
Tác giả: Phosphen
Biên tập; Gans 甘斯, Bagel dự đoán thị trường quan sát
Người đàn ông này đã thu thập dữ liệu của tất cả các trận đấu quần vợt chuyên nghiệp trong 43 năm qua, nhập tất cả vào một mô hình học máy, rồi chỉ hỏi một câu hỏi: Bạn có thể dự đoán ai sẽ thắng không?
Mô hình chỉ trả lời một từ: Có.
Sau đó, nó đã dự đoán chính xác 99 trong 116 trận đấu tại Giải Úc mở rộng năm nay, tỷ lệ chính xác lên tới 85%!
Đây là những trận đấu mà mô hình chưa từng gặp trong quá trình huấn luyện, vậy mà nó còn dự đoán đúng cả từng trận thắng của nhà vô địch cuối cùng.

Tất cả chỉ dùng một chiếc laptop, dữ liệu miễn phí và mã nguồn mở, do @theGreenCoding sáng tạo.
Tiếp theo, tôi sẽ phân tích toàn diện dự án biến đổi này, từ dữ liệu gốc đến thành công trong dự đoán cuối cùng. Đây sẽ là ví dụ về AI + dự đoán thành công ấn tượng nhất mà bạn từng thấy.
Bước khởi đầu: Thư mục chứa dữ liệu quần vợt 43 năm
Câu chuyện bắt đầu từ một bộ dữ liệu được gọi là “Chén Thánh dữ liệu thể thao”.
Bộ dữ liệu này bao gồm các ghi chép về mọi trận đấu chuyên nghiệp của ATP (Hiệp hội quần vợt nhà nghề nam) từ năm 1985 đến 2024.
Các số liệu như điểm break, lỗi kép, cú thuận, trái, chiều cao, tuổi, thứ hạng, lịch sử đối đầu, sân đấu… tất cả các dữ liệu thống kê từng điểm trong suốt 40 năm đều có đủ.
Tổng cộng là hàng chục nghìn file CSV, tất cả nằm trong một thư mục.
Khi người này mở toàn bộ dữ liệu ra, máy tính đã bị treo ngay lập tức.
Nhưng anh không bỏ cuộc. Với 95.491 trận đấu trong bộ dữ liệu, anh đã tính thêm hàng loạt đặc trưng phái sinh:
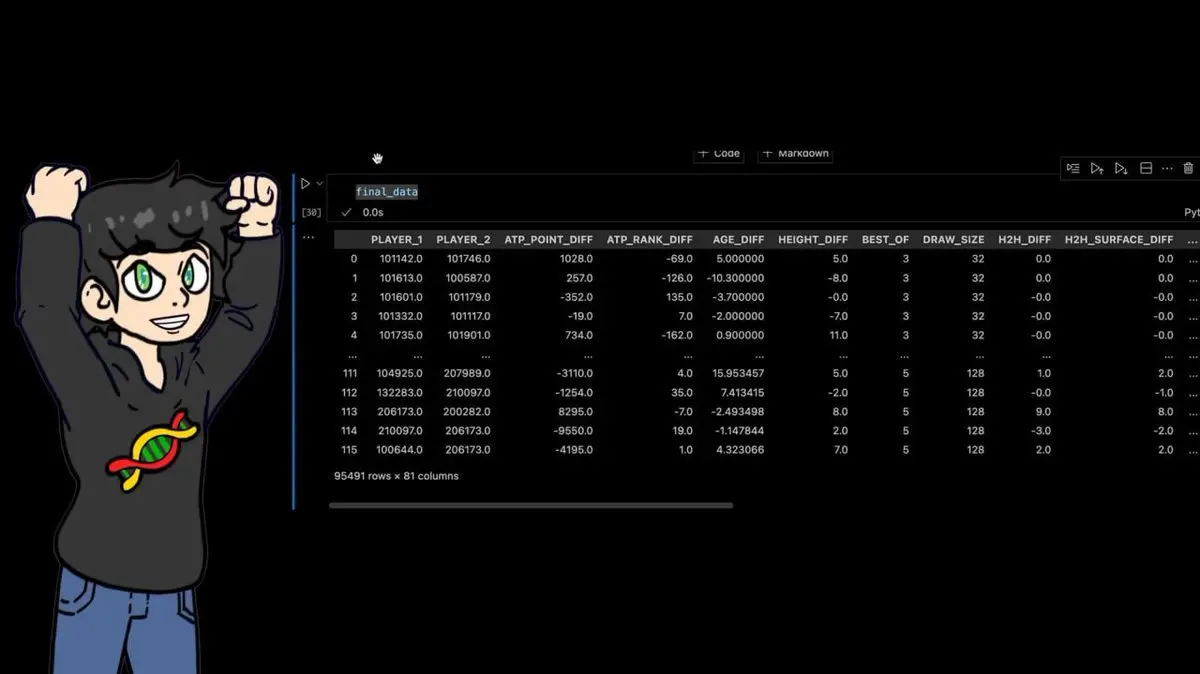
- Lịch sử đối đầu giữa hai vận động viên
- Chênh lệch tuổi, chiều cao
- Tỷ lệ thắng trong 10, 25, 50, 100 trận gần nhất
- Chênh lệch tỷ lệ điểm thắng một phát giao bóng
- Chênh lệch tỷ lệ cứu điểm break
- Hệ thống xếp hạng ELO tùy chỉnh lấy cảm hứng từ cờ vua (điểm mấu chốt)
Kết quả cuối cùng: 95.491 dòng × 81 cột.
Mỗi trận đấu trong 40 năm qua, đi kèm hàng chục đặc trưng tính thủ công.
Bước hai: Mô phỏng thuật toán lấy cảm hứng từ Titanic

Trước khi đưa dữ liệu vào bộ phân loại, anh quyết định hiểu rõ nguyên lý hoạt động của thuật toán. Để làm điều này, anh tự viết một cây quyết định từ đầu bằng numpy.
Cây quyết định hoạt động như một trò chơi suy luận — qua một loạt câu hỏi, dần dần đi đến kết quả.
Để minh họa, anh chọn một bộ dữ liệu hoàn toàn khác: Titanic.
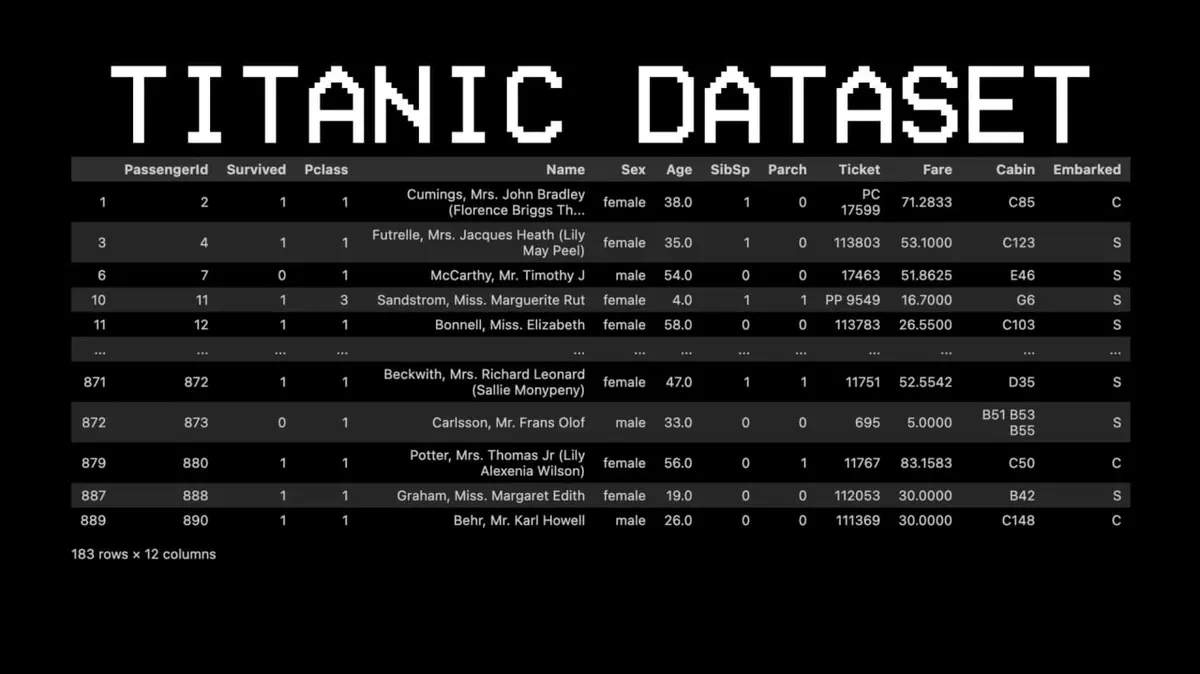
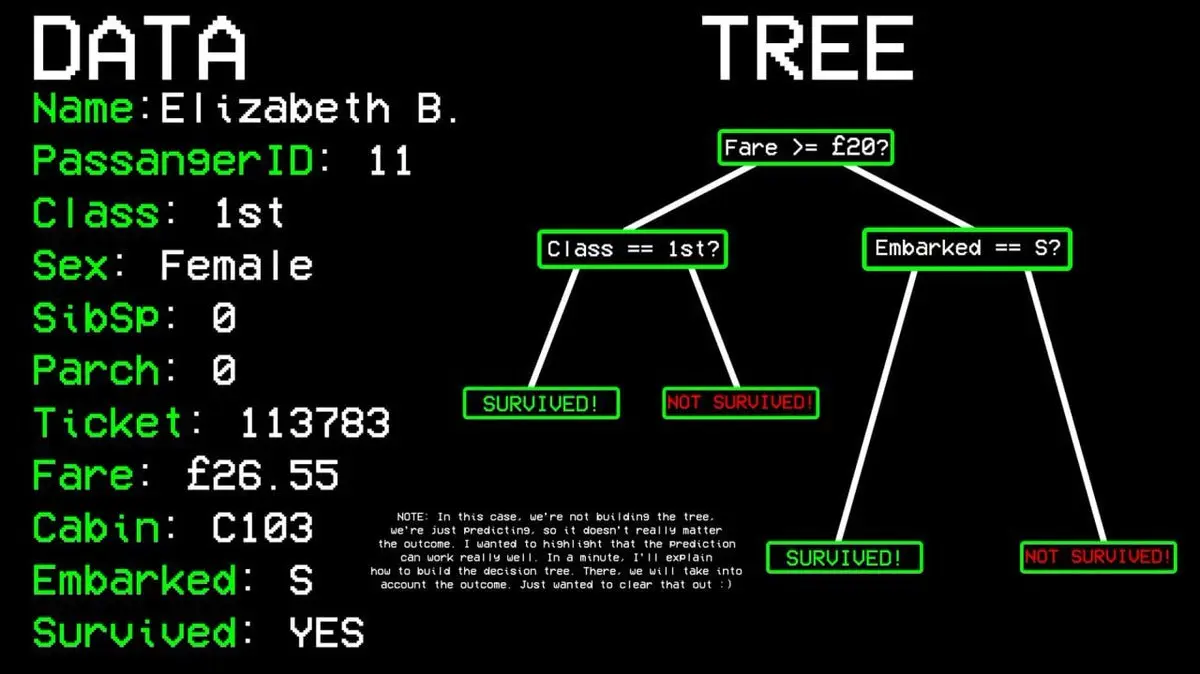
Ví dụ: hành khách số 11 có sống sót không?
- Câu hỏi 1: Người đó có đi khoang hạng nhất không? → Có.
- Câu hỏi 2: Người đó có phải là nữ không? → Có.
- Kết luận: Sống sót.
Thuật toán quyết định hỏi câu nào dựa trên điều gì?
Nó bắt đầu từ tất cả dữ liệu, tìm ra biến đơn nhất phân biệt rõ nhất giữa “sống sót” và “không sống sót”. Trong dữ liệu Titanic, câu trả lời là hạng khoang. Hành khách khoang nhất đi một hướng, các hạng khác đi hướng khác.
Tuy nhiên, vẫn có trường hợp hạng nhất gặp nạn, nên dữ liệu chưa hoàn toàn “sạch”. Thuật toán tiếp tục tìm kiếm điểm phân chia tốt nhất tiếp theo, đó là giới tính. Tất cả nữ trong khoang nhất đều sống sót, tạo thành “nút sạch”, phân nhánh dừng lại.
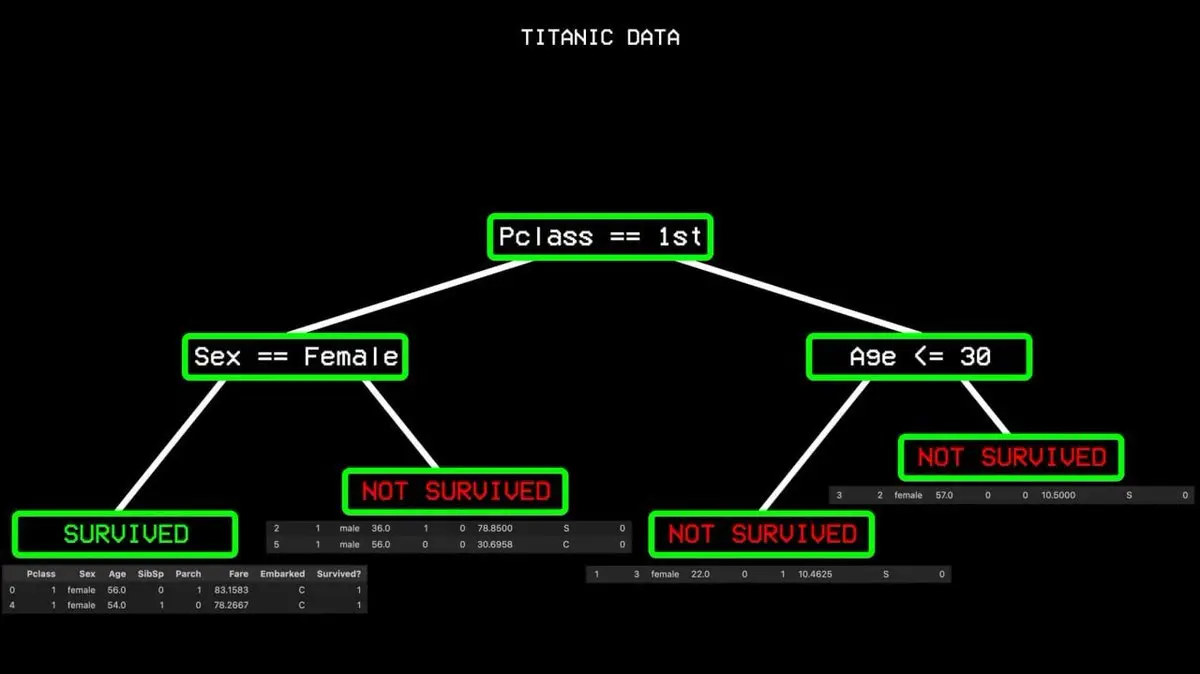
Quá trình này lặp đi lặp lại cho đến khi xây dựng được một cây quyết định hoàn chỉnh, bao phủ mọi tình huống.
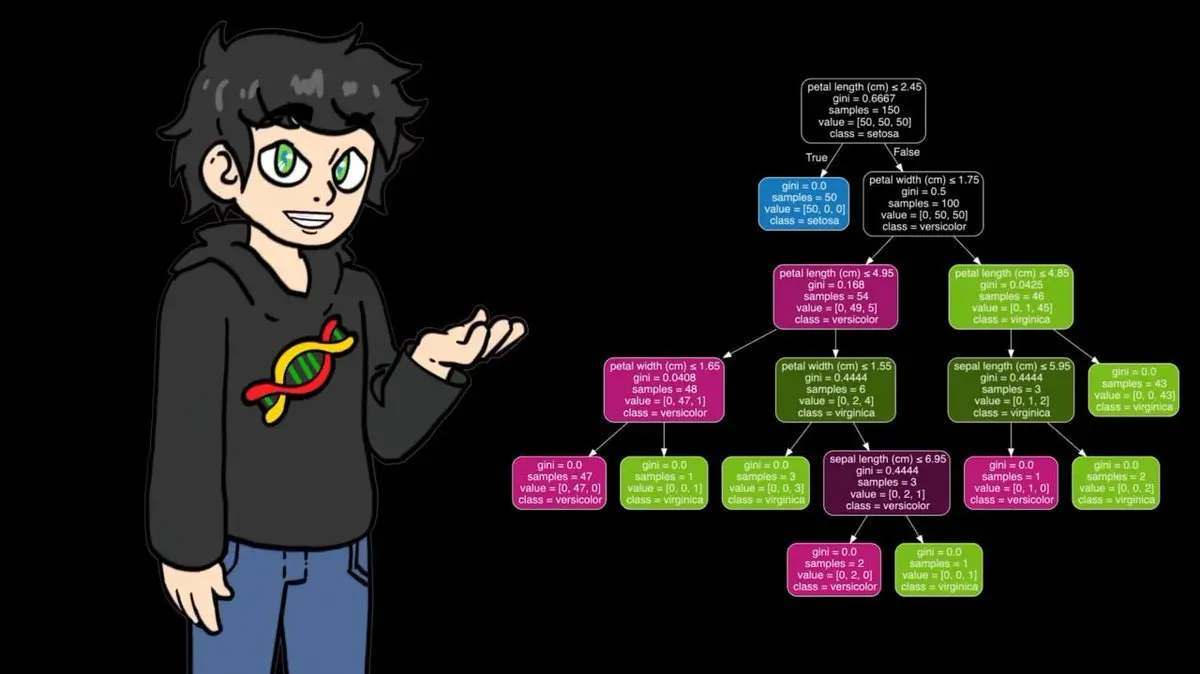
Phiên bản tự viết bằng numpy của anh hoạt động tốt trên dữ liệu nhỏ, nhưng khi áp dụng vào 95.000 trận đấu quần vợt, tốc độ quá chậm khiến máy gần như đứng hình. Vì vậy, trong giai đoạn huấn luyện chính thức, anh chuyển sang dùng phiên bản tối ưu của sklearn, cùng logic nhưng nhanh hơn nhiều.
Bước ba: Tìm ra biến quyết định thắng thua
Trước khi huấn luyện mô hình, anh vẽ tất cả các biến thành một ma trận scatter plot khổng lồ (SNS pairplot), để tìm ra quy luật phân biệt người thắng và người thua.

Hầu hết các đặc trưng đều là nhiễu. ID vận động viên rõ ràng không hữu ích. Tỷ lệ thắng chênh lệch có chút quy luật, nhưng chưa đủ rõ ràng để làm mô hình phân loại đáng tin cậy.
Chỉ có một biến vượt trội so với các biến khác: chênh lệch ELO (ELO_DIFF).
Biểu đồ scatter của ELO_DIFF và ELO_SURFACE_DIFF cho thấy rõ ràng sự phân tách giữa hai loại. Các đặc trưng khác không thể sánh kịp.
Phát hiện này đã thúc đẩy anh xây dựng phần cốt lõi nhất của toàn bộ dự án.
Bước bốn: Áp dụng hệ thống xếp hạng cờ vua vào quần vợt
ELO là một hệ thống đánh giá trình độ kỹ năng của vận động viên, ban đầu dùng trong cờ vua. Hiện tại, cao thủ số một thế giới Magnus Carlsen có điểm 2833.

Anh quyết định áp dụng hệ thống này vào quần vợt:
- Điểm khởi đầu mỗi vận động viên: 1500
- Thắng: điểm tăng; thua: điểm giảm
Cơ chế chính: số điểm thắng hay thua phụ thuộc vào chênh lệch điểm với đối thủ. Thắng đối thủ có điểm cao hơn, điểm tăng nhiều; thua đối thủ điểm thấp hơn, mất nhiều điểm.
Anh dùng trận chung kết Wimbledon 2023 để minh họa công thức này: Carlos Alcaraz (điểm 2063) gặp Novak Djokovic (điểm 2120), Alcaraz lội ngược dòng vô địch.

Thay số vào công thức: Alcaraz +14 điểm, Djokovic -14 điểm.
Dễ tính toán, nhưng khi áp dụng vào dữ liệu 43 năm, hiệu quả cực kỳ ấn tượng.
Bước năm: Minh họa sức mạnh của “bộ ba huyền thoại”
Anh vẽ biểu đồ ELO của Federer qua toàn bộ sự nghiệp, từ khi bắt đầu thi đấu đến khi giải nghệ, từng trận một.
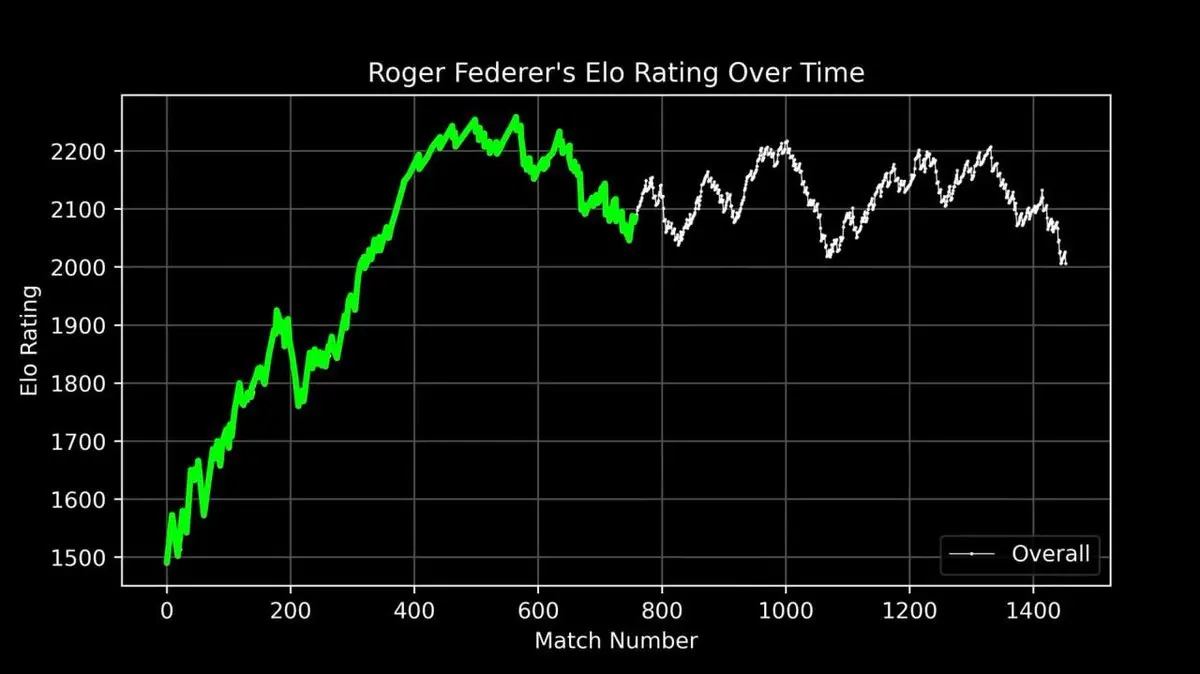
Đường cong này thể hiện rõ một huyền thoại: sự tăng tốc ban đầu, thời kỳ đỉnh cao (khoảng trận thứ 400 trở đi) với sự thống trị tuyệt đối, rồi những biến động sau đó.
Nhưng điều thực sự gây ấn tượng là khi anh so sánh Federer với tất cả các tay vợt ATP từ 1985 đến nay:
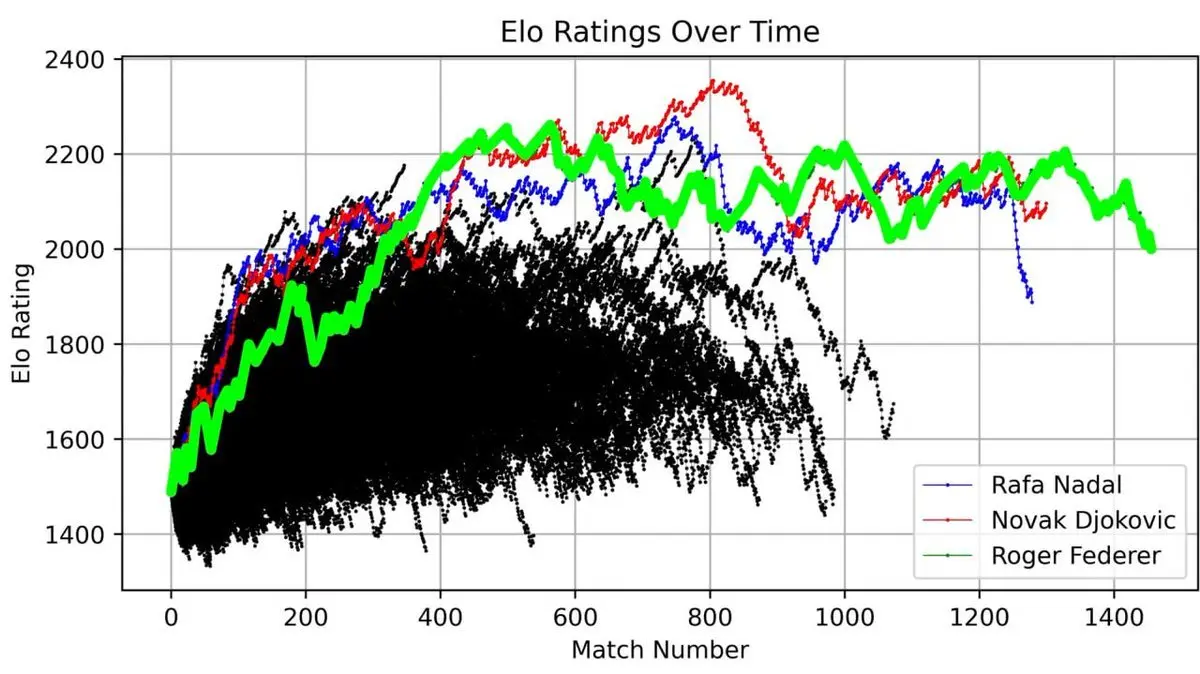
Ba đường cong cao vút, vượt xa tất cả các đối thủ khác — Federer (xanh lá), Nadal (xanh dương), Djokovic (đỏ).
“Bộ ba huyền thoại Grand Slam” không chỉ là danh xưng. Khi hình dung dữ liệu 40 năm thi đấu, ta thấy rõ sức thống trị này trong toán học.
Dựa trên hệ thống ELO tùy chỉnh của anh, hiện tại tay vợt số một thế giới là Jannik Sinner (2176 điểm), tiếp theo là Djokovic (2096) và Alcaraz (2003).

Nhớ rõ vị trí số một của Sinner, điều này sẽ rất quan trọng sau này.
Bước sáu: Sân đấu là biến số thay đổi tất cả
Các loại sân đấu trong quần vợt hoàn toàn thay đổi diện mạo môn thể thao này:
- Đất nện: chậm, bóng nảy cao
- Cỏ: nhanh, bóng nảy thấp
- Cứng: trung bình
Vận động viên xuất sắc trên sân này có thể hoàn toàn thất bại trên sân khác.
Vì vậy, anh xây dựng hệ thống ELO riêng cho từng loại sân: đất nện, cỏ, cứng.
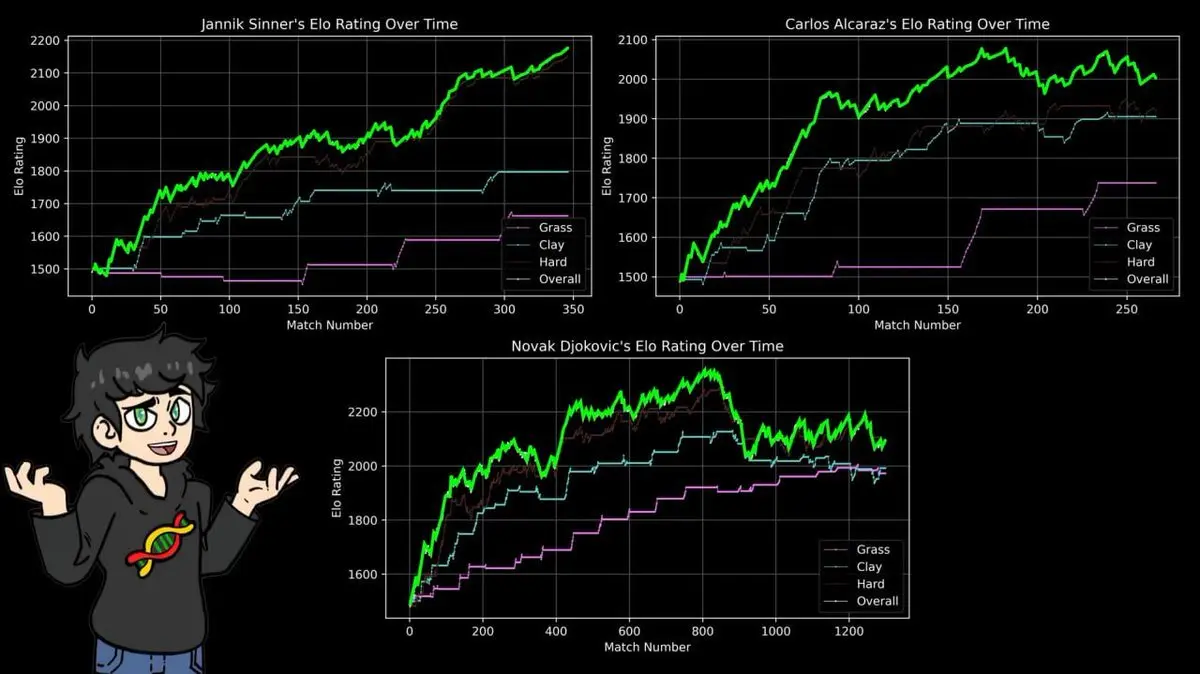
Kết quả chứng minh điều mà mọi người chơi quần vợt đều biết, và dựa trên dữ liệu 43 năm:
Chỉ số ELO của Nadal trên đất nện cao hơn hẳn Federer trên cỏ, cao hơn Djokovic trên cứng, vượt xa mọi kỷ lục cá nhân trong lịch sử.
14 danh hiệu Roland Garros, 112 thắng - 4 thua.
Hệ thống ELO không quan tâm đến câu chuyện, danh tiếng, nó chỉ xử lý kết quả thắng thua. Và kết quả của nó hoàn toàn phù hợp với các báo cáo thể thao 40 năm qua.
Bước bảy: Gặp giới hạn
Sau khi chuẩn bị dữ liệu xong, hệ thống ELO hoàn chỉnh, anh bắt đầu huấn luyện bộ phân loại. Quá trình này thể hiện rõ tầm quan trọng của việc chọn thuật toán.
Cây quyết định: độ chính xác 74%
Một cây quyết định trên toàn bộ dữ liệu đạt độ chính xác 74%. Nghe có vẻ ổn — cho đến khi anh biết rằng, chỉ dựa vào chênh lệch ELO để dự đoán thắng thua đã đạt 72%.
Cây quyết định dựa trên hệ thống xếp hạng thủ công của anh gần như không mang lại gì thêm.
Rừng ngẫu nhiên (Random Forest): độ chính xác 76%
Vấn đề của cây đơn là “ph variance cao” — quá nhạy cảm với dữ liệu con trong quá trình huấn luyện. Giải pháp tiêu chuẩn là rừng ngẫu nhiên: xây dựng hàng chục, hàng trăm cây, mỗi cây dùng dữ liệu và đặc trưng ngẫu nhiên khác nhau, rồi bỏ phiếu đa số.

94 cây quyết định khác nhau cùng bỏ phiếu cho mỗi trận đấu.

Kết quả: 76%. Có tiến bộ, nhưng anh đã chạm giới hạn. Dù điều chỉnh hyperparameter, thiết kế lại đặc trưng, hay thay đổi dữ liệu, độ chính xác vẫn không vượt quá 77%.
Bước tám: Vượt qua giới hạn
Tiếp đó, anh thử XGBoost — gọi là “phiên bản steroid của rừng ngẫu nhiên”.
Điểm khác biệt chính: rừng ngẫu nhiên xây dựng các cây song song, trung bình kết quả; XGBoost xây dựng từng cây theo chuỗi, mỗi cây sửa lỗi của tất cả cây trước đó. Nó còn có cơ chế regularization để tránh overfitting, giữ các cây nhỏ, không học thuộc lòng dữ liệu.
Kết quả: độ chính xác 85%.
So với giới hạn 76% của rừng ngẫu nhiên, đây là bước đột phá lớn. Dữ liệu giống nhau, đặc trưng giống nhau, chỉ khác thuật toán.
XGBoost cũng xác định ba đặc trưng quan trọng nhất là: chênh lệch ELO, chênh lệch ELO theo sân, tổng thể ELO. Hệ thống xếp hạng lấy cảm hứng từ cờ vua này trong 81 đặc trưng đã chứng minh là yếu tố dự đoán mạnh nhất.
Để so sánh, anh còn huấn luyện một mạng neural trên cùng dữ liệu, đạt độ chính xác 83%. Tốt, nhưng vẫn thua XGBoost. Trong bộ dữ liệu này, phương pháp dựa trên cây thắng thế.
Bước chín: Trận quyết định – Giải Úc mở rộng 2025
Tất cả dữ liệu này đều dựa trên huấn luyện trước tháng 12 năm 2024.
Giải Úc mở rộng 2025 diễn ra tháng 1, hoàn toàn không có trong dữ liệu huấn luyện, trở thành thử thách hoàn hảo: mô hình đã nắm rõ quy luật của quần vợt hay chỉ biết “ghi nhớ” mô hình lịch sử?

Anh nhập toàn bộ lịch thi đấu vào mô hình, để dự đoán từng trận.
Kết quả: trong 116 trận, dự đoán đúng 99 trận, sai 17 trận. Tỷ lệ chính xác 85,3%.
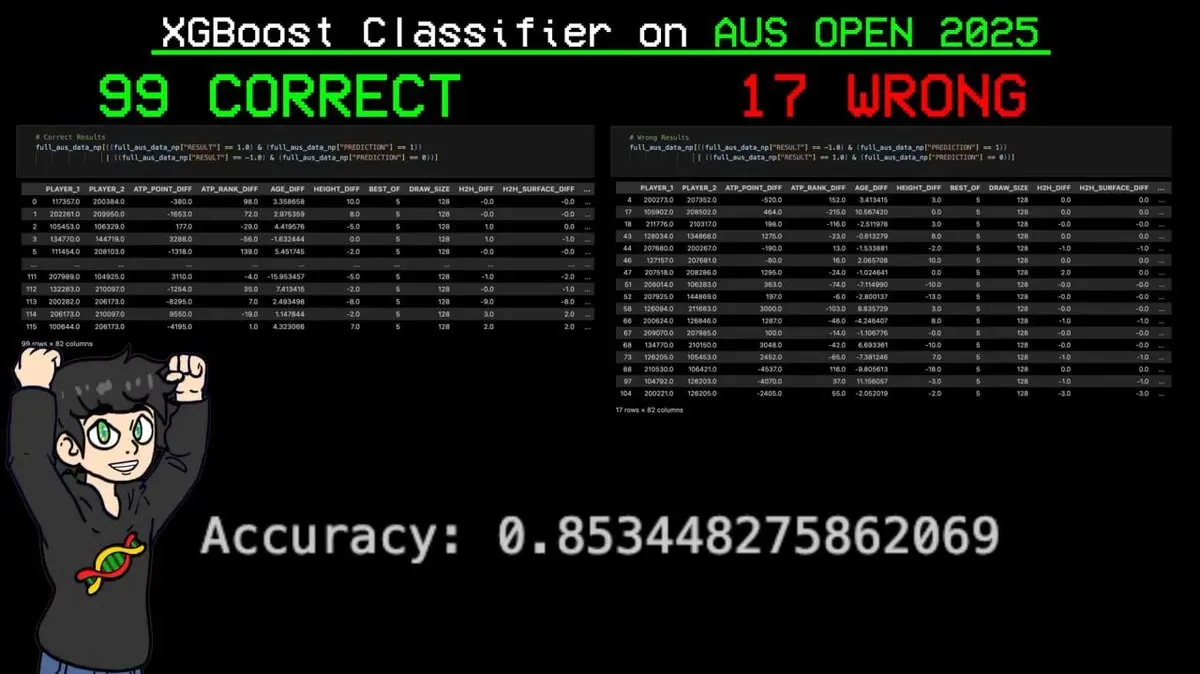
Điều quan trọng nhất: mô hình dự đoán chính xác mọi trận thắng của Sinner (vị trí số 1 thế giới theo hệ thống ELO).
Trước khi bóng chạm sân, AI đã dự đoán ra nhà vô địch Grand Slam.
Kết luận
Chỉ với một người, một chiếc laptop, không có dữ liệu riêng, không hạ tầng đắt đỏ, không nhóm nghiên cứu — đã xây dựng thành công một mô hình dự đoán quần vợt chuyên nghiệp với độ chính xác 85%, và dự đoán ra nhà vô địch trước khi giải đấu bắt đầu.
Dữ liệu quần vợt có sẵn trên GitHub, hoàn toàn có thể tái tạo.
Phép màu chưa bao giờ dễ dàng đến thế như ngày hôm nay.
Khoảng cách thực sự không nằm ở nguồn lực, mà ở chỗ bạn có sẵn sàng làm hay không.