Источник: 华尔街见闻
16 марта 2026 года состоялась официальная церемония открытия конференции NVIDIA GTC 2026, на которой основатель и CEO NVIDIA 黄仁勋 выступил с ключевой речью.
На этой мероприятии, которое считается «ежегодным паломничеством AI-индустрии», 黄仁勋 рассказал о трансформации NVIDIA — от «компании по производству чипов» к «инфраструктурной и фабричной компании AI». В условиях, когда рынок особенно озабочен вопросами устойчивости показателей и потенциала роста, он подробно разобрал базовую бизнес-логику, движущую будущим ростом — «Token фабричная экономика».

Очень оптимистичные прогнозы по показателям — «к 2027 году спрос минимум на 1 трлн долларов»
За последние два года глобальный спрос на вычисления для AI взорвался экспоненциально. По мере эволюции больших моделей — от «восприятия» и «генерации» к «выводам» и «исполнению задач» — потребление вычислительных ресурсов резко возросло. В ответ на высокую озабоченность рынка по поводу потолка заказов и доходов 黄仁勋 дал очень сильные прогнозы.
В своей речи он прямо заявил:
В это время прошлого года я говорил, что мы видим спрос на 500 миллиардов долларов с высокой уверенностью, охватывающий Blackwell и Rubin до 2026 года. Сейчас, прямо здесь и сейчас, я вижу спрос минимум на 1 триллион долларов к 2027 году.

Планируемый прогноз 黄仁勋 о триллионе долларов ранее вызвал рост акций NVIDIA более чем на 4,3%.
Более того, он добавил:
Это ли реально? Об этом я сейчас и расскажу. На самом деле, спрос даже превысит предложение. Я уверен, что реальные вычислительные потребности будут гораздо выше.
黄仁勋 отметил, что системы NVIDIA уже доказали свою эффективность как «самая дешевая инфраструктура в мире». Благодаря тому, что NVIDIA способна запускать практически все модели AI в различных сферах, эта универсальность позволяет клиентам максимально эффективно использовать вложенные в этот триллион долларов средства и сохранять их долгий жизненный цикл.
На данный момент 60% бизнеса NVIDIA приходится на крупнейшие облачные провайдеры — топ-5, а остальные 40% распределены между суверенными облаками, корпоративным сектором, промышленностью, робототехникой и edge-компьютингом.
Token фабричная экономика: мощность за ватт определяет бизнес
Чтобы объяснить обоснованность этого спроса на 1 трлн долларов, 黄仁勋 представил глобальным CEO новую бизнес-модель. Он указал, что будущие дата-центры перестанут быть просто хранилищами данных — они станут «фабриками» по производству Token (базовых единиц AI-генерации).

黄仁勋 подчеркнул:
Каждый дата-центр, каждая фабрика по определению ограничена электропитанием. Фабрика мощностью 1 ГВт (гигаватт) никогда не станет 2 ГВт — это законы физики и атомов. При фиксированной мощности тот, у кого на ватт больше Token пропускной способности, будет иметь более низкие издержки производства.
黄仁勋 разделил будущие AI-сервисы на уровни бизнеса:
Бесплатный уровень (высокий пропуск, низкая скорость)
Средний уровень (~3 доллара за миллион токенов)
Продвинутый уровень (~6 долларов за миллион токенов)
Быстрый уровень (~45 долларов за миллион токенов)
Уровень сверхбыстрого (~150 долларов за миллион токенов)
Он отметил, что по мере увеличения размера моделей и длины контекста AI станет умнее, но скорость генерации токенов снизится. 黄仁勋 заявил:
В этой Token фабрике ваш пропускной поток и скорость генерации токенов напрямую определяют ваш доход в следующем году.
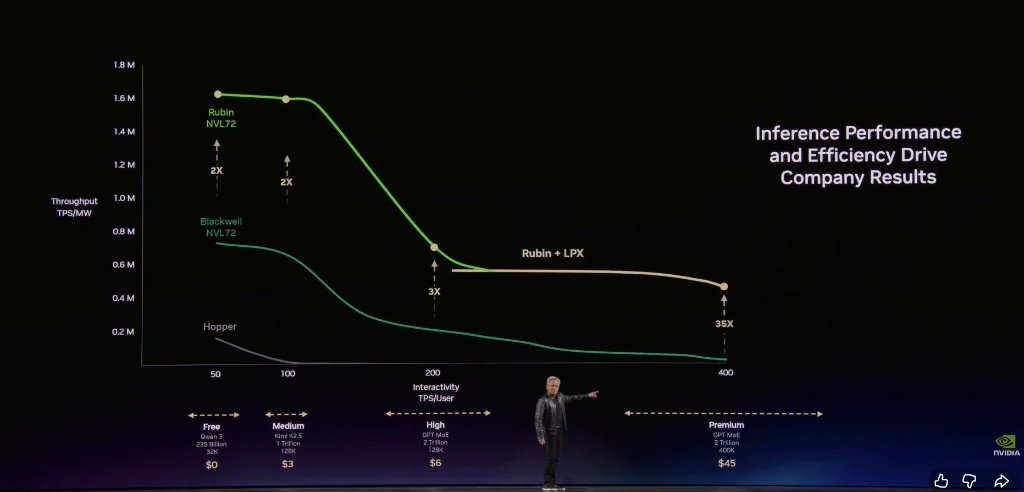
黄仁勋 подчеркнул, что архитектура NVIDIA позволяет клиентам достигать очень высокой пропускной способности на бесплатном уровне, а на самом ценном уровне — в inference — повышать производительность в 35 раз.
Vera Rubin за два года ускорилась в 350 раз, Groq дополняет сверхскоростной inference
В условиях физических ограничений NVIDIA представила свою самую сложную систему AI — Vera Rubin. 黄仁勋 отметил:
Ранее я показывал Hopper — я поднимал чип, он был милым. Но говоря о Vera Rubin, все думают о всей системе. В этой полностью жидкостной системе, полностью избавленной от традиционных кабелей, р racks, которые раньше занимали два дня для установки, теперь устанавливаются за два часа.
黄仁勋 подчеркнул, что благодаря экстремальному end-to-end со-дизайну аппаратного и программного обеспечения Vera Rubin за два года увеличила скорость генерации токенов с 22 миллиона до 700 миллионов — рост в 350 раз. Для сравнения, по закону Мура за тот же период прирост составляет около 1,5 раза.
Для решения узких мест при сверхскоростном inference (например, 1000 токенов/сек) NVIDIA предложила интеграцию приобретенной компании Groq — асимметризированное разделение inference. 黄仁勋 объяснил:
Эти два процессора имеют кардинально разные характеристики. Чип Groq обладает 500 МБ SRAM, а Rubin — 288 ГБ памяти.

黄仁勋 отметил, что с помощью программной системы Dynamo, объединяющей эти решения, Vera Rubin передает этапы «предзаполнения» (Pre-fill) и «декодирования» (Decode) на Vera Rubin, а чувствительный к задержкам этап «декодирования» — на Groq. Он также дал рекомендации по конфигурации вычислительных мощностей:
Если ваша работа — высокая пропускная способность, используйте 100% Vera Rubin; если у вас много задач по генерации токенов высокого уровня, выделите 25% дата-центра под Groq.
Сообщается, что чип Groq LP30, произведенный Samsung, уже в массовом производстве и ожидается поставка в третьем квартале, а первый rack Vera Rubin уже работает в облаке Microsoft Azure.
Кроме того, в области оптоволоконных технологий NVIDIA продемонстрировала первую в мире серийную оптическую коммутатор Spectrum X, что утихомирило споры о «отходе от медных кабелей к оптике»:
Нам нужно больше мощностей по производству медных кабелей, оптических чипов и CPO.
Agent: конец традиционного SaaS — «годовая оплата + Token» становится стандартом Кремниевой долины
Помимо аппаратных барьеров, 黄仁勋 уделил много внимания революции в программном обеспечении AI и экосистеме, особенно — взрыву Agent (интеллектуальных агентов).
Он назвал проект OpenClaw «самым популярным open-source проектом в истории человечества», отметив, что за несколько недель он превзошел достижения Linux за 30 лет. 黄仁勋 прямо заявил, что OpenClaw — это «операционная система» для Agent-компьютеров.
黄仁勋 подчеркнул:
Каждая SaaS-компания станет AaaS (Agent-as-a-Service, агент как услуга). Безусловно, чтобы обеспечить безопасность таких агентов, обладающих доступом к чувствительным данным и возможностью выполнять код, NVIDIA выпустила корпоративный референс-дизайн NeMo Claw, включающий движок стратегий и приватный маршрутизатор.
Для обычных работников эта революция тоже уже близка. 黄仁勋 описал будущие новые формы работы:
В будущем у каждого инженера в компании будет годовой бюджет токенов. Их базовая зарплата может составлять десятки тысяч долларов, а дополнительно я выделю примерно половину этой суммы в виде токенов, чтобы повысить их эффективность в 10 раз. Это уже новый рекрутинговый козырь в Кремниевой долине: сколько токенов входит в ваше предложение?
В заключение, 黄仁勋 «слил» информацию о следующем поколении архитектуры — Feynman, которая впервые реализует совместное масштабирование по медным и CPO-каналам. Еще более захватывающе — NVIDIA разрабатывает космический дата-центр «Vera Rubin Space-1», полностью расширяющий возможности AI за пределы Земли.
Полный перевод речи 黄仁勋 на GTC 2026 (с помощью AI-инструментов):
Ведущий: Добро пожаловать на сцену основателя и CEO NVIDIA 黄仁勋.
黄仁勋, основатель и CEO:
Добро пожаловать на GTC. Хочу напомнить, что это технологическая конференция. Мне очень приятно видеть столько людей, стоящих в очереди с раннего утра, и присутствующих здесь.
На GTC мы сосредоточимся на трех ключевых темах: технологиях, платформах и экосистеме. В настоящее время у NVIDIA есть три основные платформы: CUDA-X, системная платформа и наша новейшая платформа AI фабрик.
Перед началом я хочу поблагодарить наших ведущих — Sarah Guo из Conviction, Alfred Lin из Sequoia Capital (первого венчурного инвестора NVIDIA) и Gavin Baker — первого крупного институционального инвестора NVIDIA. Эти три человека глубоко разбираются в технологиях и имеют огромное влияние в технологической экосистеме. Также благодарю всех уважаемых гостей, которых я лично пригласил. Ваша команда — звездная команда.
Также благодарю всех компаний, присутствующих сегодня. NVIDIA — это платформа, у нас есть технологии, платформа и богатая экосистема. Представители компаний, присутствующие здесь, — почти все участники индустрии на сумму в 100 трлн долларов. В этом году в мероприятии участвуют 450 компаний — спасибо вам.
Всего на конференции запланировано 1000 технических форумов и 2000 спикеров, охватывающих все уровни «пятислойной архитектуры» AI — от инфраструктуры (земля, электроснабжение, дата-центры) до чипов, платформ, моделей и приложений, движущих индустрию вперед.
CUDA: двадцать лет технологического наследия
Все начинается здесь. Этот год — двадцатилетие CUDA.
За эти двадцать лет мы постоянно развивали эту архитектуру. CUDA — революционное изобретение — технология SIMT (Single Instruction Multiple Threads), которая позволяет разработчикам писать программы на скалярном коде и расширять их до многопоточных приложений, значительно проще, чем предыдущие SIMD-архитектуры. Недавно мы добавили Tiles, чтобы упростить программирование тензорных ядер (Tensor Core) и математических структур, на которых основан современный AI. Сейчас CUDA включает тысячи инструментов, компиляторов, фреймворков и библиотек, сотни тысяч открытых проектов и глубоко интегрирована во все технологические экосистемы.
Эта диаграмма — отражение всей стратегии NVIDIA. Я постоянно показываю ее. Самое сложное и важное — это нижняя часть «установленных систем» (install base). За двадцать лет мы накопили сотни миллионов GPU и вычислительных систем, работающих на CUDA.
Наши GPU охватывают все облачные платформы и обслуживают практически всех производителей ПК и отраслей. Огромный объем установленных систем — это движущая сила этого «флювия»: привлекает разработчиков, которые создают новые алгоритмы и достигают прорывов, что порождает новые рынки и экосистемы, привлекает еще больше компаний, и так далее. Этот цикл ускоряется.
Загрузка драйверов NVIDIA растет с ошеломляющей скоростью, масштаб огромен и продолжает расти. Этот цикл позволяет нашей вычислительной платформе поддерживать огромное количество приложений и новых прорывов.
Более того, он обеспечивает очень долгий срок службы инфраструктуры: приложения на базе NVIDIA CUDA очень разнообразны — от всех этапов жизненного цикла AI, платформ обработки данных до научных расчетов. Поэтому, установив GPU NVIDIA, вы получаете очень высокую ценность. Именно поэтому цена на GPU архитектуры Ampere, выпущенные шесть лет назад, в облаке растет.
Все это — благодаря огромному объему установленных систем, мощному циклу и широкой экосистеме разработчиков. Когда эти факторы работают вместе, и мы постоянно обновляем программное обеспечение, стоимость вычислений снижается. Ускоренные вычисления повышают производительность приложений, а долгосрочная поддержка и обновления снижают издержки. Мы готовы поддерживать каждую GPU в мире, потому что архитектура совместима.
Это — наш подход, потому что объем установленных систем так велик, что каждое обновление приносит пользу миллионам пользователей. Такой динамический цикл расширяет охват, ускоряет рост и снижает издержки, стимулируя новые возможности. CUDA — ядро всей этой системы.
От GeForce к CUDA: 25 лет эволюции
Наш путь с CUDA начался еще 25 лет назад.
Многие из вас выросли с GeForce. Это наш самый успешный маркетинговый проект. Мы начали формировать будущих клиентов еще тогда, когда вы не могли позволить себе купить продукт — ваши родители стали первыми пользователями NVIDIA, покупая наши продукты год за годом, пока не выросли и не стали специалистами в области компьютерных наук, настоящими клиентами и разработчиками.
Это — основа, заложенная 25 лет назад с GeForce. Тогда мы изобрели программируемый шейдер — очевидное, но очень важное изобретение, которое сделало ускорители программируемыми, — первый в мире программируемый ускоритель, пиксельный шейдер. Через пять лет мы создали CUDA — одно из наших самых важных вложений. Тогда у нас было мало ресурсов, но мы вложили большую часть прибыли в развитие CUDA, чтобы расширить его с GeForce на все компьютеры. Мы были убеждены в его потенциале. Вначале было трудно, но мы держались за эту идею 13 поколений и 20 лет, и сегодня CUDA — везде.
Пиксельный шейдер стал революцией для GeForce. А около восьми лет назад мы выпустили RTX — кардинально обновив архитектуру для современного графического компьютера. GeForce принес CUDA всему миру, и именно благодаря этому ученые, такие как Алекс Кризевский, Илья Сутскевер, Говард Хинтон, Эндрю Нг, обнаружили, что GPU — мощный инструмент для ускорения глубокого обучения, что вызвало взрыв AI десять лет назад.
Десять лет назад мы решили объединить программируемое шейдерное программирование с двумя новыми концепциями: аппаратным трассированием лучей (Ray Tracing), что было очень сложно реализовать, и предвидением, что AI полностью изменит графику. Так же, как GeForce принес AI всему миру, AI сейчас возвращает и переосмысливает способы реализации компьютерной графики.
Сегодня я покажу вам будущее. Это наше новое поколение графических технологий — нейронное рендеринг (Neural Rendering), глубокое слияние 3D-графики и AI. Вот DLSS 5, смотрите.
Нейронное рендеринг: слияние структурированных данных и генеративного AI
Это впечатляет? Графика оживает.
Что мы сделали? Мы соединили управляемую 3D-графику (реальную основу виртуального мира) с ее структурированными данными и внедрили генеративный AI и вероятностные вычисления. Одно — полностью детерминированное, другое — вероятностное, очень реалистичное. Мы объединили эти подходы, реализуя точное управление через структурированные данные и генерацию в реальном времени. В итоге контент получается красивым, впечатляющим и полностью управляемым.
Идея объединения структурированных данных и генеративного AI будет повторяться во многих отраслях. Структурированные данные — основа доверенного AI.
Платформы ускорения структурированных и неструктурированных данных
Теперь я покажу вам схему архитектуры.
Структурированные данные — это SQL, Spark, Pandas, Velox, а также платформы Snowflake, Databricks, Amazon EMR, Azure Fabric, Google BigQuery — все работают с Data Frame. Эти Data Frame — гигантские таблицы, содержащие всю бизнес-информацию, — фундаментальные факты для предприятий.
В эпоху AI нам нужно, чтобы AI использовал структурированные данные и достигал их максимального ускорения. В прошлом ускорение обработки структурированных данных было для повышения эффективности бизнеса. В будущем AI будет использовать эти данные с гораздо большей скоростью, чем человек, и агенты AI будут обращаться к базам данных в огромных объемах.
Что касается неструктурированных данных — векторные базы данных, PDF, видео, аудио — это большинство данных в мире. Ежегодно создается около 90% неструктурированных данных. Раньше эти данные почти не использовались: мы читали их, сохраняли в файловых системах, и всё. Мы не могли их быстро искать или извлекать, потому что у них нет простых индексов, нужно понимать смысл и контекст. Сейчас AI умеет это делать — с помощью мультимодальных технологий восприятия и понимания, он читает PDF, понимает их содержание и встраивает их в большие структурированные базы для поиска.
Для этого NVIDIA создала два базовых библиотеки:
- cuDF — для ускоренной обработки структурированных данных
- cuVS — для обработки векторных, семантических и неструктурированных AI-данных
Эти платформы станут одними из важнейших базовых.
Сегодня мы объявляем о сотрудничестве с несколькими компаниями. IBM — создатель SQL — использует cuDF для ускорения платформы WatsonX Data. Dell совместно с нами создает платформу Dell AI Data, объединяя cuDF и cuVS, и показывает значительный рост производительности в проектах NTT Data. Google Cloud ускоряет не только Vertex AI, но и BigQuery, а также снизил затраты на вычисления для Snapchat почти на 80%.
Преимущества ускоренных вычислений — скорость, масштаб и стоимость. Это продолжение закона Мура — ускорение производительности и снижение стоимости за счет оптимизации алгоритмов, что позволяет всем пользоваться преимуществами.
NVIDIA создала платформу ускоренных вычислений, объединяющую библиотеки: RTX, cuDF, cuVS и другие. Эти библиотеки интегрированы в глобальные облака и OEM-экосистемы, чтобы достигать пользователей по всему миру.
Глубокое сотрудничество с облачными провайдерами
Сотрудничество с ведущими облачными платформами:
Google Cloud: ускоряем Vertex AI и BigQuery, глубоко интегрируемся с JAX/XLA, а также с PyTorch — NVIDIA единственная компания, которая показывает отличные результаты на обеих платформах. В рамках этого мы привели в экосистему Google Cloud клиентов — Base10, CrowdStrike, Puma, Salesforce.
AWS: ускоряем EMR, SageMaker и Bedrock, глубоко интегрируемся с AWS. В этом году особенно радостно — мы интегрируем OpenAI в AWS, что значительно увеличит потребление облачных ресурсов AWS и расширит региональные развертывания OpenAI.
Microsoft Azure: первый в мире суперкомпьютер на 100 ПФЛОПС — это наш созданный суперкомпьютер, и он первый, развернутый в Azure. Это важная база для сотрудничества с OpenAI. Мы ускоряем облачные сервисы Azure и AI Foundry, расширяем регионы Azure и тесно сотрудничаем с Bing. Важный момент — наши возможности Confidential Computing, позволяющие даже операторам не видеть данные и модели пользователей — NVIDIA GPU — первые в мире поддерживающие конфиденциальные вычисления, что позволяет безопасно запускать модели OpenAI и Anthropic в облаке по всему миру. Например, мы ускоряем весь цикл EDA и CAD компании Synopsys, размещая его в Microsoft Azure.
Oracle: мы — первый клиент Oracle в области AI, и я горжусь тем, что впервые объяснил Oracle концепцию AI-облака. После этого Oracle быстро развился, и мы внедрили в их системы Cohere, Fireworks, OpenAI и других партнеров.
CoreWeave: первая в мире облачная платформа, созданная специально для GPU и AI, с отличной клиентской базой и быстрым ростом.
Palantir + Dell: совместно создали новую AI-платформу на базе платформы Palantir Ontology и AI-платформы, которая позволяет развертывать AI в любой стране, в любой изолированной среде, полностью локально — от обработки данных (векторизация или структурированные данные) до полного ускорения AI.
NVIDIA и крупнейшие облачные провайдеры создали такую взаимовыгодную экосистему — мы привлекаем клиентов в облако, что выгодно всем.
Вертикальная интеграция и горизонтальное открытие: стратегия NVIDIA
NVIDIA — первая в мире вертикально интегрированная и одновременно открытая компания.
Это очень просто: ускоренные вычисления — не только чипы или системы, а — применение. CPU позволяют компьютеру работать быстрее, но этот путь достиг предела. В будущем только специализированное ускорение в конкретных областях даст новые скачки производительности и снижения издержек.
Именно поэтому NVIDIA глубоко занимается созданием библиотек, решений для каждой отрасли и вертикальных сегментов. Мы — вертикально интегрированная вычислительная компания, другого пути нет. Мы должны понимать приложения, области, алгоритмы и уметь внедрять их в любые сценарии — дата-центры, облака, локальные системы, edge и роботы.
При этом мы остаемся открытыми — готовы интегрировать технологии в платформы партнеров, чтобы все могли пользоваться преимуществами ускоренных вычислений.
Структура участников GTC — яркое подтверждение этого. В этом году больше всего участников из финансового сектора — они хотят разрабатывать, а не торговать. Наша экосистема охватывает всю цепочку поставок. Компании, существующие 50, 70 или 150 лет, показывают рекордные результаты прошлого года. Мы на пороге очень важного события.
CUDA-X: движки ускорения для всех отраслей
В каждой вертикали NVIDIA уже глубоко внедрилась:
- Автопром: широкий охват, значительный эффект
- Финансы: количественные инвестиции переходят от ручных методов к глубокому обучению на суперкомпьютерах, наступает «Transformer момент»
- Медицина: приближается «ChatGPT момент» — AI для поиска лекарств, диагностики, поддержки решений, обслуживания
- Промышленность: идет крупнейшая стройка — AI-фабрики, чиповые заводы, дата-центры
- Развлечения и игры: платформы реального времени для переводов, стриминга, интерактивных игр и умных ассистентов
- Робототехника: более 10 лет развития, три архитектуры — обучение, симуляция, бортовые системы, — всего 110 роботов на выставке
- Телеком: отрасль на 2 трлн долларов, базовые станции превращаются в AI-инфраструктуру — платформа Aerial, партнерство с Nokia, T-Mobile и др.
Все эти области объединяет библиотека CUDA-X — основа алгоритмической компании NVIDIA. Эти библиотеки — ключевые активы, позволяющие платформе приносить реальную пользу в разных отраслях.
Особое место занимает cuDNN — библиотека глубоких нейронных сетей, которая произвела революцию в AI и вызвала современный бум.
(демонстрация CUDA-X)
Все, что вы видели — моделирование, физические решатели, AI-модели для физики и роботов. Все — симуляции, без ручных анимаций или связок суставов. Это — ядро NVIDIA: глубокое понимание алгоритмов и интеграция с вычислительной платформой, открывающая новые возможности.
Корпоративные компании и новая эпоха вычислений
Вы видели гигантов — Walmart, L’Oréal, JPMorgan, Roche, Toyota — и множество новых компаний, о которых вы раньше не слышали, — мы называем их AI-native компании. Их список очень длинный: OpenAI, Anthropic и множество стартапов в разных вертикалях.
За последние два года индустрия взорвалась. В венчурных инвестициях в стартапы вложено рекордные 150 миллиардов долларов. И впервые крупные инвестиции — миллионы, миллиарды долларов — идут в компании, создающие и генерирующие токены или повышающие их стоимость. Этот сектор создает токены, генерирует их или увеличивает их ценность.
Как революции ПК, интернета и мобильных технологий породили эпохальные компании, так и эта новая платформа создаст мощные корпорации — важнейшие игроки будущего.
Три исторических прорыва за последние два года
Что же произошло за эти два года? Три ключевых события.
Первое: ChatGPT — начало эпохи генеративного AI (конец 2022 — 2023)
Он умеет воспринимать, понимать и создавать уникальный контент. Я показывал слияние генеративного AI и графики. Генеративный AI кардинально меняет вычисления — переход от поиска к генерации, что влияет на архитектуру, развертывание и смысл всей системы.
Второе: Reasoning AI (AI-выводы), пример — o1
Способность к выводу позволяет AI размышлять, планировать, разбивать задачи — делить сложные вопросы на шаги. o1 делает генеративный AI надежным, он может оперировать реальной информацией. Для этого увеличивается объем входных токенов и выходных для размышлений, что значительно повышает вычислительные требования.
Третье: Claude Code — первый агентный модель
Он умеет читать файлы, писать код, компилировать, тестировать и улучшать. Claude Code полностью меняет софтверную инженерию — все инженеры NVIDIA используют Claude Code, Codex или Cursor. Это — новая точка перелома: AI уже не только «отвечает», но и «создает», «исполняет», «строит», использует инструменты, читает файлы, разбирается в задачах и действует. AI — от восприятия и генерации — до реальной работы.
За два года вычислительная нагрузка для reasoning выросла примерно в 10 000 раз, а объем использования — в 100 раз. Я всегда считал, что за эти два года спрос на вычисления вырос в миллион раз — это ощущают все, OpenAI, Anthropic. Чем больше мощностей — тем больше токенов, тем выше доходы, тем умнее AI. Порог reasoning уже пройден.
Триллионный эпоха AI-инфраструктуры
Прошлый год я говорил, что спрос и заказы на Blackwell и Rubin к 2026 году — около 500 миллиардов долларов. Сегодня, через год, я говорю: к 2027 году спрос минимум на 1 трлн долларов. И я уверен, что реальный спрос будет гораздо выше.
2025: год inference NVIDIA
2025 — год inference NVIDIA. Мы хотим обеспечить высокую эффективность на всех этапах AI — от обучения до постобработки, чтобы инвестиции в инфраструктуру работали долго и экономично.
Также к платформе присоединились Anthropic и Meta, что составляет треть глобальных вычислительных мощностей AI. Открытые модели приближаются к передовым уровням, они везде.
NVIDIA — единственная платформа, способная запускать все AI-модели — языковые, биологические, графические, компьютерное зрение, речь, белки, химия, роботы — в облаке и на периферии, на любом языке. Архитектура NVIDIA универсальна для всех сценариев, что делает нас самой дешевой и надежной платформой.
60% бизнеса — крупнейшие облачные провайдеры, остальные 40% — региональные облака, суверенные облака, корпорации, промышленность, роботы, edge. Область AI — это новая платформа, которая меняет все.
Grace Blackwell и NVLink 72: смелая архитектурная революция
Когда еще был актуален Hopper, мы решили полностью перестроить систему — расширить NVLink с 8 до 72 линий, провести масштабную реорганизацию. Grace Blackwell NVLink 72 — это крупная технологическая ставка, и я благодарю всех партнеров за поддержку.
Также мы представили NVFP4 — новый тип тензорных ядер и вычислительных блоков. Мы доказали, что NVFP4 может выполнять inference без потери точности, обеспечивая огромный прирост эффективности и энергосбережения, и подходит для обучения. Также появились новые алгоритмы Dynamo и TensorRT-LLM, и мы построили суперкомпьютер DGX Cloud для оптимизации ядра.
Результаты впечатляют: по данным Semi Analysis — самой полной оценки inference NVIDIA — мы лидируем по эффективности на ватт и стоимости токена. В то время как по закону Мура H200 должен был дать прирост в 1,5 раза, мы достигли 35 раз. Dylan Patel из Semi Analysis даже сказал: «黄仁勋 сдерживал обещания, на самом деле — 50 раз». Это — правда.
Я цитирую его: «Jensen sandbagged (黄仁勋 сдерживал обещания).»
Стоимость одного токена у NVIDIA — самая низкая в мире. Это — результат экстремального со-дизайна.
Например, Fireworks — наш софт и алгоритмы — до обновления выдавал около 700 токенов в секунду; после — почти 5000, рост в 7 раз. Это — сила экстремального со-дизайна.
AI фабрика: от дата-центра к фабрике токенов
Раньше дата-центры — это хранилища данных. Теперь — фабрики по производству токенов. Каждая облачная и AI-компания в будущем будет измерять эффективность по «Token фабричной скорости».
Мое главное утверждение:
- Вертикальная ось: пропускная способность (Throughput) — количество токенов в секунду при фиксированной мощности
- Горизонтальная: скорость отклика (Token Speed) — реакция на запрос, чем быстрее, тем больше моделей и длиннее контекст, тем умнее AI
Токен — новая товарная единица, и при зрелости она будет иметь многоуровневое ценообразование:
- Бесплатный уровень (высокий пропуск, низкая скорость)
- Средний (~3 доллара за миллион токенов)
- Продвинутый (~6 долларов)
- Быстрый (~45 долларов)
- Сверхбыстрый (~150 долларов)
По сравнению с Hopper, Grace Blackwell увеличила пропускную способность в 35 раз на самом ценном уровне и добавила новые уровни. При равномерном распределении мощности по 25% на каждый уровень, Grace Blackwell даст в 5 раз больше дохода.
Vera Rubin — следующая генерация AI-вычислений
(видео о Vera Rubin)
Vera Rubin — полностью оптимизированная система для агентных задач:
- ядро — кластер из NVLink 72 GPU для предзаполнения и KV Cache
- новый CPU Vera — для высокой однопоточной производительности, с LPDDR5, уникальный в дата-центрах
- хранилище — BlueField 4 + CX 9, новая платформа для AI
- коммутатор Spectrum X — первый в мире серийный оптический Ethernet
- rack Kyber — поддержка 144 GPU, объединенных NVLink, формирующих единый суперкомпьютер
- Ultra Rubin — следующая версия суперкомпьютера, с вертикальной компоновкой, поддержкой масштабирования
Vera Rubin — полностью жидкостное охлаждение, установка за 2 часа, охлаждение горячей водой 45°C. Satya Nadella подтвердил, что первая система уже работает в Azure. Это — большой шаг.
Интеграция Groq: максимум inference
Мы приобрели команду Groq и получили их технологию. Groq — детерминированный потоковый процессор (Deterministic Dataflow Processor), использующий статическую компиляцию и низкую задержку, — идеально подходит для inference. Но у Groq есть ограничение — всего 500 МБ SRAM, что мешает работать с большими моделями.
Решение — Dynamo — программное обеспечение для управления inference. Мы разделили pipeline:
- Предзаполнение и attention — на Vera Rubin
- Генерация токенов — на Groq
Объединение по Ethernet и специальным режимам уменьшает задержки примерно вдвое. В результате, производительность увеличилась в 35 раз, и открылись новые уровни inference, ранее недоступные.
Комбинация Groq и Vera Rubin:
- при высокой пропускной способности — только Vera Rubin
- при необходимости генерации сложных токенов — добавляем Groq, примерно 25% ресурсов
Чип Groq LP30 уже в массовом производстве, поставки начнутся в Q3. Благодарим Samsung за сотрудничество.
Исторический скачок inference
За два года мощность системы увеличилась в 350 раз — с 22 миллионов токенов/сек до 700 миллионов. Это — результат экстремального со-дизайна.
Технологический план
- Blackwell — текущий продукт, стандартный rack Oberon, расширение NVLink до 576 линий
- Vera Rubin (текущий) — rack Kyber, NVLink 144 (медь), или NVLink 72 + оптика, расширение до 576 линий; Spectrum 6 — первый CPO-коммутатор
- Vera Rubin Ultra — новая версия, с чипом LP35 (включает NVFP4), в несколько раз быстрее
- Feynman — новый GPU, LP40, совместно с Groq, с интеграцией NVFP4; новый CPU Rosa; BlueField 5; CX 10; поддержка как медных, так и оптических каналов в Kyber
Дорожная карта — параллельное развитие трех линий: медь, оптика Scale-Up и Scale-Out, — все партнеры должны расширять производство кабелей, оптики и CPO.
NVIDIA DSX: цифровой двойник AI фабрик
AI фабрики становятся все сложнее, и раньше поставщики технологий работали независимо, только в дата-центре. Это — недостаточно.
Для этого мы создали Omniverse и платформу NVIDIA DSX — платформу для совместного проектирования и эксплуатации гигабитных AI фабрик в виртуальной среде. DSX включает:
- моделирование механики, тепла, электроснабжения, сети
- подключение к электросетям для совместного энергосбережения
- динамическое управление охлаждением и энергопотреблением
По нашим оценкам, это увеличит эффективность использования энергии примерно в 2 раза. Omniverse — платформа для цифровых двойников любой сложности, и мы вместе с партнерами строим крупнейший в истории человечества компьютер.
Также NVIDIA занимается космосом. Чип Thor прошел радиационную сертификацию и уже работает на спутниках. Мы разрабатываем Vera Rubin Space-1 — космический дата-центр. В космосе охлаждение — радиационное, и это — главный вызов. Мы собираем команду лучших инженеров.
OpenClaw: операционная система для интеллектуальных агентов
Peter Steinberger создал OpenClaw — программное обеспечение, которое за несколько недель превзошло достижения Linux за 30 лет. Это — система для Agentic Computing — управляет ресурсами, инструментами, файлами, моделями, выполняет задачи, разбивает их на подзадачи и вызывает подагентов. Поддерживает любые модальности — речь, видео, текст, почту.
Это — операционная система для AI-компьютеров. Windows — для персональных ПК, а OpenClaw — для интеллектуальных агентов.
Каждая компания должна
