
Автор: Phosphen
Перевод: Gans Ганс, наблюдатель рынка Bagel прогнозов
Этот человек собрал данные всех профессиональных теннисных матчей за последние 43 года, загрузил их в модель машинного обучения и задал себе один вопрос: сможешь ли ты предсказать победителя?
Модель ответила всего одним словом: да.
Затем, на этом году Australian Open, она правильно предсказала 99 из 116 матчей, точность составила 85%!
Это были матчи, которые модель никогда ранее не видела во время обучения, и она смогла предсказать победителя даже в финальных матчах, включая победу чемпиона.

Все это было сделано всего одним ноутбуком, с использованием бесплатных данных и открытого кода, созданного @theGreenCoding.
Далее я подробно разберу этот проект, превращающий данные в золото, — от исходных данных до успешных прогнозов. Это будет один из самых впечатляющих примеров успеха AI и предсказаний.
Начало: папка с данными по теннису за 43 года
История начинается с набора данных, который можно назвать «святым Граалем спортивных данных».
Этот набор охватывает все профессиональные матчи ATP (Ассоциация профессионального тенниса) с 1985 по 2024 год.
Данные включают брейк-пойнты, двойные ошибки, удары с форхенда и бэкенда, рост и возраст игроков, их рейтинги, историю личных встреч, тип покрытия корта… Вся статистика по каждому очку, которая когда-либо собиралась ATP.
Все CSV-файлы за сорок лет — в одной папке.
Когда он открыл полный набор данных, его компьютер сразу завис.
Но он не сдался. Для 95 491 матча он дополнительно вычислил множество производных признаков:
- История личных встреч двух игроков
- Разница в возрасте и росте
- Процент побед за последние 10, 25, 50, 100 матчей
- Разница в проценте очков с первой подачи
- Разница в спасённых брейк-пойнтах
- Собственная система оценки ELO, заимствованная из шахмат (ключевой момент)
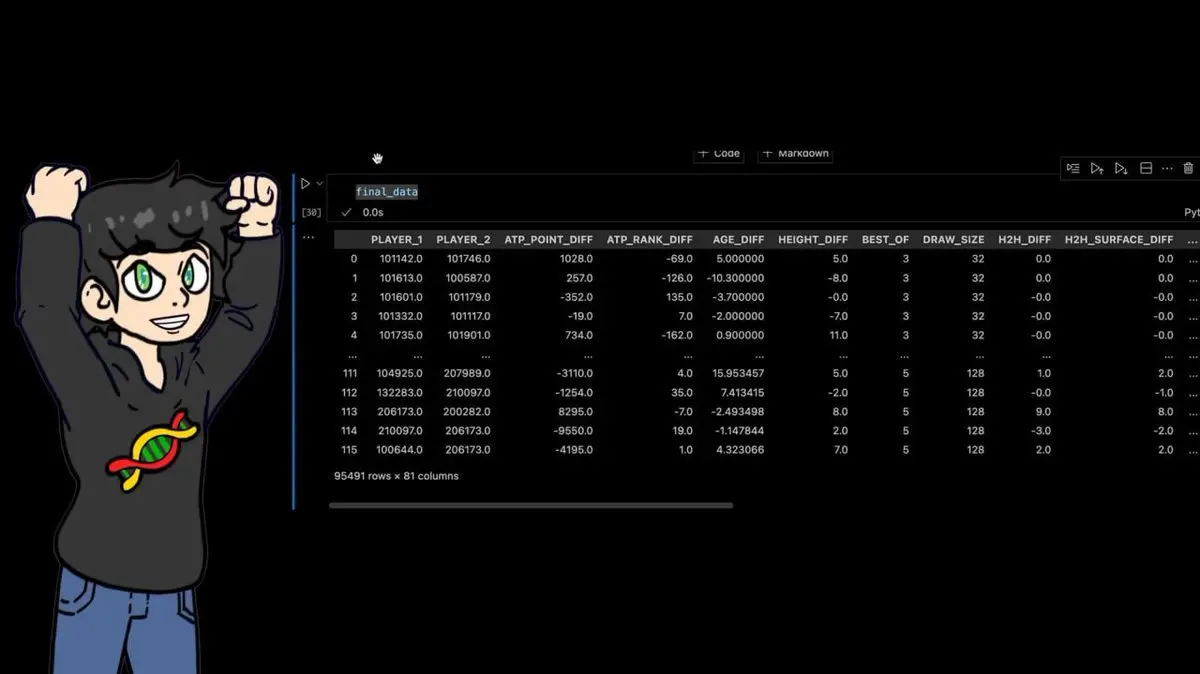
Итоговый набор данных: 95 491 строка и 81 столбец.
Каждый матч за последние 40 лет — с десятками вручную рассчитанных признаков.
Второй шаг: алгоритм, заимствованный у «Титаника»

Перед тем как подать данные в классификатор, он решил полностью понять, как работает алгоритм. Для этого он с нуля написал на numpy дерево решений.
Дерево решений работает как логическая игра — задавая последовательность вопросов, оно постепенно приближается к ответу.
Чтобы объяснить этот принцип, он взял совершенно другой датасет — Titanic.
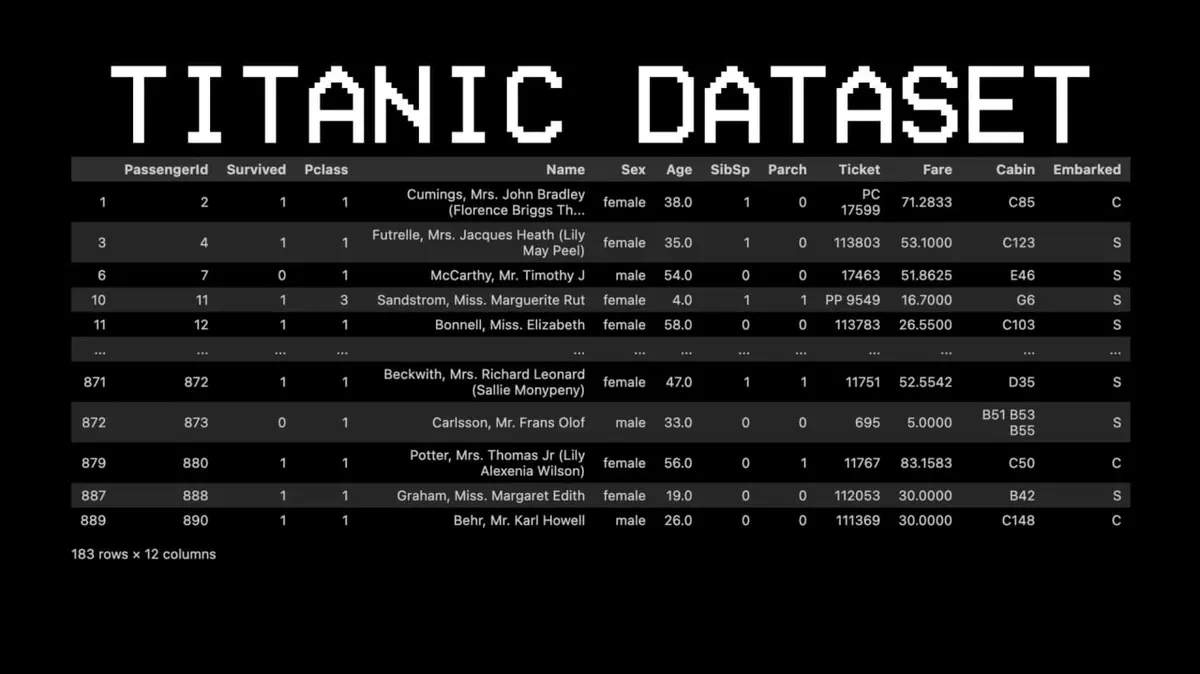
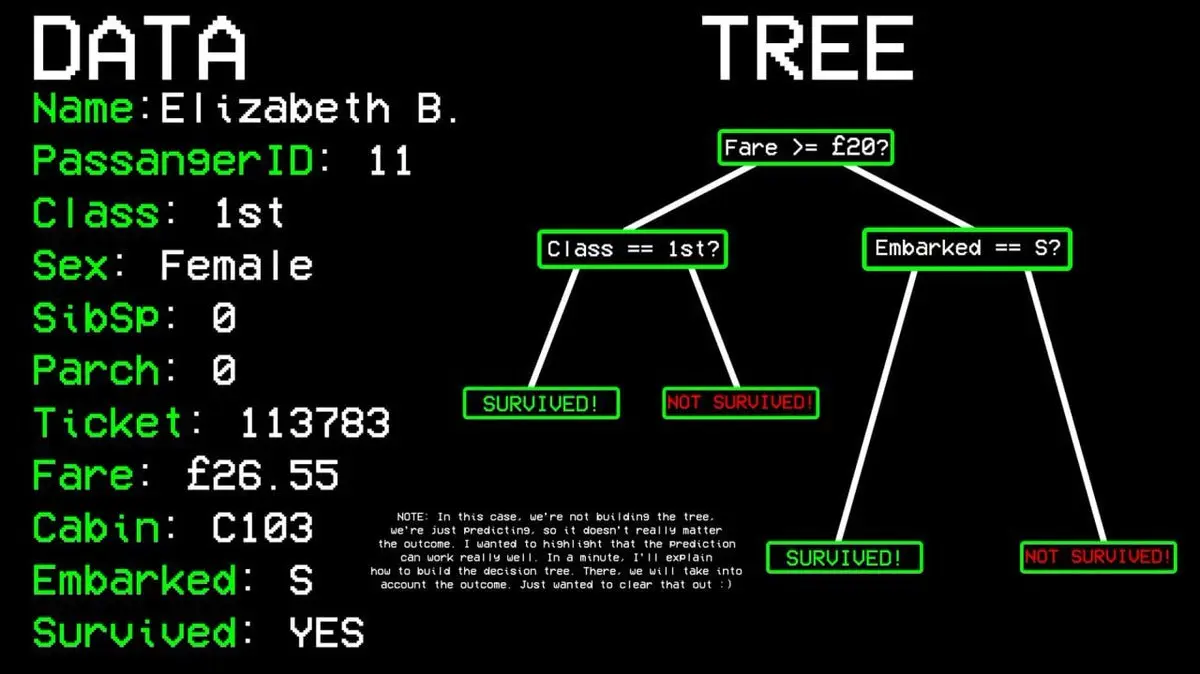
Например: выживет ли пассажир №11?
- Вопрос 1: Он в первом классе? → Да.
- Вопрос 2: Он женщина? → Да.
- Предсказание: выживет.
Как алгоритм решает, какие вопросы задавать?
Он ищет самый сильный признак, который лучше всего разделяет «выжил» и «не выжил». В данных Titanic этим признаком оказалась классность билета. Пассажиры первого класса идут в одну ветку, остальные — в другую.
Но и среди первых класса есть погибшие, значит, разделение не идеально — есть «нечистые» узлы. Тогда алгоритм ищет следующий лучший признак — пол. Все женщины в первом классе выжили, образовав «чистый узел», и ветка завершилась.
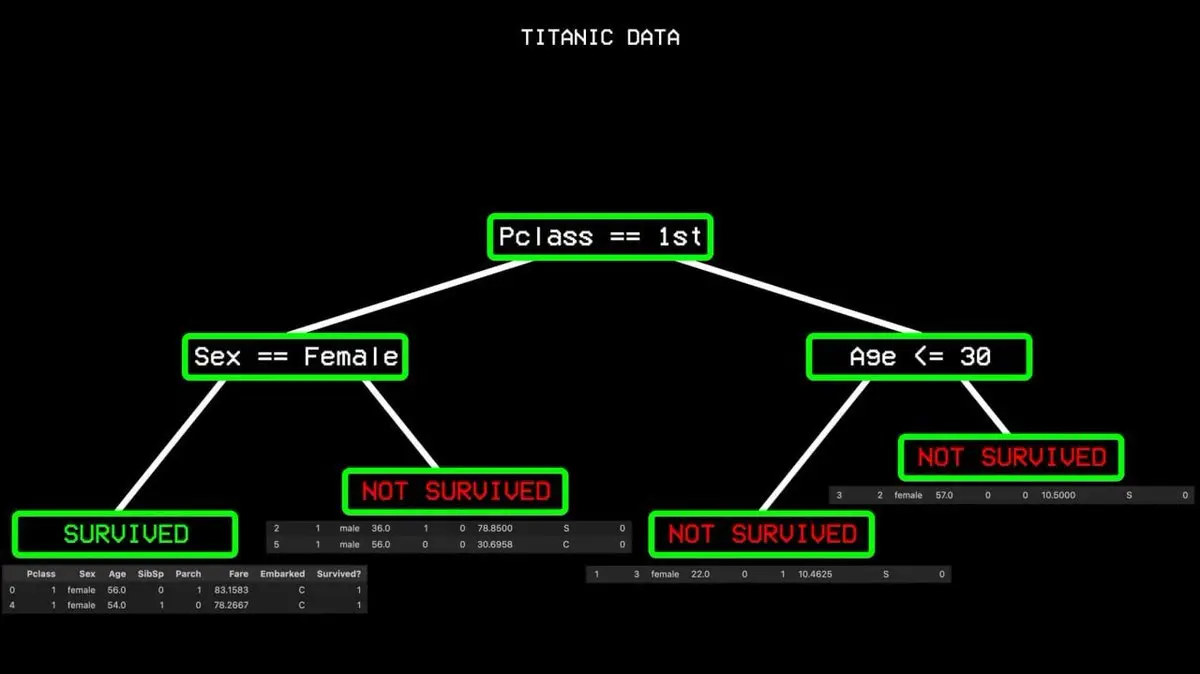
Этот процесс повторяется, пока не построится полное дерево, охватывающее все случаи.
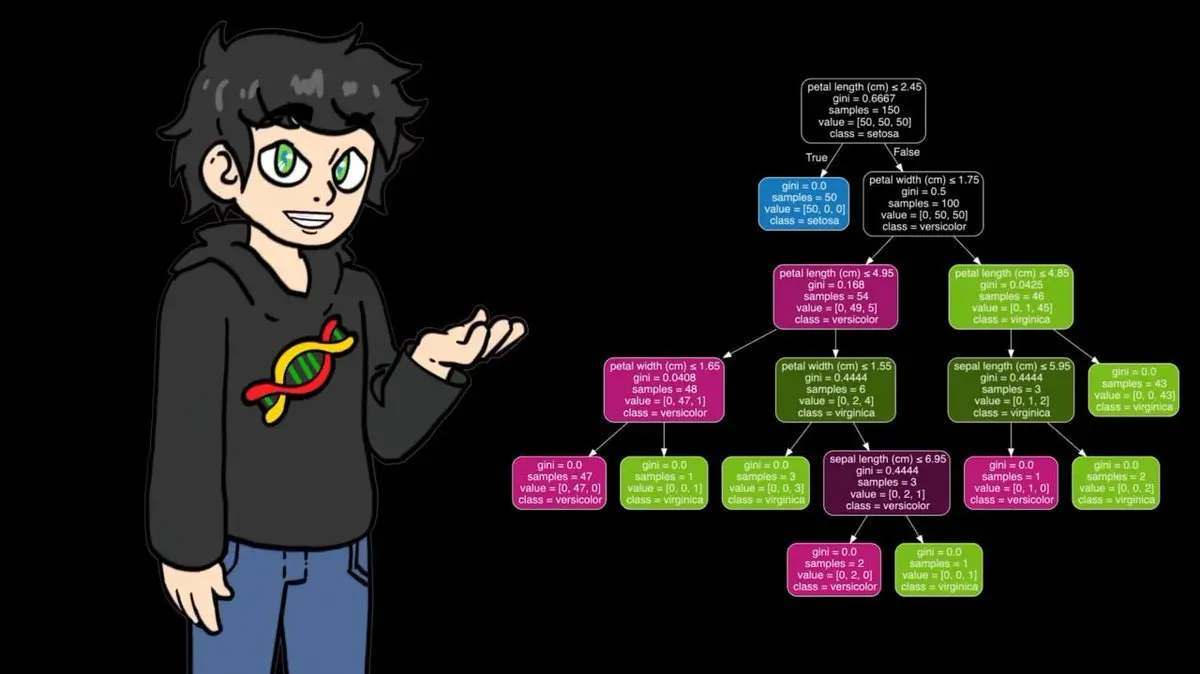
Моя собственная реализация на numpy хорошо работает на небольших данных, но при использовании 95 000 матчей она становится очень медленной. Поэтому в финальной стадии он перешёл на более оптимизированную версию из sklearn, которая работает быстрее, сохраняя тот же принцип.
Третий шаг: выявление ключевых переменных для победы
Перед обучением модели он построил матрицу рассеяний (pairplot) всех признаков, чтобы найти закономерности, разделяющие победителей и проигравших.

Большинство признаков — шум. ID игроков явно бесполезен. Разница в победных процентах показывает некоторые закономерности, но недостаточно явно, чтобы использовать их для надёжного предсказания.
Единственный признак, который выделялся — разница в ELO (ELO_DIFF).
Диаграммы рассеяния ELO_DIFF и ELO_SURFACE_DIFF показывают чёткое разделение двух классов, остальные признаки не идут ни в какое сравнение.
Это открытие стало основой для построения самой важной части проекта.
Четвертый шаг: внедрение системы оценки ELO из шахмат
ELO — это система оценки уровня игрока, впервые применённая в шахматах. Сейчас рейтинг Магнуса Карлсена — 2833.

Он решил применить эту систему к теннису:
- Начальный рейтинг каждого игрока — 1500
- Победа — повышение рейтинга; поражение — снижение
Механизм: насколько много очков меняется, зависит от разницы в рейтингах с соперником. Победить более сильного — получить больше очков, проиграть более слабому — потерять больше.
На финале Уимблдона 2023 он продемонстрировал работу формулы: Карлос Алькарас (рейтинг 2063) против Новак Джоковича (рейтинг 2120). Алькарас выиграл, сделав обратный камбэк.

Подставляя в формулу: Алькарас +14 очков, Джокович —14.
Хотя расчет очень прост, при применении к 43-летней истории данных он показывает поразительный эффект.
Пятый шаг: визуализация доминирования тройки великих
Он построил график рейтинга Федерера за всю карьеру — от дебюта до ухода — каждое его выступление видно на графике.
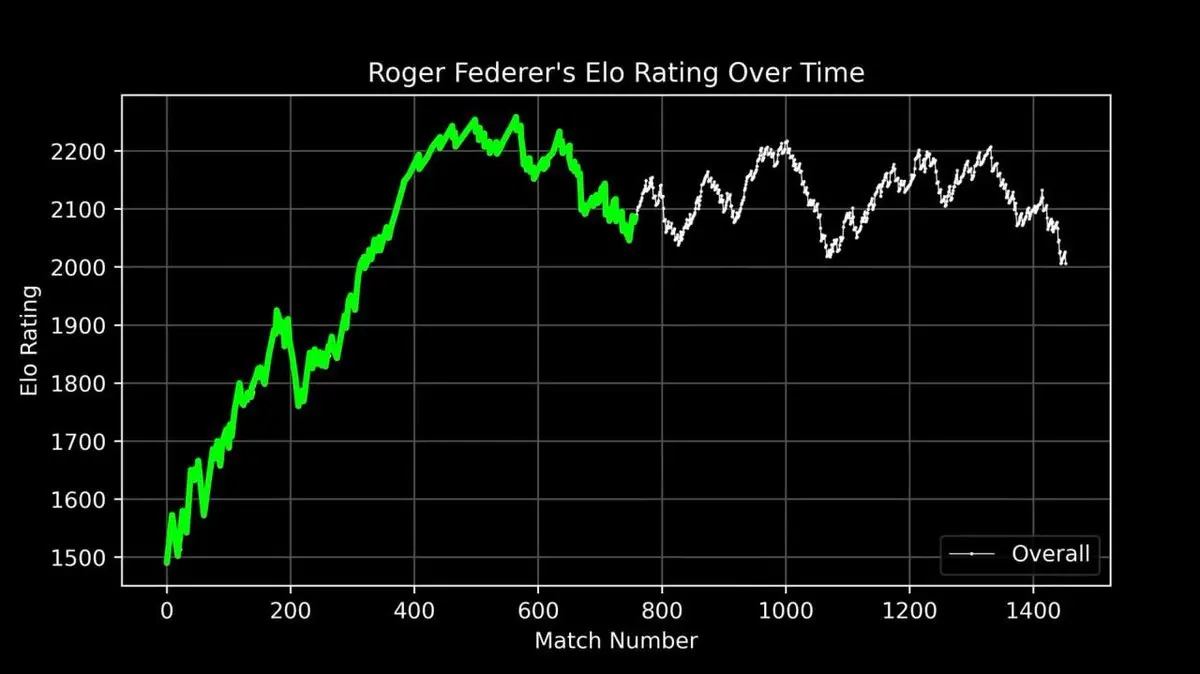
Эта кривая — полная история легенды: быстрый рост в начале, абсолютное доминирование в пике (примерно после 400 матчей), и колебания в конце карьеры.
Но по-настоящему потрясающе — когда он сравнил рейтинг Федерера с рейтингами всех ATP-игроков с 1985 года:
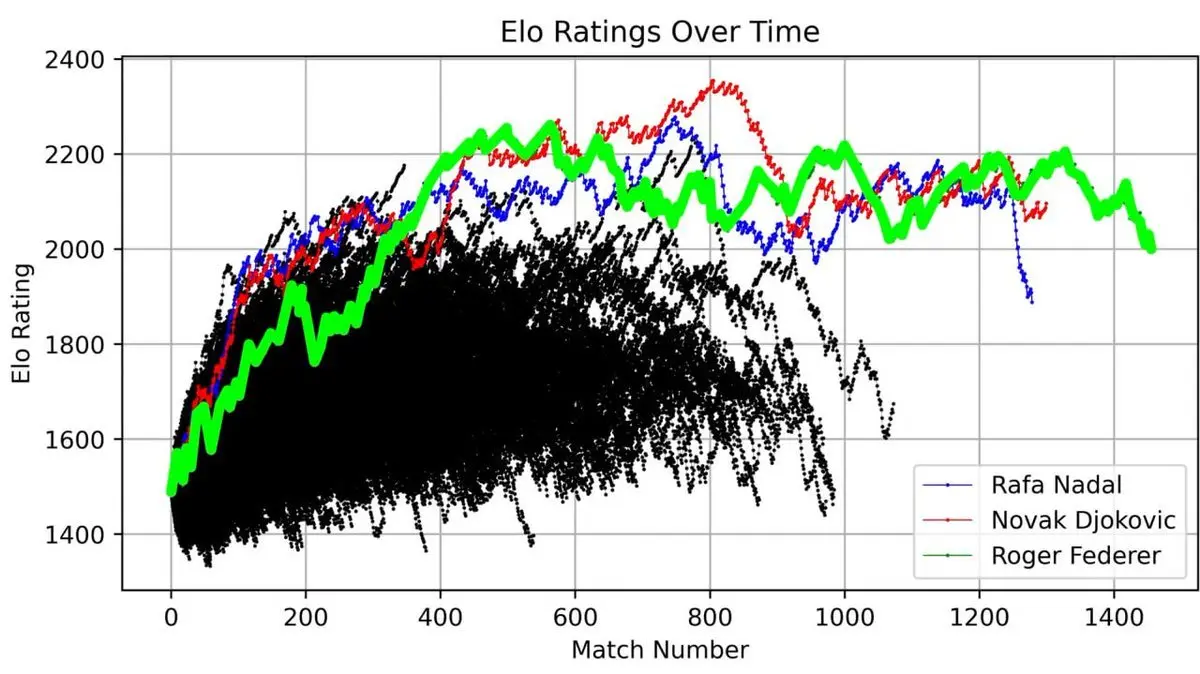
Три линии — Федерер (зелёная), Надаль (синяя), Джокович (красная) — возвышаются над остальными.
Титул «Великих трёх» — не просто название. Визуализация 40-летних данных показывает, что их доминирование — это математический факт.
По их собственной системе ELO, сейчас лидирует Янник Синнер (2176), затем Джокович (2096) и Алькарас (2003).

Запомните, что Синнер — лидер, это очень важно для дальнейших выводов.
Шестой шаг: место — переменная, меняющая всё
Тип покрытия корта кардинально меняет ход игры:
- Грунт — медленный, высокий отскок
- Трава — быстрый, низкий отскок
- Твердая поверхность — промежуточная
Игрок, доминирующий на одном покрытии, может полностью провалиться на другом.
Поэтому он создал отдельные рейтинги ELO для каждого типа покрытия: грунт, трава, твердая.
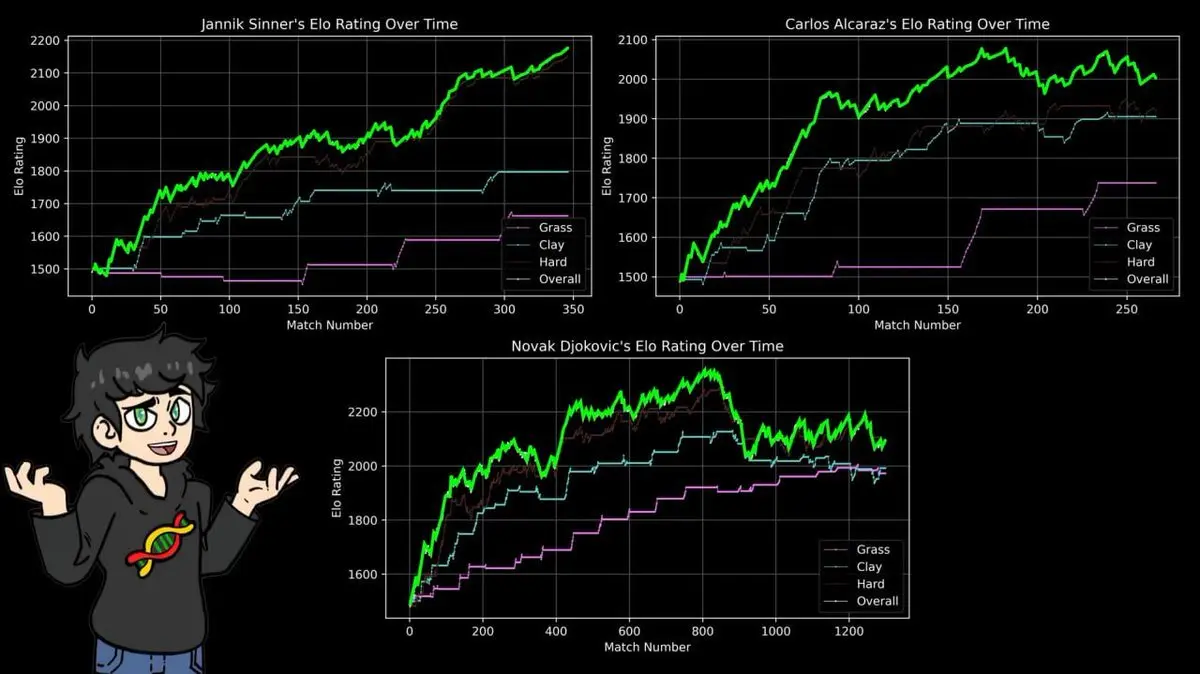
Результаты подтвердили известный факт и 43-летние данные — пиковый рейтинг Надаля на грунте выше, чем лучший рейтинг Федерера на траве, а лучший рейтинг Джоковича на твердом покрытии — выше, чем любой другой в истории.
14 титулов на Roland Garros, 112 побед и 4 поражения.
Формула ELO не учитывает нарративы или славу — она просто фиксирует победы и поражения. И её выводы полностью совпадают с 40-летней спортивной хроникой.
Седьмой шаг: столкновение с потолком
Данные подготовлены, система ELO настроена — он начал обучать классификатор. Этот этап отлично показывает важность выбора алгоритма.
Дерево решений: точность 74%
Одно дерево решений на полном наборе данных достигло 74% точности. Звучит неплохо — пока не узнаешь, что просто разница в ELO уже дает 72%.
Дерево почти не улучшило результат по сравнению с этим простым признаком.
Случайный лес: точность 76%
Проблема одного дерева — высокая вариативность (high variance), оно слишком чувствительно к выборке данных. Решение — случайный лес: строить десятки или сотни деревьев, каждое на случайной подвыборке и с разными признаками, и голосовать большинством.

94 разных дерева голосуют за каждую игру.

Результат — 76%. Улучшение есть, но потолок — 77%. Как бы он ни настраивал гиперпараметры, менял признаки или данные — точность не поднималась выше этого уровня.
Восьмой шаг: прорыв через потолок
Затем он попробовал XGBoost — «статусный» вариант случайного леса.
Главное отличие — случайный лес строит деревья параллельно и усредняет, а XGBoost строит их последовательно, каждое исправляя ошибки предыдущих. Вводится регуляризация, чтобы избежать переобучения, и каждое дерево делается небольшим, чтобы не заучивать данные.
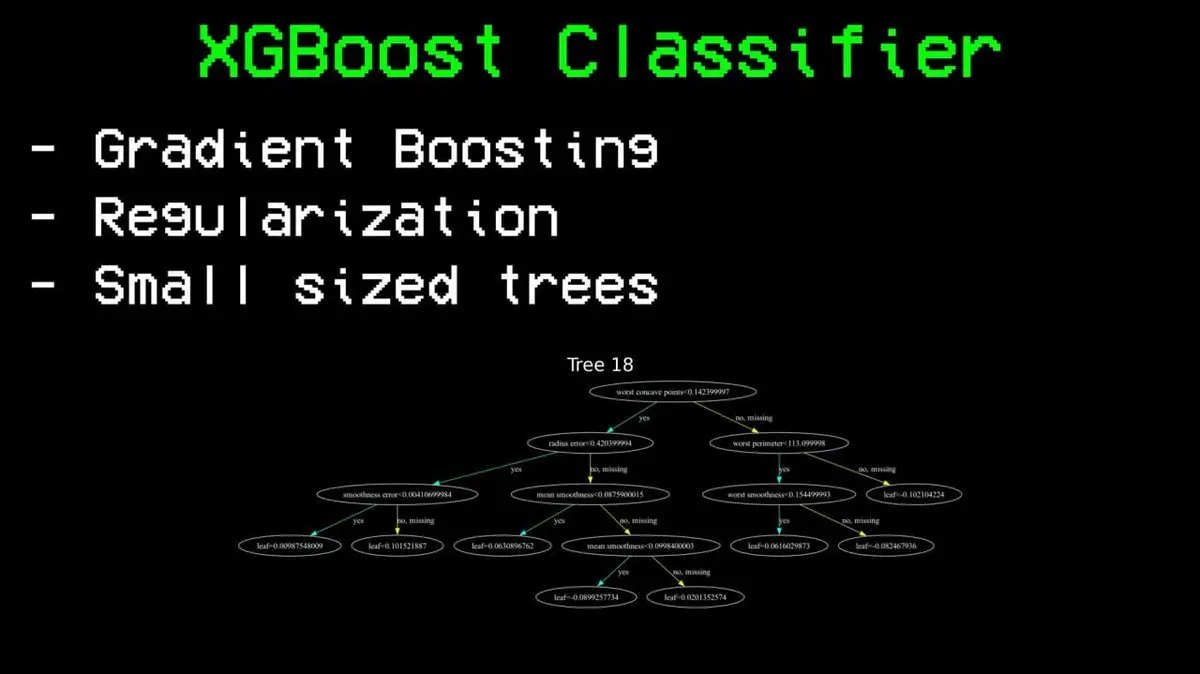
Результат — точность 85%.
Это — огромный скачок по сравнению с потолком в 76%. Те же данные, те же признаки — только алгоритм изменился.
XGBoost также показывает, что три самых важных признака — разница в ELO, разница в ELO по поверхности и общий ELO. Эта система оценки, заимствованная из шахмат, оказалась самой сильной для предсказаний.
Для сравнения, он обучил нейронную сеть на тех же данных — точность 83%. Хорошо, но всё равно уступает XGBoost. В этом наборе данных деревья побеждают.
Девятый шаг: решающий бой — Australian Open 2025
Все предыдущие модели обучались на данных до декабря 2024 года.
Но январский Australian Open 2025 — это полностью новая ситуация, которая не входит в обучающий набор. Это идеальный тест: сможет ли модель понять истинные закономерности тенниса или просто запомнить прошлые шаблоны?

Он загрузил весь турнир в модель и попросил её предсказать каждый матч.
Результат: из 116 матчей модель правильно предсказала 99, ошиблась всего в 17 — точность 85,3%.
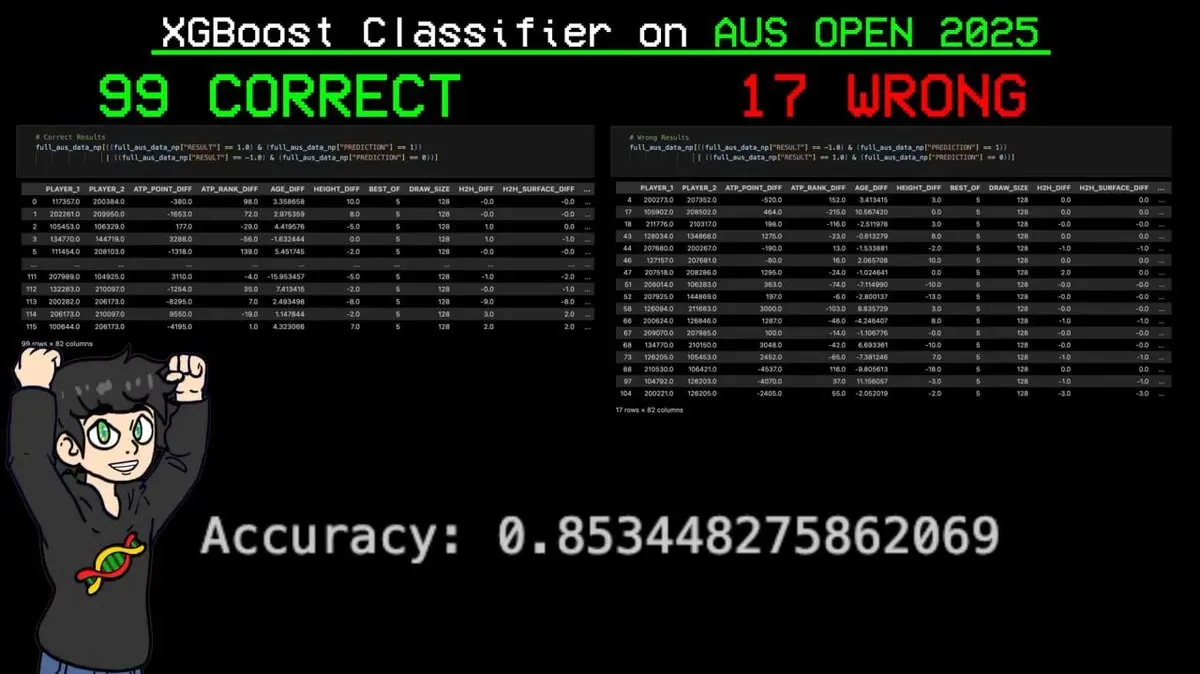
Самое важное — модель точно предсказала победу Янника Синнера (самого рейтингового игрока по системе ELO) во всех матчах турнира.
До того, как мяч коснулся корта, AI уже предсказал победителя — чемпиона Большого шлема.
Итог
Один человек, один ноутбук, без собственных данных, без дорогой инфраструктуры, без исследовательской команды — и при этом создана модель предсказания профессионального тенниса с точностью 85%, которая смогла предсказать чемпиона до начала турнира.
Данные по теннису доступны на GitHub — всё воспроизводимо.
Создавать чудеса сегодня — не мечта, а реальность, которая ближе, чем когда-либо.
Настоящий разрыв не в ресурсах, а в желании и умении что-то делать.