Source : Wall Street Journal
Le 16 mars 2026, la conférence GTC 2026 de Nvidia a officiellement débuté, avec le fondateur et PDG Jensen Huang prononçant un discours principal.
Lors de cette conférence considérée comme « le pèlerinage annuel de l’industrie de l’IA », Jensen Huang a expliqué la transformation de Nvidia, passant d’une « société de puces » à une « société d’infrastructure et d’usines d’IA ». Face aux préoccupations du marché concernant la pérennité des performances et les perspectives de croissance, il a détaillé la logique commerciale sous-jacente qui stimule la croissance future — « l’économie des usines de tokens ».

Perspectives de performance extrêmement optimistes : « une demande d’au moins 1 000 milliards de dollars d’ici 2027 »
Au cours des deux dernières années, la demande mondiale en calcul pour l’IA a explosé de façon exponentielle. Avec l’évolution des grands modèles, passant de « perception » et « génération » à « raisonnement » et « exécution (tâches) », la consommation de puissance de calcul a fortement augmenté. Concernant le plafond des commandes et des revenus, très surveillé par le marché, Huang Huang a exprimé des attentes très optimistes.
Dans son discours, Huang Huang a déclaré franchement :
À cette époque l’année dernière, j’ai dit que nous avions une demande très fiable de 500 milliards de dollars, couvrant Blackwell et Rubin jusqu’en 2026. Maintenant, ici même, je vois une demande d’au moins 1 000 milliards de dollars d’ici 2027.

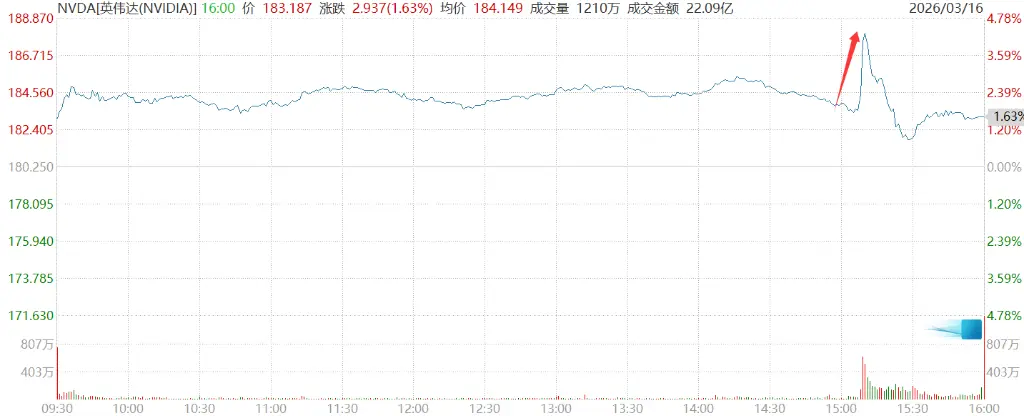
L’optimisme de Huang Huang concernant le trillion de dollars a temporairement fait grimper le cours de Nvidia de plus de 4,3 %.
De plus, il a ajouté à cette prévision :
Est-ce raisonnable ? C’est ce dont je vais parler. En réalité, nous serons même en situation de demande excédentaire. Je suis convaincu que la demande réelle en calcul sera bien plus élevée que cela.
Huang Huang a souligné que les systèmes Nvidia actuels ont déjà prouvé qu’ils sont la « infrastructure la moins coûteuse au monde ». La capacité de Nvidia à faire fonctionner presque tous les modèles d’IA dans tous les domaines permet à cette universalité d’utiliser pleinement cette demande d’un trillion de dollars, tout en assurant une longue durée de vie.
Actuellement, 60 % des activités de Nvidia proviennent des cinq plus grands fournisseurs de cloud ultra-massifs, tandis que les 40 % restants sont largement répartis dans les clouds souverains, les entreprises, l’industrie, la robotique et le edge computing.
Économie des usines de tokens : la performance par watt détermine la survie commerciale
Pour expliquer la rationalité de cette demande de 1 000 milliards de dollars, Huang Huang a présenté une nouvelle logique commerciale aux PDG du monde entier. Il a souligné que, à l’avenir, les centres de données ne seront plus de simples entrepôts de stockage, mais des « usines » produisant des tokens (unités fondamentales générées par l’IA).

Huang Huang insiste :
Chaque centre de données, chaque usine, par définition, est limité par l’électricité. Une usine de 1 GW (gigawatt) ne deviendra jamais 2 GW, c’est une loi physique et atomique. Avec une puissance fixe, celui qui a le meilleur débit par watt de token, aura les coûts de production les plus faibles.
Huang Huang divise les services d’IA futurs en plusieurs niveaux commerciaux :
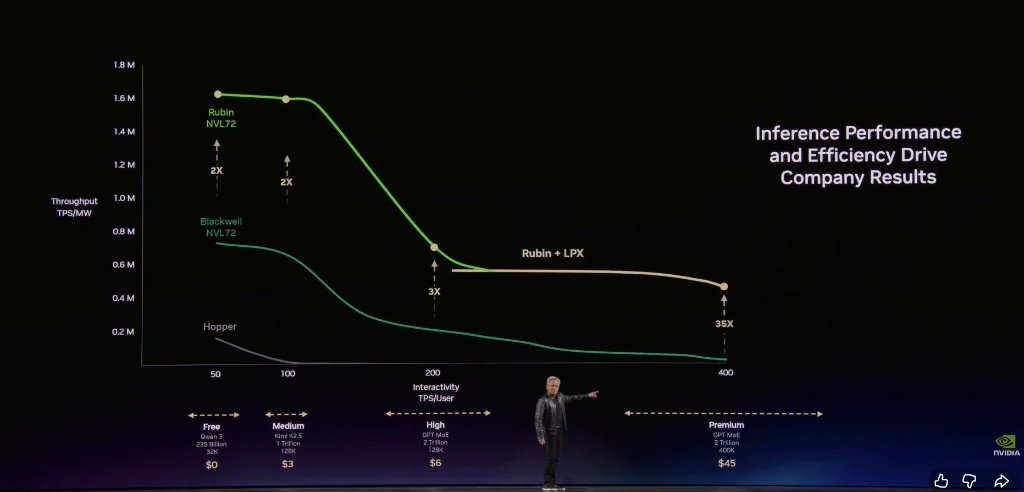
Niveau gratuit (haute capacité, faible vitesse)
Niveau intermédiaire (~3 dollars par million de tokens)
Niveau avancé (~6 dollars par million de tokens)
Niveau haute vitesse (~45 dollars par million de tokens)
Niveau ultra-haute vitesse (~150 dollars par million de tokens)
Il a indiqué qu’avec la croissance de la taille des modèles et l’allongement des contextes, l’IA deviendra plus intelligente, mais la vitesse de génération de tokens ralentira. Huang Huang explique :
Dans cette usine à tokens, votre débit et la vitesse de génération de tokens se traduiront directement en revenus précis pour l’année prochaine.
Huang Huang a souligné que l’architecture Nvidia permet à ses clients d’atteindre un débit très élevé dans le niveau gratuit, tout en améliorant la performance jusqu’à 35 fois dans le niveau de raisonnement à la valeur la plus élevée.
Vera Rubin en deux ans a accéléré de 350 fois, Groq comble le gap du raisonnement ultra-rapide
Sous la contrainte de limites physiques, Nvidia a présenté son système d’IA le plus complexe à ce jour, Vera Rubin. Huang Huang déclare :
Quand je parlais de Hopper, je montrais une puce, c’était mignon. Mais Vera Rubin, c’est tout le système. Dans ce système entièrement refroidi par liquide, éliminant complètement les câbles traditionnels, le rack qui prenait deux jours à installer il y a peu, ne prend plus que deux heures.
Huang Huang souligne qu’en concevant de manière extrême la synergie hardware-software, Vera Rubin a permis de réaliser des avancées spectaculaires dans un centre de données de 1 GW :
En seulement deux ans, nous avons porté la vitesse de génération de tokens de 22 millions à 700 millions, soit une croissance de 350 fois. La loi de Moore ne permet qu’une augmentation d’environ 1,5 fois sur la même période.
Pour résoudre le goulot d’étranglement du débit lors du raisonnement ultra-rapide (par exemple 1000 tokens/sec), Nvidia propose la solution intégrée de sa filiale acquise Groq : le raisonnement asymétrique séparé. Huang Huang explique :
Ces deux processeurs ont des caractéristiques très différentes. La puce Groq dispose de 500 Mo de SRAM, tandis qu’une puce Rubin possède 288 Go de mémoire.

Huang Huang indique qu’en utilisant le logiciel Dynamo, Nvidia confie la phase de « pré-remplissage (Pre-fill) » et de « décodage » très sensible à la latence à Vera Rubin, tandis que la phase de « décodage » à haute valeur, très sensible à la latence, est déléguée à Groq. Il recommande aussi une configuration pour les entreprises :
Si votre charge de travail consiste principalement en haute capacité, utilisez 100 % Vera Rubin ; si vous avez beaucoup de génération de tokens à haute valeur, consacrez 25 % de votre centre de données à Groq.
Selon des sources, la puce Groq LP30 fabriquée par Samsung est déjà en production de masse, avec une livraison prévue pour le troisième trimestre, tandis que le premier rack Vera Rubin fonctionne déjà sur le cloud Azure de Microsoft.
De plus, concernant la technologie de connectivité optique, Huang Huang a présenté le premier commutateur optique (CPO) Spectrum X en production de masse, apaisant la controverse sur la transition du cuivre à la fibre :
Nous avons besoin de plus de capacité en câbles en cuivre, en puces optiques, et en CPO.
Agent : fin du SaaS traditionnel, « salaire annuel + token » devient la norme à Silicon Valley
Outre les barrières matérielles, Huang Huang a consacré beaucoup de temps à la révolution logicielle et écologique de l’IA, notamment à l’explosion des Agents (intelligences artificielles autonomes).
Il décrit le projet open source OpenClaw comme « le projet open source le plus populaire de l’histoire humaine », affirmant qu’en quelques semaines, il a dépassé ce que Linux a accompli en 30 ans. Huang Huang déclare que, fondamentalement, OpenClaw est le « système d’exploitation » des agents informatiques.
Huang Huang affirme :
Chaque société SaaS deviendra une société AaaS (Agent-as-a-Service, intelligence artificielle en tant que service). Sans aucun doute, pour assurer la sécurité de ces agents capables d’accéder à des données sensibles et d’exécuter du code, Nvidia a lancé la référence d’entreprise NeMo Claw, intégrant un moteur de stratégie et un routeur de confidentialité.
Pour le grand public, cette révolution est également imminente. Huang Huang décrit la nouvelle forme de travail :
À l’avenir, chaque ingénieur de notre entreprise disposera d’un budget annuel en tokens. Leur salaire de base pourrait atteindre plusieurs centaines de milliers de dollars, et je leur consacrerai environ la moitié de ce montant en tokens, pour leur permettre d’augmenter leur productivité par un facteur 10. C’est déjà une nouvelle arme de recrutement à Silicon Valley : combien de tokens dans votre offre d’embauche ?
Dans son discours final, Huang Huang a également « leaké » la prochaine architecture de calcul Feynman, qui permettra pour la première fois une extension conjointe du cuivre et du CPO. Plus encore, Nvidia travaille sur un centre de calcul spatial, « Vera Rubin Space-1 », qui ouvre la voie à une extension de la puissance de calcul IA au-delà de la Terre.
Le discours intégral de Huang Huang à GTC 2026, traduit intégralement ci-dessous (avec assistance d’outils IA) :
Animateur : Bienvenue à Nvidia, avec le fondateur et PDG Jensen Huang.
Jensen Huang, fondateur et PDG :
Bienvenue à GTC. Je tiens à rappeler que c’est une conférence technologique. Voir autant de personnes faire la queue dès le matin, et voir chacun d’entre vous ici, me rend très heureux.
Lors de GTC, nous allons nous concentrer sur trois thèmes principaux : la technologie, la plateforme et l’écosystème. Nvidia dispose actuellement de trois grandes plateformes : la plateforme CUDA-X, la plateforme système, et notre toute nouvelle plateforme d’usines d’IA.
Avant de commencer officiellement, je tiens à remercier nos maîtres de cérémonie : Sarah Guo de Conviction, Alfred Lin de Sequoia Capital (le premier investisseur en capital-risque de Nvidia), et Gavin Baker, notre premier investisseur institutionnel principal. Ces trois personnes ont une vision profonde de la technologie et une influence considérable dans l’écosystème technologique. Bien sûr, je remercie aussi tous les invités que j’ai personnellement invités aujourd’hui. Merci à cette équipe étoilée.
Je remercie également toutes les entreprises présentes. Nvidia est une société de plateforme, avec une technologie, une plateforme et un écosystème riches. Les entreprises présentes représentent presque tous les acteurs du secteur de 100 000 milliards de dollars, avec 450 sociétés sponsorisant cet événement, que je tiens à saluer chaleureusement.
Ce GTC comprendra 1 000 forums techniques, 2 000 intervenants, couvrant chaque niveau de l’architecture en « cinq couches » de l’IA — des infrastructures de terrain, d’électricité et de centres de données, jusqu’aux puces, plateformes, modèles, et applications qui propulsent toute l’industrie.
CUDA : vingt ans d’accumulation technologique
Tout commence ici. Cette année marque le 20e anniversaire de CUDA.
Depuis vingt ans, nous nous consacrons au développement de cette architecture. CUDA est une invention révolutionnaire — la technologie SIMT (Single Instruction Multiple Threads) permet aux développeurs d’écrire des programmes en code scalaire, puis de les étendre à des applications multi-thread, avec une complexité de programmation bien inférieure à celle des architectures SIMD précédentes. Récemment, nous avons ajouté la fonction Tiles, facilitant la programmation des Tensor Cores, et toutes sortes de structures mathématiques essentielles à l’IA moderne. Aujourd’hui, CUDA dispose de milliers d’outils, compilateurs, frameworks et bibliothèques, avec des centaines de milliers de projets open source, profondément intégrés dans chaque écosystème technologique.
Ce graphique illustre la logique stratégique de Nvidia à 100 %, que je n’ai cessé de présenter depuis le début. La partie la plus difficile à réaliser, et la plus centrale, est la « capacité installée » en bas du graphique. Après vingt ans, nous avons accumulé des centaines de millions de GPU et de systèmes de calcul fonctionnant sous CUDA dans le monde entier.
Nos GPU couvrent toutes les plateformes cloud, desservant presque tous les fabricants d’ordinateurs et tous les secteurs. La masse critique de GPU installés est la force motrice de cette roue qui tourne de plus en plus vite. La capacité installée attire les développeurs, qui créent de nouvelles algorithmes et réalisent des percées, ces percées créent de nouveaux marchés, qui génèrent de nouvelles écosystèmes, attirant davantage d’entreprises, ce qui accroît la capacité installée — cette roue tourne et accélère sans cesse.
Le nombre de téléchargements de la bibliothèque Nvidia explose, avec une croissance rapide et continue. Cette roue permet à notre plateforme de calcul de supporter une multitude d’applications et de nouvelles avancées.
Plus important encore, elle confère à cette infrastructure une très longue durée de vie. La raison est évidente : les applications fonctionnant sur NVIDIA CUDA sont extrêmement riches, couvrant chaque étape du cycle de vie de l’IA, chaque plateforme de traitement de données, et divers solveurs scientifiques. Dès qu’un GPU Nvidia est installé, sa valeur d’usage est très élevée. C’est pourquoi, il y a six ans, le GPU Ampere que nous avons lancé voit son prix en cloud continuer à augmenter.
Tout cela repose sur la masse critique installée, la roue qui tourne à plein régime, et un écosystème de développeurs très étendu. Ces facteurs, combinés à nos mises à jour logicielles continues, font que le coût de calcul diminue constamment. La puissance de calcul accélérée améliore considérablement la performance des applications, et en maintenant et en faisant évoluer nos logiciels sur le long terme, nos utilisateurs bénéficient non seulement d’un saut de performance initial, mais aussi d’une baisse continue du coût de calcul. Nous sommes prêts à soutenir à long terme chaque GPU Nvidia dans le monde, car leur architecture est totalement compatible.
Nous faisons cela parce que la masse critique installée est si grande — chaque nouvelle optimisation profite à des millions d’utilisateurs. Cette dynamique permet à l’architecture Nvidia d’étendre sa couverture, de croître rapidement, et de faire baisser le coût du calcul, stimulant ainsi une nouvelle croissance. CUDA en est le cœur.
De GeForce à CUDA : vingt-cinq ans d’évolution
Notre voyage avec CUDA a en réalité commencé il y a vingt-cinq ans.
GeForce — je suis sûr que beaucoup d’entre vous ont grandi avec GeForce. GeForce est le projet de marketing le plus réussi de Nvidia. Nous avons commencé à former nos futurs clients bien avant qu’ils ne puissent acheter nos produits — ce sont les parents de votre génération qui sont devenus nos premiers utilisateurs, achetant nos produits année après année, jusqu’à ce que vous deveniez des informaticiens exceptionnels, nos véritables clients et développeurs.
C’est la base que GeForce a posée il y a vingt-cinq ans. Il y a vingt-cinq ans, nous avons inventé le shader programmable — une invention évidente mais profondément significative, qui a permis à l’accélérateur d’être programmable, et qui a été la toute première accélération programmable au monde, le pixel shader. Cinq ans plus tard, nous avons créé CUDA — l’un de nos investissements les plus importants. À l’époque, l’entreprise disposait de ressources limitées, mais nous avons mis la majorité de nos profits dans cette vision, pour étendre CUDA de GeForce à chaque ordinateur. Notre conviction était forte, car nous croyions en son potentiel. Malgré les difficultés initiales, nous avons maintenu cette foi pendant 13 générations, vingt ans, et aujourd’hui CUDA est omniprésent.
Ce shader a lancé la révolution GeForce. Et il y a environ huit ans, nous avons lancé RTX — une refonte complète de l’architecture pour l’ère moderne de la visualisation informatique. GeForce a permis de diffuser CUDA dans le monde entier, ce qui a permis à des chercheurs comme Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton, Andrew Ng, de découvrir que le GPU pouvait devenir un accélérateur puissant pour l’apprentissage profond, déclenchant la grande explosion de l’IA il y a dix ans.
Il y a dix ans, nous avons décidé de fusionner le shader programmable avec deux idées innovantes : d’une part, le ray tracing matériel (Ray Tracing), une technologie très difficile ; d’autre part, une vision avant-gardiste, que nous avions anticipée il y a environ dix ans — celle que l’IA allait transformer radicalement la visualisation informatique. Tout comme GeForce a apporté l’IA au grand public, l’IA va aujourd’hui transformer la façon dont la visualisation informatique est réalisée.
Aujourd’hui, je vais vous présenter l’avenir. La prochaine génération de technologie graphique, que nous appelons Neural Rendering — une fusion profonde entre 3D et IA. Voici DLSS 5, regardez.
Rendu neuronal : la fusion entre données structurées et IA générative
N’est-ce pas époustouflant ? La visualisation informatique renaît.
Que faisons-nous ? Nous combinons la modélisation 3D contrôlable (la base de la réalité virtuelle) avec ses données structurées, puis intégrons l’IA générative et le calcul probabiliste. L’un est déterministe, l’autre probabiliste mais hautement réaliste — nous fusionnons ces deux concepts, en utilisant les données structurées pour une précision contrôlée, tout en générant en temps réel. Au final, le contenu est à la fois magnifique, impressionnant, et entièrement contrôlable.
L’intégration de données structurées et d’IA générative sera une constante dans de nombreux secteurs. Les données structurées sont la base de l’IA fiable.
Plateforme d’accélération pour données structurées et non structurées
Je vais maintenant vous montrer un schéma d’architecture technologique.
Les données structurées — que vous connaissez sous le nom de SQL, Spark, Pandas, Velox, ainsi que des plateformes clés comme Snowflake, Databricks, Amazon EMR, Azure Fabric, Google BigQuery — traitent toutes des Data Frames. Ces Data Frames ressemblent à d’immenses tableurs, contenant toutes les informations du monde des affaires, et constituent la vérité fondamentale (Ground Truth) pour l’entreprise.
À l’ère de l’IA, il faut que l’IA utilise ces données structurées, avec une accélération extrême. Autrefois, accélérer le traitement des données structurées visait à rendre l’entreprise plus efficace. À l’avenir, l’IA utilisera ces structures à une vitesse bien supérieure à celle de l’humain, et les agents IA feront massivement appel à ces bases de données structurées.
Pour les données non structurées, les bases vectorielles, PDF, vidéos, audios représentent la majorité des données mondiales — environ 90 % des données générées chaque année sont non structurées. Autrefois, ces données étaient presque inutilisables : on les lisait, on les stockait dans des systèmes de fichiers, et c’était tout. Impossible de faire des requêtes ou de rechercher efficacement, car ces données manquent d’index simples, et il faut comprendre leur sens et leur contexte. Aujourd’hui, l’IA peut faire cela — grâce à la perception multimodale et à la compréhension, l’IA peut lire un PDF, en comprendre le sens, et l’intégrer dans une structure plus grande et exploitable.
Nvidia a créé deux bibliothèques fondamentales pour cela :
- cuDF : pour accélérer le traitement des Data Frames et des données structurées
- cuVS : pour le stockage vectoriel, la sémantique, et les données non structurées IA
Ces deux plateformes deviendront parmi les plus importantes de demain.
Aujourd’hui, nous annonçons des collaborations avec plusieurs entreprises. IBM — inventeur du langage SQL — utilisera cuDF pour accélérer sa plateforme WatsonX Data. Dell a co-créé avec nous la plateforme de données IA Dell, intégrant cuDF et cuVS, avec des gains de performance importants dans des projets concrets chez NTT Data. Google Cloud accélère non seulement Vertex AI, mais aussi BigQuery, et a collaboré avec Snapchat pour réduire ses coûts de calcul de près de 80 %.
Les bénéfices du calcul accéléré sont triples : vitesse, échelle, coût. Cela s’inscrit dans la logique de la loi de Moore — en accélérant le calcul, on réalise des progrès de performance, tout en optimisant en permanence les algorithmes, pour que tout le monde profite d’une baisse continue des coûts. En améliorant la vitesse, on augmente la performance, et en maintenant cette performance tout en réduisant le coût, on stimule une croissance nouvelle. CUDA en est le cœur.
De GeForce à CUDA : vingt-cinq ans d’évolution
Notre parcours avec CUDA a en réalité commencé il y a vingt-cinq ans.
GeForce — je suis sûr que beaucoup d’entre vous ont grandi avec GeForce. GeForce est le projet de marketing le plus réussi de Nvidia. Nous avons commencé à former nos futurs clients bien avant qu’ils puissent acheter nos produits — ce sont les parents de votre génération qui sont devenus nos premiers utilisateurs, achetant nos produits année après année, jusqu’à ce que vous deveniez des informaticiens exceptionnels, nos véritables clients et développeurs.
C’est la base que GeForce a posée il y a vingt-cinq ans. Il y a vingt-cinq ans, nous avons inventé le shader programmable — une invention évidente mais profondément significative, qui a permis à l’accélérateur d’être programmable, et qui a été la toute première accélération programmable au monde, le pixel shader. Cinq ans plus tard, nous avons créé CUDA — l’un de nos investissements les plus importants. À l’époque, l’entreprise disposait de ressources limitées, mais nous avons mis la majorité de nos profits dans cette vision, pour étendre CUDA de GeForce à chaque ordinateur. Notre conviction était forte, car nous croyions en son potentiel. Malgré les difficultés initiales, nous avons maintenu cette foi pendant 13 générations, vingt ans, et aujourd’hui CUDA est omniprésent.
Ce shader a lancé la révolution GeForce. Et il y a environ huit ans, nous avons lancé RTX — une refonte complète de l’architecture pour l’ère moderne de la visualisation informatique. GeForce a permis de diffuser CUDA dans le monde entier, ce qui a permis à des chercheurs comme Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton, Andrew Ng, de découvrir que le GPU pouvait devenir un accélérateur puissant pour l’apprentissage profond, déclenchant la grande explosion de l’IA il y a dix ans.
Il y a dix ans, nous avons décidé de fusionner le shader programmable avec deux idées innovantes : d’une part, le ray tracing matériel (Ray Tracing), une technologie très difficile ; d’autre part, une vision avant-gardiste, que nous avions anticipée il y a environ dix ans — celle que l’IA allait transformer radicalement la visualisation informatique. Tout comme GeForce a apporté l’IA au grand public, l’IA va aujourd’hui transformer la façon dont la visualisation informatique est réalisée.
Aujourd’hui, je vais vous présenter l’avenir. La prochaine génération de technologie graphique, que nous appelons Neural Rendering — une fusion profonde entre 3D et IA. Voici DLSS 5, regardez.
Rendu neuronal : la fusion entre données structurées et IA générative
N’est-ce pas époustouflant ? La visualisation informatique renaît.
Que faisons-nous ? Nous combinons la modélisation 3D contrôlable (la base du monde virtuel) avec ses données structurées, puis intégrons l’IA générative et le calcul probabiliste. L’un est déterministe, l’autre probabiliste mais hautement réaliste — nous fusionnons ces deux concepts, en utilisant les données structurées pour une précision contrôlée, tout en générant en temps réel. Au final, le contenu est à la fois magnifique, impressionnant, et entièrement contrôlable.
L’intégration de données structurées et d’IA générative sera une constante dans de nombreux secteurs. Les données structurées sont la base de l’IA fiable.
Plateforme d’accélération pour données structurées et non structurées
Je vais maintenant vous montrer un schéma d’architecture technologique.
Les données structurées — que vous connaissez sous le nom de SQL, Spark, Pandas, Velox, ainsi que des plateformes clés comme Snowflake, Databricks, Amazon EMR, Azure Fabric, Google BigQuery — traitent toutes des Data Frames. Ces Data Frames ressemblent à d’immenses tableurs, contenant toutes les informations du monde des affaires, et constituent la vérité fondamentale (Ground Truth) pour l’entreprise.
À l’ère de l’IA, il faut que l’IA utilise ces données structurées, avec une accélération extrême. Autrefois, accélérer le traitement des données structurées visait à rendre l’entreprise plus efficace. À l’avenir, l’IA utilisera ces structures à une vitesse bien supérieure à celle de l’humain, et les agents IA feront massivement appel à ces bases de données structurées.
Pour les données non structurées, les bases vectorielles, PDF, vidéos, audios représentent la majorité des données mondiales — environ 90 % des données générées chaque année sont non structurées. Autrefois, ces données étaient presque inutilisables : on les lisait, on les stockait dans des systèmes de fichiers, et c’était tout. Impossible de faire des requêtes ou de rechercher efficacement, car ces données manquent d’index simples, et il faut comprendre leur sens et leur contexte. Aujourd’hui, l’IA peut faire cela — grâce à la perception multimodale et à la compréhension, l’IA peut lire un PDF, en comprendre le sens, et l’intégrer dans une structure plus grande et exploitable.
Nvidia a créé deux bibliothèques fondamentales pour cela :
- cuDF : pour accélérer le traitement des Data Frames et des données structurées
- cuVS : pour le stockage vectoriel, la sémantique, et les données non structurées IA
Ces deux plateformes deviendront parmi les plus importantes de demain.
Aujourd’hui, nous annonçons des collaborations avec plusieurs entreprises. IBM — inventeur du langage SQL — utilisera cuDF pour accélérer sa plateforme WatsonX Data. Dell a co-créé avec nous la plateforme de données IA Dell, intégrant cuDF et cuVS, avec des gains de performance importants dans des projets concrets chez NTT Data. Google Cloud accélère non seulement Vertex AI, mais aussi BigQuery, et a collaboré avec Snapchat pour réduire ses coûts de calcul de près de 80 %.
Les bénéfices du calcul accéléré sont triples : vitesse, échelle, coût. Cela s’inscrit dans la logique de la loi de Moore — en accélérant le calcul, on réalise des progrès de performance, tout en optimisant en permanence les algorithmes, pour que tout le monde profite d’une baisse continue des coûts. En améliorant la vitesse, on augmente la performance, et en maintenant cette performance tout en réduisant le coût, on stimule une croissance nouvelle. CUDA en est le cœur.
De GeForce à CUDA : vingt-cinq ans d’évolution
Notre parcours avec CUDA a en réalité commencé il y a vingt-cinq ans.
GeForce — je suis sûr que beaucoup d’entre vous ont grandi avec GeForce. GeForce est le projet de marketing le plus réussi de Nvidia. Nous avons commencé à former nos futurs clients bien avant qu’ils ne puissent acheter nos produits — ce sont les parents de votre génération qui sont devenus nos premiers utilisateurs, achetant nos produits année après année, jusqu’à ce que vous deveniez des informaticiens exceptionnels, nos véritables clients et développeurs.
C’est la base que GeForce a posée il y a vingt-cinq ans. Il y a vingt-cinq ans, nous avons inventé le shader programmable — une invention évidente mais profondément significative, qui a permis à l’accélérateur d’être programmable, et qui a été la toute première accélération programmable au monde, le pixel shader. Cinq ans plus tard, nous avons créé CUDA — l’un de nos investissements les plus importants. À l’époque, l’entreprise disposait de ressources limitées, mais nous avons mis la majorité de nos profits dans cette vision, pour étendre CUDA de GeForce à chaque ordinateur. Notre conviction était forte, car nous croyions en son potentiel. Malgré les difficultés initiales, nous avons maintenu cette foi pendant 13 générations, vingt ans, et aujourd’hui CUDA est omniprésent.
Ce shader a lancé la révolution GeForce. Et il y a environ huit ans, nous avons lancé RTX — une refonte complète de l’architecture pour l’ère moderne de la visualisation informatique. GeForce a permis de diffuser CUDA dans le monde entier, ce qui a permis à des chercheurs comme Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton, Andrew Ng, de découvrir que le GPU pouvait devenir un accélérateur puissant pour l’apprentissage profond, déclenchant la grande explosion de l’IA il y a dix ans.
Il y a dix ans, nous avons décidé de fusionner le shader programmable avec deux idées innovantes : d’une part, le ray tracing matériel (Ray Tracing), une technologie très difficile ; d’autre part, une vision avant-gardiste, que nous avions anticipée il y a environ dix ans — celle que l’IA allait transformer radicalement la visualisation informatique. Tout comme GeForce a apporté l’IA au grand public, l’IA va aujourd’hui transformer la façon dont la visualisation informatique est réalisée.
Aujourd’hui, je vais vous présenter l’avenir. La prochaine génération de technologie graphique, que nous appelons Neural Rendering — une fusion profonde entre 3D et IA. Voici DLSS 5, regardez.
Rendu neuronal : la fusion entre données structurées et IA générative
N’est-ce pas époustouflant ? La visualisation informatique renaît.
Que faisons-nous ? Nous combinons la modélisation 3D contrôlable (la base du monde virtuel) avec ses données structurées, puis intégrons l’IA générative et le calcul probabiliste. L’un est déterministe, l’autre probabiliste mais hautement réaliste — nous fusionnons ces deux concepts, en utilisant les données structurées pour une précision contrôlée, tout en générant en temps réel. Au final, le contenu est à la fois magnifique, impressionnant, et entièrement contrôlable.
L’intégration de données structurées et d’IA générative sera une constante dans de nombreux secteurs. Les données structurées sont la base de l’IA fiable.
Plateforme d’accélération pour données structurées et non structurées
Je vais maintenant vous montrer un schéma d’architecture technologique.
Les données structurées — que vous connaissez sous le nom de SQL, Spark, Pandas, Velox, ainsi que des plateformes clés comme Snowflake, Databricks, Amazon EMR, Azure Fabric, Google BigQuery — traitent toutes des Data Frames. Ces Data Frames ressemblent à d’immenses tableurs, contenant toutes les informations du monde des affaires, et constituent la vérité fondamentale (Ground Truth) pour l’entreprise.
À l’ère de l’IA, il faut que l’IA utilise ces données structurées, avec une accélération extrême. Autrefois, accélérer le traitement des données structurées visait à rendre l’entreprise plus efficace. À l’avenir, l’IA utilisera ces structures à une vitesse bien supérieure à celle de l’humain, et les agents IA feront massivement appel à ces bases de données structurées.
Pour les données non structurées, les bases vectorielles, PDF, vidéos, audios représentent la majorité des données mondiales — environ 90 % des données générées chaque année sont non structurées. Autrefois, ces données étaient presque inutilisables : on les lisait, on les stockait dans des systèmes de fichiers, et c’était tout. Impossible de faire des requêtes ou de rechercher efficacement, car ces données manquent d’index simples, et il faut comprendre leur sens et leur contexte. Aujourd’hui, l’IA peut faire cela — grâce à la perception multimodale et à la compréhension, l’IA peut lire un PDF, en comprendre le sens, et l’intégrer dans une structure plus grande et exploitable.
Nvidia a créé deux bibliothèques fondamentales pour cela :
- cuDF : pour accélérer le traitement des Data Frames et des données structurées
- cuVS : pour le stockage vectoriel, la sémantique, et les données non structurées IA
Ces deux plateformes deviendront parmi les plus importantes de demain.
Aujourd’hui, nous annonçons des collaborations avec plusieurs entreprises. IBM — inventeur du langage SQL — utilisera cuDF pour accélérer sa plateforme WatsonX Data. Dell a co-créé avec nous la plateforme de données IA Dell, intégrant cuDF et cuVS, avec des gains de performance importants dans des projets concrets chez NTT Data. Google Cloud accélère non seulement Vertex AI, mais aussi BigQuery, et a collaboré avec Snapchat pour réduire ses coûts de calcul de près de 80 %.
Les bénéfices du calcul accéléré sont triples : vitesse, échelle, coût. Cela s’inscrit dans la logique de la loi de Moore — en accélérant le calcul, on réalise des progrès de performance, tout en optimisant en permanence les algorithmes, pour que tout le monde profite d’une baisse continue des coûts. En améliorant la vitesse, on augmente la performance, et en maintenant cette performance tout en réduisant le coût, on stimule une croissance nouvelle. CUDA en est le cœur.
De GeForce à CUDA : vingt-cinq ans d’évolution
Notre parcours avec CUDA a en réalité commencé il y a vingt-cinq ans.
GeForce — je suis sûr que beaucoup d’entre vous ont grandi avec GeForce. GeForce est le projet de marketing le plus réussi de Nvidia. Nous avons commencé à former nos futurs clients bien avant qu’ils ne puissent acheter nos produits — ce sont les parents de votre génération qui sont devenus nos premiers utilisateurs, achetant nos produits année après année, jusqu’à ce que vous deveniez des informaticiens exceptionnels, nos véritables clients et développeurs.
C’est la base que GeForce a posée il y a vingt-cinq ans. Il y a vingt-cinq ans, nous avons inventé le shader programmable — une invention évidente mais profondément significative, qui a permis à l’accélérateur d’être programmable, et qui a été la toute première accélération programmable au monde, le pixel shader. Cinq ans plus tard, nous avons créé CUDA — l’un de nos investissements les plus importants. À l’époque, l’entreprise disposait de ressources limitées, mais nous avons mis la majorité de nos profits dans cette vision, pour étendre CUDA de GeForce à chaque ordinateur. Notre conviction était forte, car nous croyions en son potentiel. Malgré les difficultés initiales, nous avons maintenu cette foi pendant 13 générations, vingt ans, et aujourd’hui CUDA est omniprésent.
Ce shader a lancé la révolution GeForce. Et il y a environ huit ans, nous avons lancé RTX — une refonte complète de l’architecture pour l’ère moderne de la visualisation informatique. GeForce a permis de diffuser CUDA dans le monde entier, ce qui a permis à des chercheurs comme Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton, Andrew Ng, de découvrir que le GPU pouvait devenir un accélérateur puissant pour l’apprentissage profond, déclenchant la grande explosion de l’IA il y a dix ans.
Il y a dix ans, nous avons décidé de fusionner le shader programmable avec deux idées innovantes : d’une part, le ray tracing matériel (Ray Tracing), une technologie très difficile ; d’autre part, une vision avant-gardiste, que nous avions anticipée il y a environ dix ans — celle que l’IA allait transformer radicalement la visualisation informatique. Tout comme GeForce a apporté l’IA au grand public, l’IA va aujourd’hui transformer la façon dont la visualisation informatique est réalisée.
Aujourd’hui, je vais vous présenter l’avenir. La prochaine génération de technologie graphique, que nous appelons Neural Rendering — une fusion profonde entre 3D et IA. Voici DLSS 5, regardez.
Rendu neuronal : la fusion entre données structurées et IA générative
N’est-ce pas époustouflant ? La visualisation informatique renaît.
Que faisons-nous ? Nous combinons la modélisation 3D contrôlable (la base du monde virtuel) avec ses données structurées, puis intégrons l’IA générative et le calcul probabiliste. L’un est déterministe, l’autre probabiliste mais hautement réaliste — nous fusionnons ces deux concepts, en utilisant les données structurées pour une précision contrôlée, tout en générant en temps réel. Au final, le contenu est à la fois magnifique, impressionnant, et entièrement contrôlable.
L’intégration de données structurées et d’IA générative sera une constante dans de nombreux secteurs. Les données structurées sont la base de l’IA fiable.
Plateforme d’accélération pour données structurées et non structurées
Je vais maintenant vous montrer un schéma d’architecture technologique.
Les données structurées — que vous connaissez sous le nom de SQL, Spark, Pandas, Velox, ainsi que des plateformes clés comme Snowflake, Databricks, Amazon EMR, Azure Fabric, Google BigQuery — traitent toutes des Data Frames. Ces Data Frames ressemblent à d’immenses tableurs, contenant toutes les informations du monde des affaires, et constituent la vérité fondamentale (Ground Truth) pour l’entreprise.
À l’ère de l’IA, il faut que l’IA utilise ces données structurées, avec une accélération extrême. Autrefois, accélérer le traitement des données structurées visait à rendre l’entreprise plus efficace. À l’avenir, l’IA utilisera ces structures à une vitesse bien supérieure à celle de l’humain, et les
