
Auteur : Phosphen
Compilation ; Gans 甘斯, Bagel预测市场观察
Ce homme a collecté toutes les données des 43 dernières années de tennis professionnel, les a entrées dans un modèle d’apprentissage automatique, puis n’a posé qu’une seule question : pouvez-vous prédire qui va gagner ?
Le modèle n’a répondu qu’un seul mot : oui.
Ensuite, il a prédit avec succès 99 victoires sur 116 matchs lors de l’Open d’Australie cette année, avec une précision de 85 % !
Ce sont des matchs que le modèle n’avait jamais vus lors de son entraînement, et il a réussi à prédire chaque match du champion final.

Tout cela avec un seul ordinateur portable, des données gratuites et du code open source, signé @theGreenCoding.
Je vais maintenant décomposer en détail ce projet qui transforme le plomb en or, depuis les données brutes jusqu’aux prédictions finales. Ce sera l’un des exemples les plus impressionnants de succès en IA et en prédiction que vous ayez jamais vus.
Point de départ : un dossier contenant 43 ans de données de tennis
L’histoire commence avec un ensemble de données considéré comme le « Saint Graal des données sportives ».
Cet ensemble couvre tous les matchs professionnels de l’ATP (Association of Tennis Professionals) de 1985 à 2024.
Points de break, doubles fautes, coups droits, revers, taille des joueurs, âge, classement, historique des confrontations, surface de jeu… Toutes les statistiques détaillées, chaque point suivi, ont été enregistrées par l’ATP.
Quarante-trois années de fichiers CSV, tous regroupés dans un seul dossier.
Lorsqu’il a ouvert l’ensemble complet, l’ordinateur a planté.
Mais il n’a pas abandonné. Sur les 95 491 matchs du dataset, il a calculé de nombreuses caractéristiques dérivées :
- Historique des confrontations entre les deux joueurs
- Différence d’âge, différence de taille
- Taux de victoire sur les 10, 25, 50, 100 derniers matchs
- Différence de pourcentage de points gagnés sur la première balle
- Différence de taux de sauvetage des balles de break
- Un système de notation ELO personnalisé, inspiré des échecs (point clé)
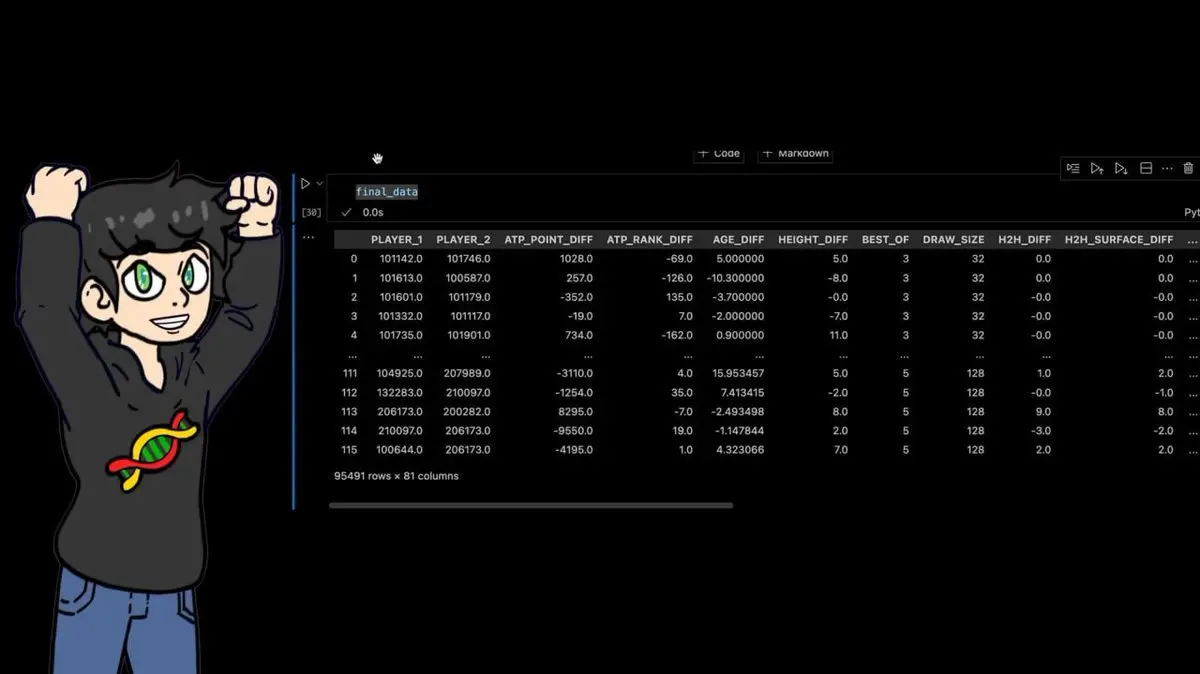
Au final, le dataset : 95 491 lignes × 81 colonnes.
Chaque match professionnel des quarante dernières années, avec des dizaines de caractéristiques calculées manuellement.
Deuxième étape : s’inspirer de l’algorithme du Titanic

Avant d’entrer les données dans un classificateur, il a décidé de comprendre en profondeur le fonctionnement de l’algorithme. Pour cela, il a écrit un arbre de décision à partir de zéro, avec numpy.
Le fonctionnement d’un arbre de décision ressemble à un jeu de devinettes — en posant une série de questions pour approcher la réponse.
Pour illustrer ce concept, il a choisi un dataset complètement différent : le Titanic.
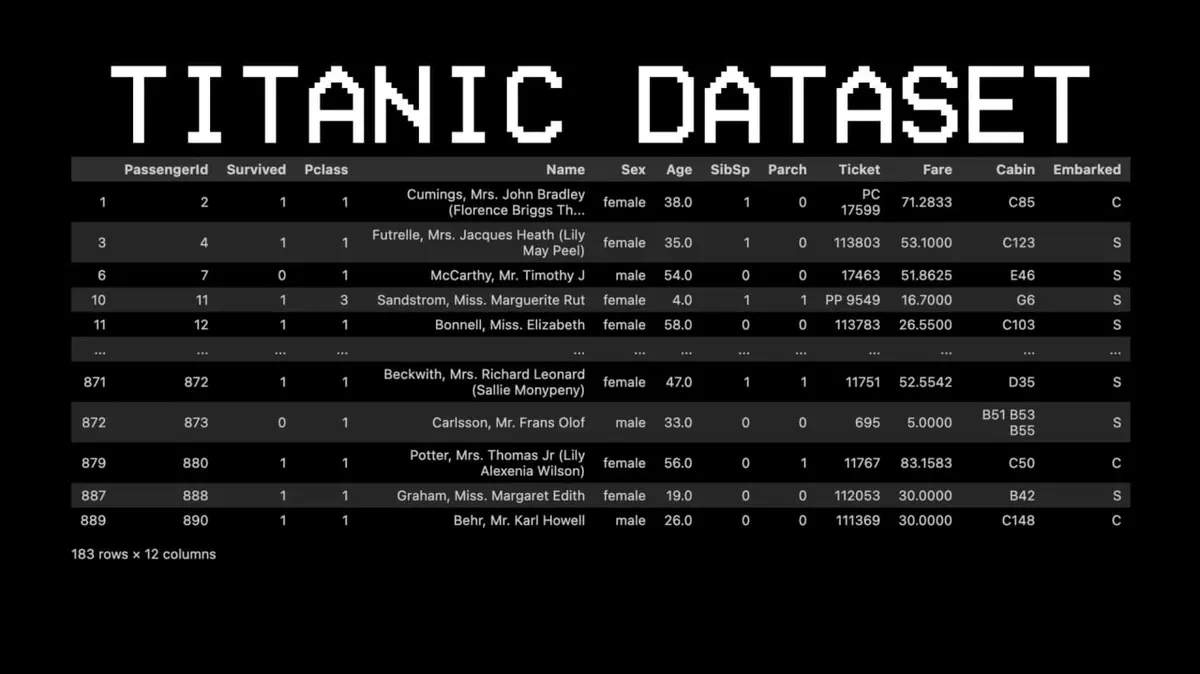
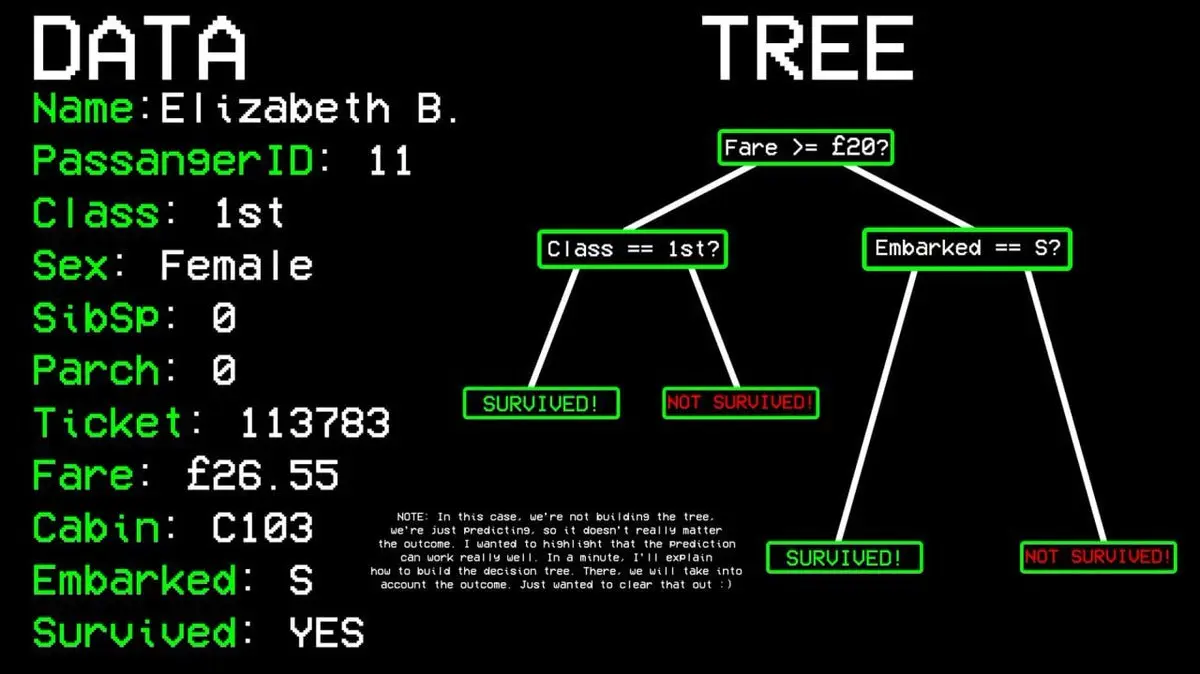
Exemple : le passager n°11 a-t-il survécu ?
- Question 1 : Était-il en première classe ? → Oui.
- Question 2 : Était-il une femme ? → Oui.
- Résultat : il a survécu.
Comment l’algorithme décide-t-il quelles questions poser ?
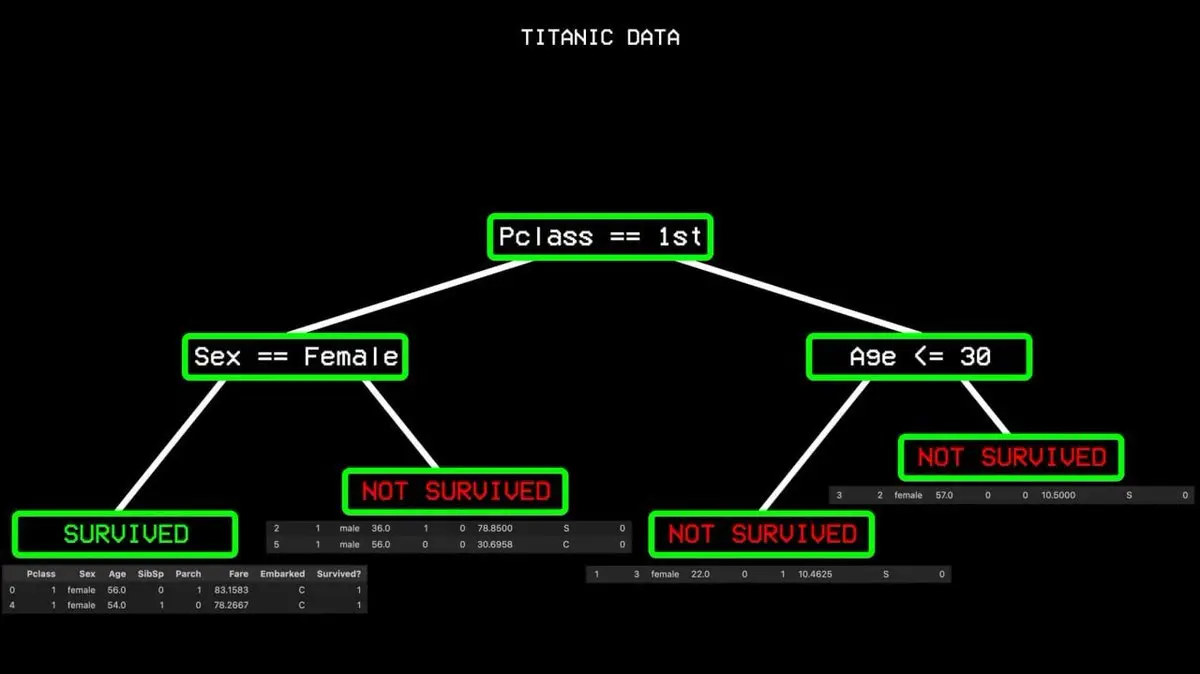
Il part de toutes les données, et cherche la variable qui permet de distinguer le mieux « survivant » et « non survivant ». Sur le Titanic, cette variable est le niveau de cabine. Les passagers en première classe d’un côté, les autres de l’autre.
Mais il y a aussi des cas difficiles : certains en première classe ont péri. L’algorithme continue alors à chercher la meilleure division suivante, par exemple le sexe. Les femmes en première classe ont toutes survécu, formant un « nœud pur », et la branche s’arrête là.
Ce processus est répété jusqu’à construire un arbre complet, couvrant toutes les situations.
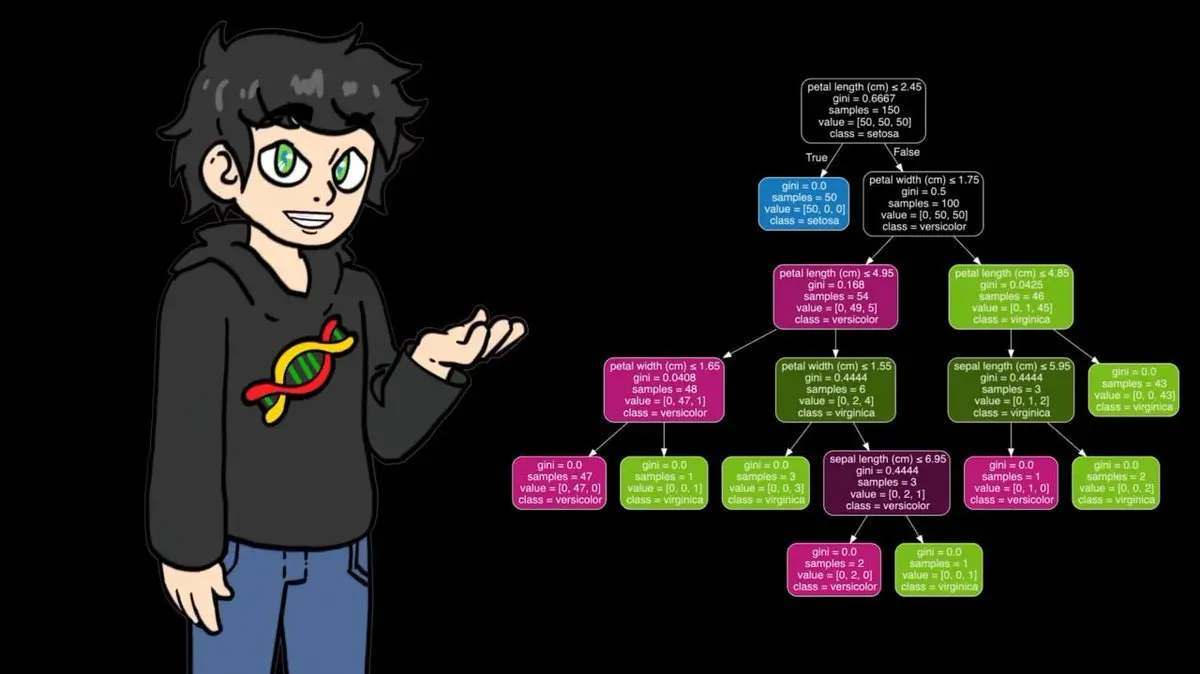
Sa version écrite à la main avec numpy fonctionne bien sur de petits datasets, mais sur 95 000 matchs de tennis, elle est trop lente. Il a donc utilisé la version optimisée de sklearn pour l’entraînement, qui est plus rapide tout en étant conceptuellement identique.
Troisième étape : identifier les variables clés pour la victoire
Avant d’entraîner le modèle, il a tracé une énorme matrice de diagrammes de dispersion (pairplot SNS) pour toutes les variables, afin de repérer celles qui distinguent clairement gagnants et perdants.

La plupart des caractéristiques sont du bruit. L’ID du joueur est inutile. La différence de taux de victoire montre quelques tendances, mais ce n’est pas suffisant pour une classification fiable.
Une seule variable se détache : la différence d’ELO (ELO_DIFF).
Les diagrammes de dispersion ELO_DIFF et ELO_SURFACE_DIFF montrent une séparation nette entre les deux classes, aucune autre caractéristique ne s’en approche.
Cette découverte a conduit à la construction de la partie la plus centrale du projet.
Quatrième étape : intégrer le système de notation ELO aux règles du tennis
ELO est une méthode d’évaluation du niveau technique d’un joueur, initialement utilisée aux échecs. Le champion mondial actuel, Magnus Carlsen, a un score de 2833.

Il a décidé d’appliquer ce système au tennis :
- Score initial de chaque joueur : 1500 points
- Gagner une partie : score augmente ; perdre : score diminue
Mécanisme clé : le gain ou la perte dépend de la différence de score avec l’adversaire. Battre un adversaire mieux classé rapporte plus, perdre contre un moins bien classé coûte plus.
Il a illustré cette formule avec la finale de Wimbledon 2023 : Carlos Alcaraz (score 2063) contre Novak Djokovic (score 2120). Alcaraz a remporté la victoire en revenant de l’arrière.

En appliquant la formule : Alcaraz +14 points, Djokovic -14 points.
Le calcul est simple, mais appliqué à 43 ans de données, il est d’une puissance impressionnante.
Cinquième étape : visualiser la domination des « trois grands »
Il a tracé la courbe ELO de Federer tout au long de sa carrière, de ses débuts à sa retraite, match après match.
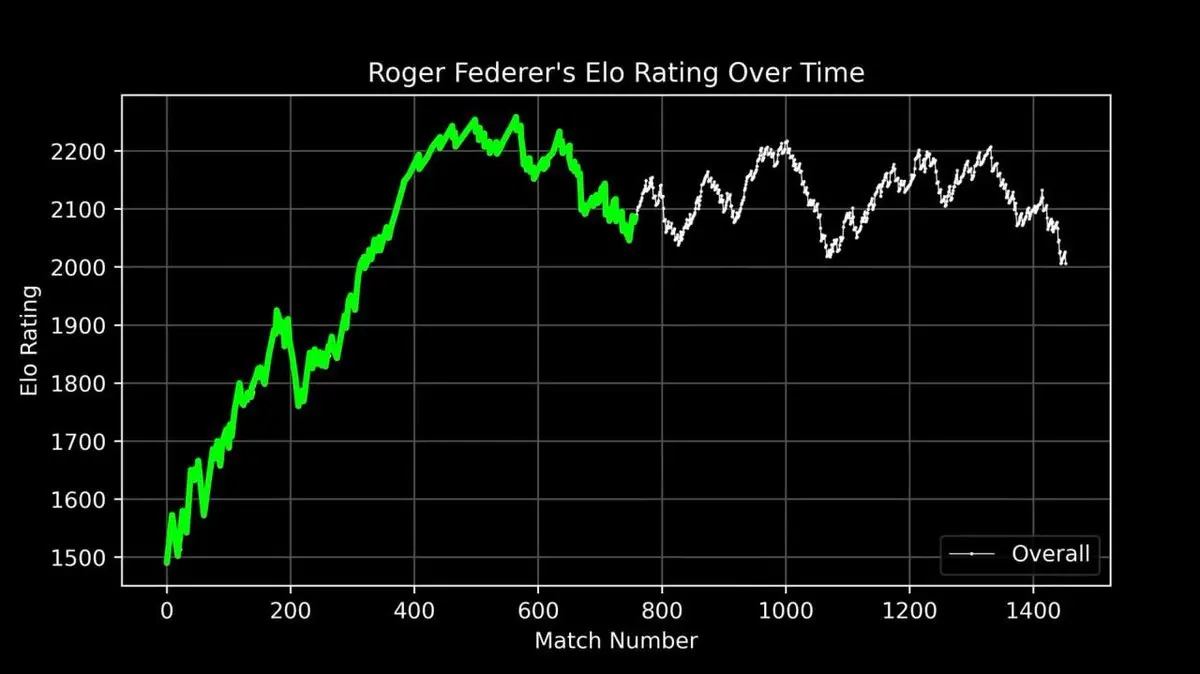
Cette courbe raconte une légende : montée rapide au début, domination absolue autour de la 400e rencontre, puis fluctuations en fin de carrière.
Mais ce qui est encore plus impressionnant, c’est de mettre Federer en comparaison avec tous les autres joueurs ATP depuis 1985 :
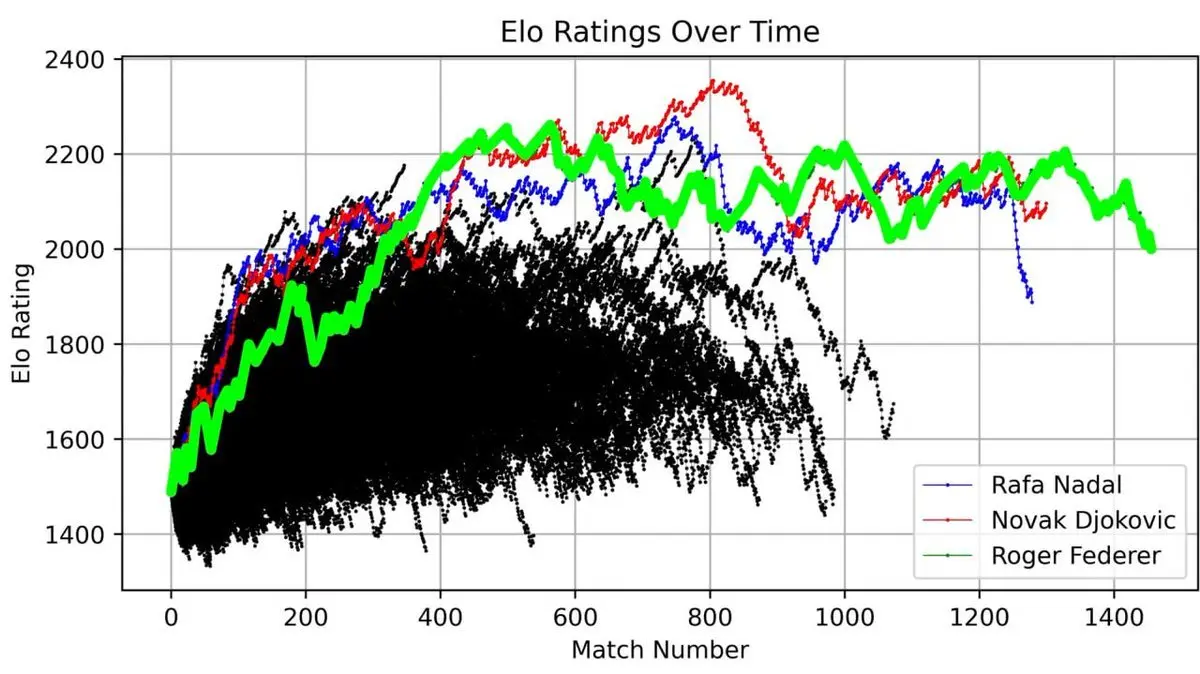
Trois courbes dominent, bien au-dessus des autres — Federer (vert), Nadal (bleu), Djokovic (rouge).
Les « trois grands du Grand Chelem » ne sont pas qu’un titre. En visualisant 40 ans de données, leur domination devient mathématiquement évidente.
Selon leur système ELO personnalisé, le numéro un mondial actuel est Jannik Sinner (2176 points), suivi de Djokovic (2096) et Alcaraz (2003).

Garder en mémoire que Sinner est en tête est crucial pour la suite.
Sixième étape : le terrain comme variable déterminante
La surface de jeu modifie radicalement la dynamique du tennis :
- Terre battue : lente, rebond élevé
- Gazon : rapide, rebond faible
- Dur : intermédiaire
Un joueur qui excelle sur une surface peut totalement échouer sur une autre.
Il a donc construit des scores ELO séparés pour chaque surface : terre, gazon, dur.
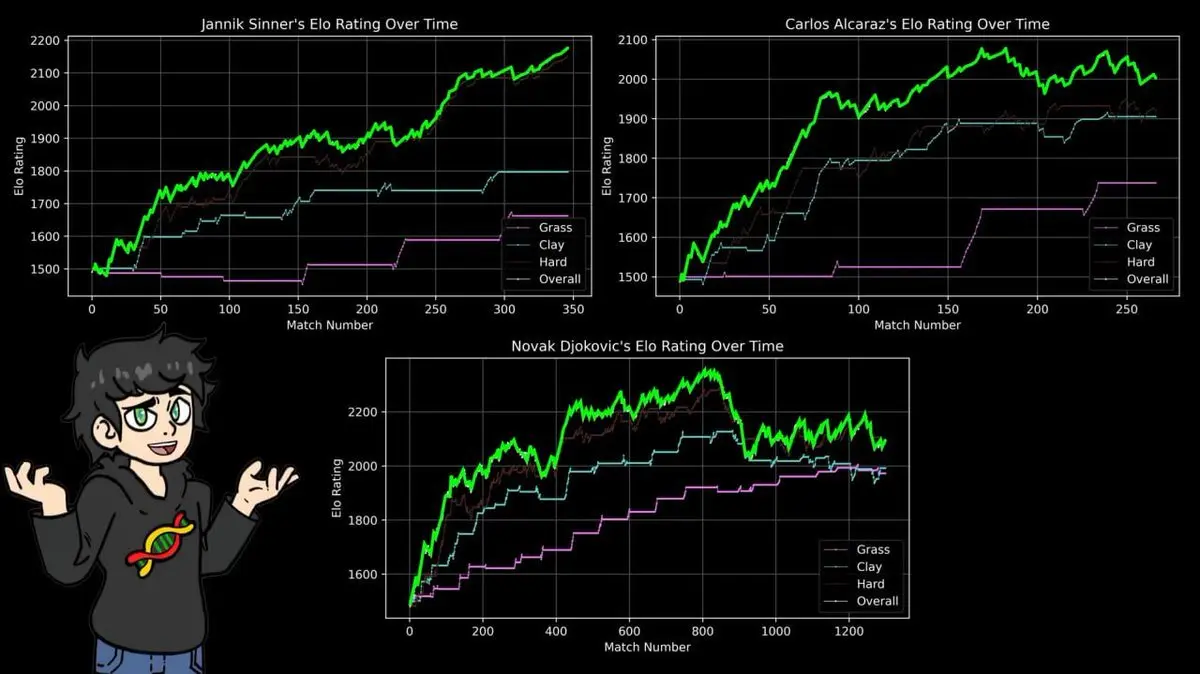
Les résultats confirment une évidence pour tous les fans : le score maximal de Nadal sur terre dépasse celui de Federer sur gazon, et celui de Djokovic sur dur, et dépasse tous les records historiques sur chaque surface.
14 titres de Roland-Garros, 112 victoires pour 4 défaites.
L’ELO ne se soucie pas de la narration ou de la renommée, il ne traite que des résultats. Et ses conclusions concordent parfaitement avec 40 ans de reportages sportifs.
Septième étape : plafonnement des performances
Une fois les données prêtes et le système ELO en place, il a commencé à entraîner un classificateur. Ce processus illustre parfaitement l’importance du choix de l’algorithme.
Arbre de décision : précision 74 %
Un seul arbre de décision sur l’ensemble complet atteint 74 % de précision. C’est correct — jusqu’à ce que l’on réalise qu’avec la différence d’ELO seule, on atteint déjà 72 %.
L’arbre n’apporte donc qu’une amélioration marginale par rapport à la simple utilisation de la différence d’ELO.
Forêt aléatoire (Random Forest) : précision 76 %
Le problème de l’arbre unique est la « haute variance » — il est trop sensible aux données d’entraînement. La solution standard est la forêt aléatoire : construire une centaine d’arbres, chacun entraîné sur un sous-ensemble aléatoire de données et de caractéristiques, puis voter en majorité.

94 arbres différents votent pour chaque match.

Le résultat : 76 %. Une amélioration, mais un plafond. Peu importe comment on ajuste, la précision ne dépasse pas 77 %.
Huitième étape : dépasser le plafond
Il a ensuite testé XGBoost — qu’il appelle « la version stéroïdée de la forêt aléatoire ».
Différence principale : la forêt aléatoire construit tous ses arbres en parallèle, puis fait la moyenne. XGBoost construit ses arbres en série, chaque nouvel arbre corrigeant les erreurs des précédents. Il intègre une régularisation pour éviter le surapprentissage, et limite la taille de chaque arbre.
Résultat : précision de 85 %.
C’est une avancée majeure par rapport au plafond de 76 %. Avec les mêmes données, les mêmes caractéristiques, la seule différence est l’algorithme.
XGBoost confirme que les trois caractéristiques les plus importantes sont : la différence d’ELO, la différence d’ELO spécifique à la surface, et le score ELO global. Ce système de notation, inspiré des échecs, s’avère le meilleur prédicteur parmi les 81 colonnes.
En comparaison, il a entraîné un réseau de neurones avec les mêmes données, atteignant 83 % de précision. Moins bon, mais pas si loin. Sur ce dataset, la méthode basée sur les arbres est la plus performante.
Neuvième étape : le moment décisif — l’Open d’Australie 2025
Tout ce qui précède a été entraîné avec des données jusqu’en décembre 2024.
L’Open d’Australie 2025, en janvier, n’était pas dans l’ensemble d’entraînement, ce qui en fait un test parfait : le modèle a-t-il compris la vraie règle du tennis, ou se contente-t-il de mémoriser les patterns historiques ?

Il a entré tout le tableau du tournoi dans le modèle, pour qu’il prévoie chaque match.
Résultat : sur 116 matchs, 99 prédictions correctes, seulement 17 erreurs. Précision de 85,3 %.
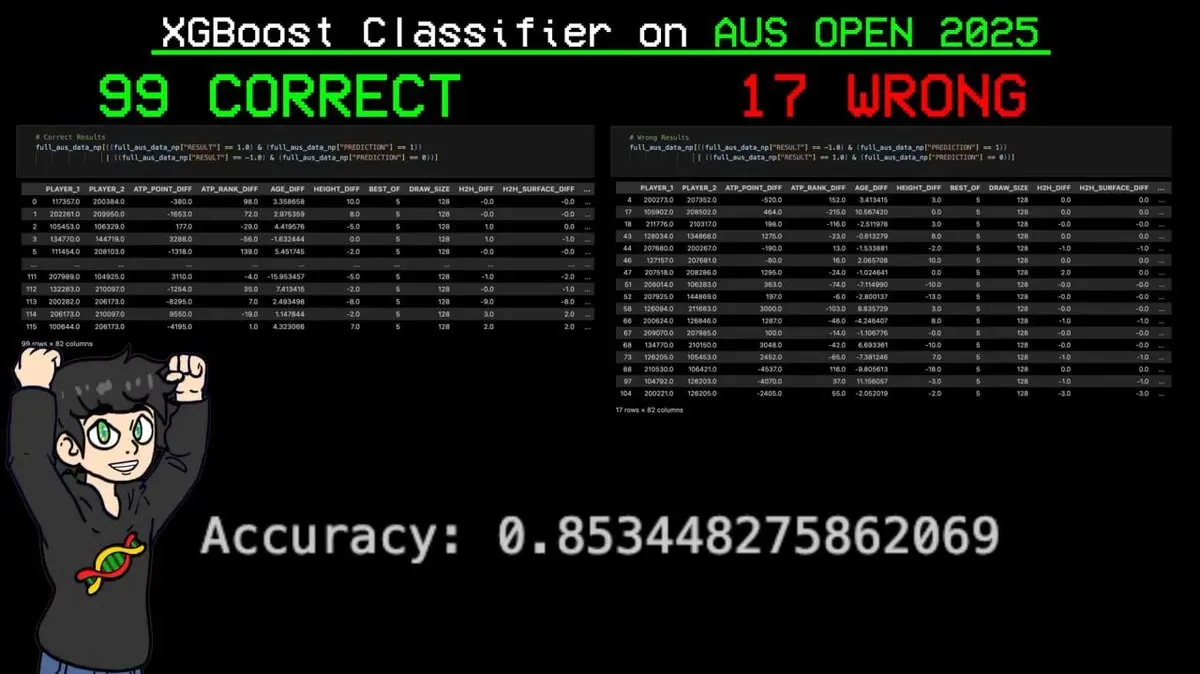
La prédiction la plus cruciale : le modèle a anticipé chaque victoire de Sinner (le joueur classé numéro un mondial par son système ELO) tout au long du tournoi.
Avant même que la balle ne touche le court, l’IA avait déjà prédit le champion du Grand Chelem.
Conclusion
Une personne, un seul ordinateur portable, sans données propriétaires, sans infrastructure coûteuse, sans équipe de recherche — et pourtant, elle a construit un modèle de prédiction du tennis professionnel avec une précision de 85 %, capable d’anticiper le champion avant le début du tournoi.
Les données de tennis sont disponibles sur GitHub, entièrement reproductibles.
Créer des miracles n’a jamais été aussi accessible qu’aujourd’hui.
La vraie différence ne réside pas dans les ressources, mais dans la volonté de faire.