OpenAI 发布 GPT-5.4 Mini 和 Nano,可能比大模型更实用
Decrypt
简要介绍
- OpenAI 推出了 GPT-5.4 Mini 和 Nano,这两款模型速度更快、成本更低,专为高容量AI工作负载设计。
- 这些模型在速度和成本上牺牲了一些准确性,目标任务包括重复性和简单任务,如客户支持和自动化工作流程。
- 开发者现在可以运行混合AI系统,由旗舰模型规划任务,而较小的模型处理大部分工作。
OpenAI 并未放慢脚步。在推出 GPT-5.4 不到两周后——该模型在 GPT-5.3 发布两天后才问世——公司在周二又推出了两款新模型:GPT-5.4 Mini 和 GPT-5.4 Nano。 这些并不是旗舰模型的简化版本——它们是为那些等待半分钟得到答案都无法接受的工作场景量身定制的专用机器。 OpenAI 称它们为“迄今为止最强的小型模型”,并表示 GPT-5.4 Mini 的速度比 GPT-5 Mini 快两倍多。如果你曾经看过一个编码助手在编辑三行代码前思考45秒,你就会理解快速模型的吸引力。
我们推出了 GPT-5.4 mini 和 nano,这是我们迄今为止最强的小型模型。
GPT-5.4 mini 的速度比 GPT-5 mini 快两倍以上。优化用于编码、计算机使用、多模态理解和子代理。
对于较轻量的任务,GPT-5.4 nano 是我们最小、最便宜的…… pic.twitter.com/cdp5HWtM2M
— OpenAI 开发者 (@OpenAIDevs) 2026年3月17日
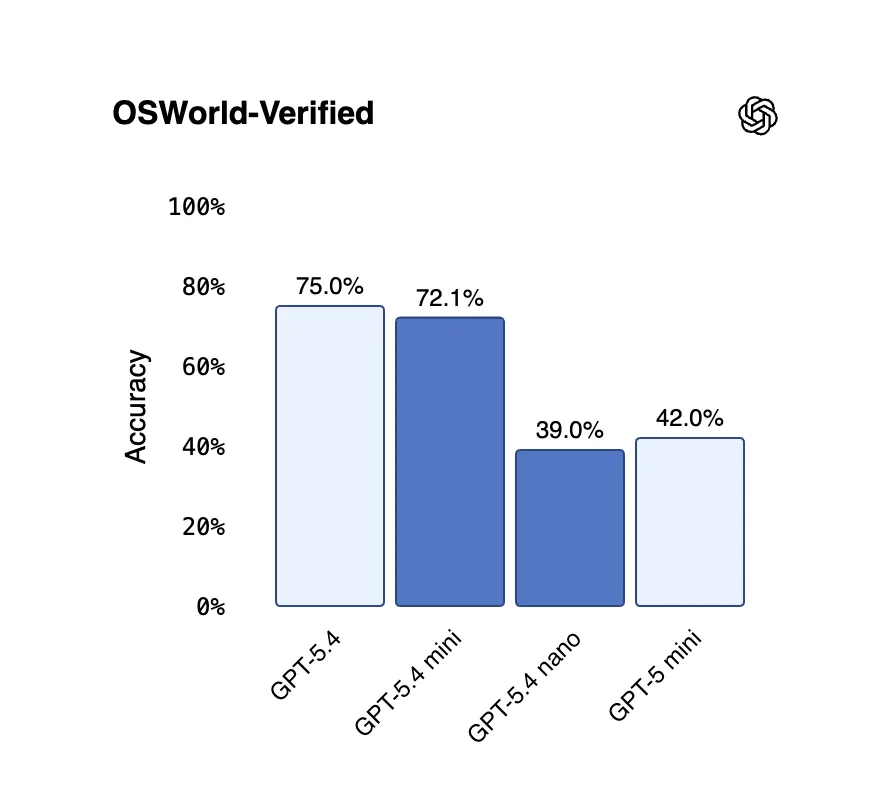
那么,为什么有人会故意发布准确率较低的模型呢?简短的答案:因为准确性并不总是瓶颈。如果你运行一个每天回答200个相同问题的客户服务聊天机器人,你并不需要在博士级化学考试中得分最高的模型。你需要的是响应速度在一秒以内、每次回复成本不到一分钱的模型。这正是这些模型的设计空间。 但这并不意味着这些模型愚蠢或不可靠。在编码基准测试中,GPT-5.4 Mini 在 SWE-Bench Pro(衡量模型修复 GitHub 实际问题能力的测试)中得分54.4%,而旧的 GPT-5 Mini 得分45.7%,完整的 GPT-5.4 则得分57.7%。 在 OSWorld-Verified 测试中,该测试评估模型通过读取截图实际操作桌面电脑的能力,Mini 得分72.1%,仅次于旗舰的75.0%,且都超过了人类基线72.4%。而 GPT-5.4 Nano 在 SWE-Bench Pro 上得分52.4%,在 OSWorld上得分39.0%,低于 Mini,但仍比之前的 Nano 级模型有大幅提升。
“GPT-5.4 在我们的内部评估中标志着 Mini 和 Nano 模型的一个进步,”Perplexity 副 CTO 马杰瑞(Jerry Ma)在测试后表示,“Mini 提供了强大的推理能力,而 Nano 在实时对话工作流程中响应迅速且高效。” 不必将每个任务都通过昂贵的旗舰模型处理,你现在可以构建系统,让大模型负责规划和协调,而较小的模型并行处理实际繁重的工作——搜索代码库、阅读文档或处理表单。正如我们在 GPT-5.4 与 Grok 4.20 的对比中看到的,模型在工作流程中的位置与选择哪个模型一样重要。
GPT-5.4 Mini 通过API的输入每百万个令牌收费0.75美元,输出每百万个令牌收费4.50美元。GPT-5.4 Nano 更便宜:每百万输入令牌0.20美元,每百万输出令牌1.25美元——这个价格点让创业公司每天处理大量查询变得经济可行。作为对比,Nano 在输入方面大约比 Mini 便宜四倍。 对于普通的 ChatGPT 用户,GPT-5.4 Mini 今天可以通过 Plus 菜单中的“思考”选项向免费和 Go 用户提供。付费订阅用户达到 GPT-5.4 的使用限制后,将自动切换到 Mini。而 GPT-5.4 Nano 目前仅提供API——OpenAI 明确将其定位为开发者工具,而非面向消费者。
免责声明:本页面信息可能来自第三方,不代表 Gate 的观点或意见。页面显示的内容仅供参考,不构成任何财务、投资或法律建议。Gate 对信息的准确性、完整性不作保证,对因使用本信息而产生的任何损失不承担责任。虚拟资产投资属高风险行为,价格波动剧烈,您可能损失全部投资本金。请充分了解相关风险,并根据自身财务状况和风险承受能力谨慎决策。具体内容详见声明。
评论
0/400
暂无评论