité dans différentes régions ou environnements peut utiliser différentes versions de modèle ; sinon, des dérives d’expérience et des défis d’audit apparaîtront.
Du point de vue organisationnel, la difficulté des systèmes multi-modèles réside souvent non pas dans le « nombre de modèles », mais dans l’absence d’un plan de gestion unifié. Lorsque les règles de routage, les clés, la surveillance et les processus de publication sont dispersés entre les équipes, les coûts de dépannage et de conformité augmentent rapidement.
Agent : orchestration, limites des outils et auditabilité
Les agents étendent l’inférence à des tâches multi-étapes : planification, invocation d’outils, opérations de mémoire et génération des actions suivantes. Pour les systèmes d’entreprise, cela signifie que la surface de risque s’étend du « résultat textuel » à des impacts exécutables sur des systèmes externes.
Les principaux axes de vigilance en pratique incluent :
- Liste blanche d’outils et moindre privilège : Chaque outil doit avoir des autorisations clairement définies (bases de données en lecture seule, API restreintes, chemins de fichiers limités, etc.) afin d’éviter une invocation d’outils « omnipotente » et trop large.
- Collaboration homme-machine et points de confirmation : Pour les actions à haut risque telles que le transfert de fonds, les changements d’autorisation ou les exportations massives de données, imposer des flux de confirmation ou d’approbation obligatoires plutôt qu’une automatisation complète.
- État de session et limites de mémoire : La mémoire à long terme implique des cycles de confidentialité et de conservation ; le contexte à court terme impacte le coût et les stratégies de troncature. Les politiques de hiérarchisation et de nettoyage des données doivent être alignées sur les exigences de conformité.
- Traçabilité auditable : Enregistrer « quand le modèle, sur la base de quel contexte, a invoqué quels outils et ce qui a été retourné » ; les revues d’incidents et les enquêtes réglementaires reposent souvent sur cela, et non sur la seule réponse finale.
- Sandbox et isolation : L’exécution de code et le chargement de plugins requièrent des environnements d’exécution isolés pour empêcher qu’une injection de prompt ne devienne une attaque au niveau de l’exécution.
Les agents offrent une valeur par l’automatisation, à condition que les limites soient clairement définies. Si celles-ci sont floues, la complexité du système peut croître de façon exponentielle et les coûts opérationnels et juridiques peuvent exploser avant tout bénéfice commercial.
Les exigences de conformité varient selon l’industrie, mais les systèmes de production en entreprise devraient au moins satisfaire le « minimum requis », à élargir selon les besoins réglementaires.
- Identité et accès : Comptes de service, comptes utilisateurs, rotation des clés API et principe du moindre privilège ; distinguer les identifiants « développement/test » et « invocation en production ».
- Données et confidentialité : Masquage des champs sensibles, masquage des logs, séparation des données d’entraînement et d’inférence ; définir et conserver clairement les accords de traitement de données avec les fournisseurs de modèles tiers.
- Supply chain des modèles : Traçabilité des sources de modèles, hash des versions, dépendances et images de conteneurs ; empêcher l’entrée de « poids inconnus » dans le chemin de production.
- Sécurité du contenu et prévention des abus
- Appliquer le filtrage des politiques sur les entrées/sorties selon les besoins ; mettre en œuvre la limitation du débit et la détection d’anomalies pour les appels batch automatisés.
- Réponse aux incidents : Rollback du modèle, commutation de routage, révocation des clés, procédures de notification client ; spécifier clairement les parties responsables et les chemins d’escalade.
Ces capacités ne remplacent pas la défense en profondeur assurée par l’équipe sécurité, mais sont essentielles pour intégrer les services IA dans le cadre de gestion des risques existant de l’entreprise, plutôt que de les laisser comme des « exceptions d’innovation » à long terme.
Conclusion
L’avantage compétitif de l’IA en entreprise évolue : il ne s’agit plus d’intégrer le dernier modèle, mais de pouvoir exploiter plusieurs modèles et agents avec des coûts maîtrisés et des limites de sécurité. Cela implique de renforcer les stacks d’ingénierie et de gouvernance : routage et publication, observabilité et gestion des coûts, droits d’accès aux outils et traçabilité doivent être considérés comme des essentiels de production au même titre que les modèles eux-mêmes.








