Gate广场_Official
Gate Alpha 热币交易赛第 24 期正式开启!
💰 瓜分 $50,000 奖金池!
📌 本期热币:
VEREM(BNB Chain)@VeremOrg
🎯 三重奖励限时抢:
✅ 单日交易 ≥ 200 USDT,连续 3 天及以上可参与瓜分 600 VEREM
✅ 冲刺交易奖励,先到先得:
• 买入 + 卖出 ≥ $800 → 0.62 VEREM
• 买入 + 卖出 ≥ $1,500 → 1.25 VEREM
• 买入 + 卖出 ≥ $3,000 → 2.7 VEREM
✅ 累计交易 ≥ 5000 USDT,按交易量占比参与 1551 VEREM 奖池瓜分,最高赢 6.2 VEREM
📅 活动时间:3 月 6 日 20:00 - 3 月 13 日 20:00 (UTC+8)
👉 立即参与:https://www.gate.com/campaigns/4211Alpha?pid=X&c=MemeBox&ch=RBJdHyAM
💰 瓜分 $50,000 奖金池!
📌 本期热币:
VEREM(BNB Chain)@VeremOrg
🎯 三重奖励限时抢:
✅ 单日交易 ≥ 200 USDT,连续 3 天及以上可参与瓜分 600 VEREM
✅ 冲刺交易奖励,先到先得:
• 买入 + 卖出 ≥ $800 → 0.62 VEREM
• 买入 + 卖出 ≥ $1,500 → 1.25 VEREM
• 买入 + 卖出 ≥ $3,000 → 2.7 VEREM
✅ 累计交易 ≥ 5000 USDT,按交易量占比参与 1551 VEREM 奖池瓜分,最高赢 6.2 VEREM
📅 活动时间:3 月 6 日 20:00 - 3 月 13 日 20:00 (UTC+8)
👉 立即参与:https://www.gate.com/campaigns/4211Alpha?pid=X&c=MemeBox&ch=RBJdHyAM
BNB-1.14%

- 赞赏
- 2
- 评论
- 转发
- 分享
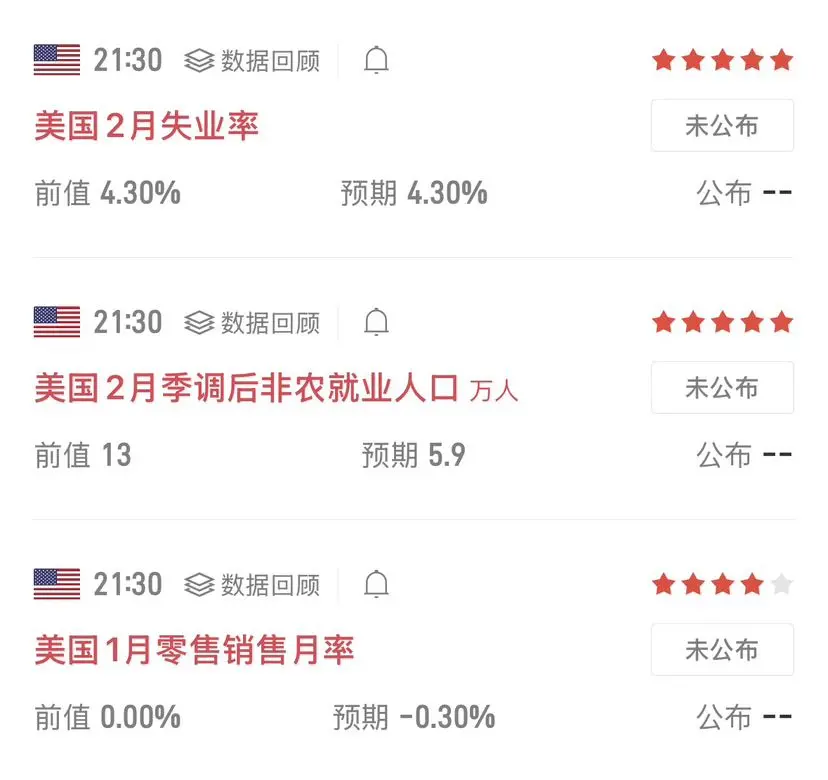
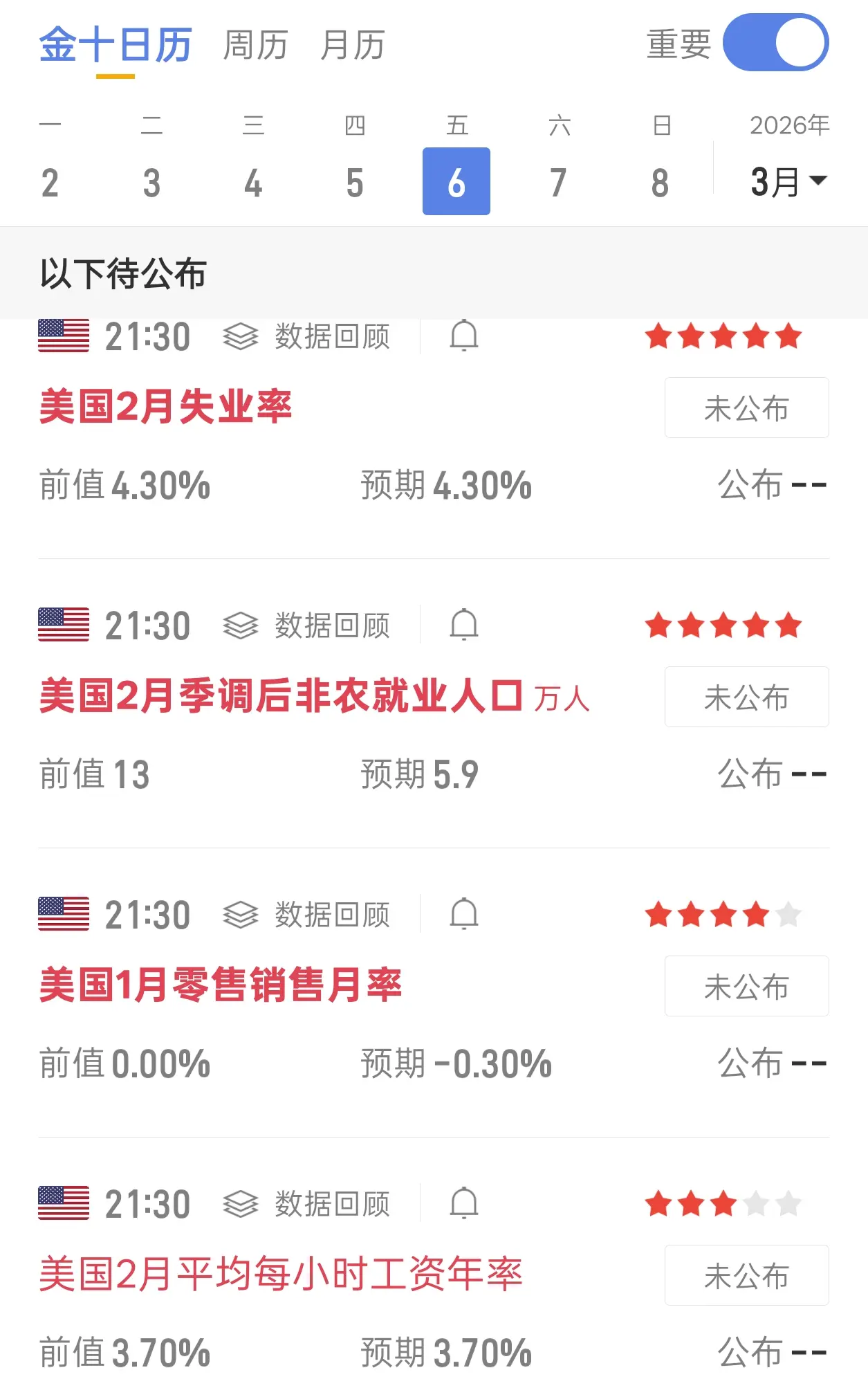
今晚市场将迎来大非农数据,这是今天的重点关注。考虑到本周公布的ADP和初请数据均对币价构成利空,晚间非农数据大概率好于预期。
一旦数据表现强劲,美联储3月降息的概率可能直接归零,甚至6月的降息预期也会有所降温。这种预期变化通常会推动美元走强、美债收益率上行,进而引发资金从大饼等风险资产中流出,对币价形成压制。因此,如果打算在今晚布局低多,建议还是要保持谨慎。
从盘面来看,如果白盘继续维持震荡走势,晚间需要警惕一种可能性:行情快速拉高制造“诱多”效应,随后反转向下,走出瀑布行情。
大饼71500–72800的诱多拉涨行为后瀑布!方向最后都是向下!目标咱们看68500!
姨太2100–2140的诱多拉升行为后瀑布! 方向最后都是向下!目标咱们看1980!
$BTC $ETH $SOL #美伊局势影响 #非农就业前瞻 #美国初请失业金人数逊预期 #全球央行降息预期全线降温
一旦数据表现强劲,美联储3月降息的概率可能直接归零,甚至6月的降息预期也会有所降温。这种预期变化通常会推动美元走强、美债收益率上行,进而引发资金从大饼等风险资产中流出,对币价形成压制。因此,如果打算在今晚布局低多,建议还是要保持谨慎。
从盘面来看,如果白盘继续维持震荡走势,晚间需要警惕一种可能性:行情快速拉高制造“诱多”效应,随后反转向下,走出瀑布行情。
大饼71500–72800的诱多拉涨行为后瀑布!方向最后都是向下!目标咱们看68500!
姨太2100–2140的诱多拉升行为后瀑布! 方向最后都是向下!目标咱们看1980!
$BTC $ETH $SOL #美伊局势影响 #非农就业前瞻 #美国初请失业金人数逊预期 #全球央行降息预期全线降温

- 赞赏
- 1
- 评论
- 转发
- 分享
#NonfarmPayrollsPreview
非农就业数据预览成为焦点。
很少有经济指标能像美国非农就业报告一样持续影响全球市场。每一次发布都提供了劳动力市场健康状况、招聘势头以及美国经济整体方向的有力快照。
在下一份报告发布之前,投资者、政策制定者和交易者都在密切关注预期。
非农就业数据反映了除农业部门外,美国经济中新增的就业岗位数。由于就业与消费者支出、通胀压力和经济增长密切相关,这一数据点常常影响利率预期和市场布局。
在当前环境下,中央银行对通胀和降息保持谨慎,劳动力市场信号的权重更大。
如果报告好于预期,可能会强化经济依然韧性的观点,延迟降息的可能性增加。若数据低于预期,则可能加强未来几个月政策宽松的理由。
任何结果都可能迅速改变市场情绪。
为什么这很重要
非农就业是最具市场影响力的经济指标之一
劳动力市场的强劲程度直接影响利率预期
股市、货币和加密市场常常对数据发布做出反应
投资者利用该报告评估整体经济动能
对于全球市场来说,非农就业报告不仅仅是每月的统计数据。
它是塑造下一步货币政策和市场策略的重要信号。
查看原文非农就业数据预览成为焦点。
很少有经济指标能像美国非农就业报告一样持续影响全球市场。每一次发布都提供了劳动力市场健康状况、招聘势头以及美国经济整体方向的有力快照。
在下一份报告发布之前,投资者、政策制定者和交易者都在密切关注预期。
非农就业数据反映了除农业部门外,美国经济中新增的就业岗位数。由于就业与消费者支出、通胀压力和经济增长密切相关,这一数据点常常影响利率预期和市场布局。
在当前环境下,中央银行对通胀和降息保持谨慎,劳动力市场信号的权重更大。
如果报告好于预期,可能会强化经济依然韧性的观点,延迟降息的可能性增加。若数据低于预期,则可能加强未来几个月政策宽松的理由。
任何结果都可能迅速改变市场情绪。
为什么这很重要
非农就业是最具市场影响力的经济指标之一
劳动力市场的强劲程度直接影响利率预期
股市、货币和加密市场常常对数据发布做出反应
投资者利用该报告评估整体经济动能
对于全球市场来说,非农就业报告不仅仅是每月的统计数据。
它是塑造下一步货币政策和市场策略的重要信号。


- 赞赏
- 3
- 2
- 转发
- 分享
Crypto_Buzz_with_Alex :
:
🚀 “下一阶段的能量到来了——可以感觉到势头正在增强!”查看更多
PI
PI
创建人@GateUser-d04ebb81
上市进度
0.00%
市值:
$0.1
更多代币
- 赞赏
- 点赞
- 评论
- 转发
- 分享
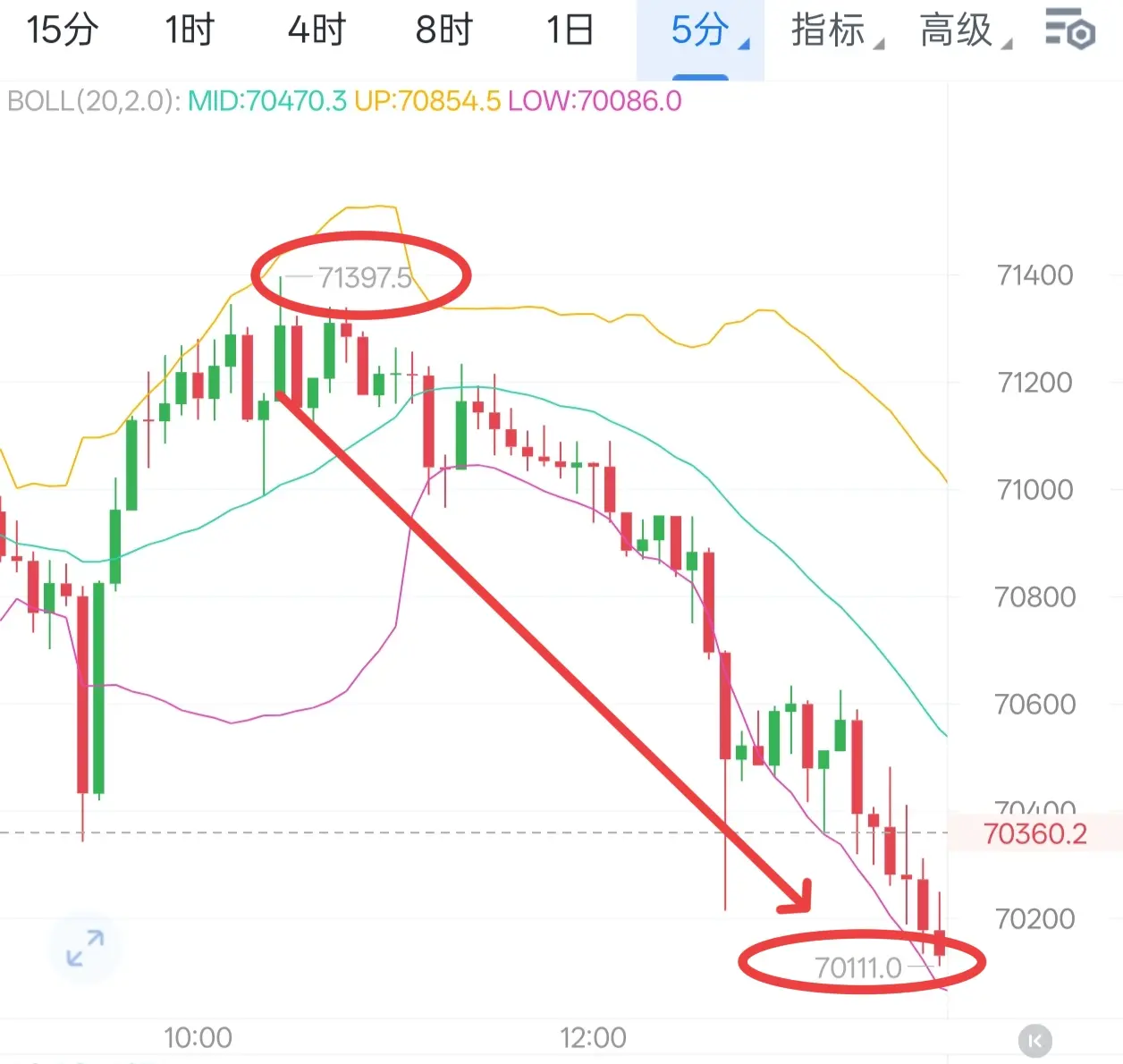
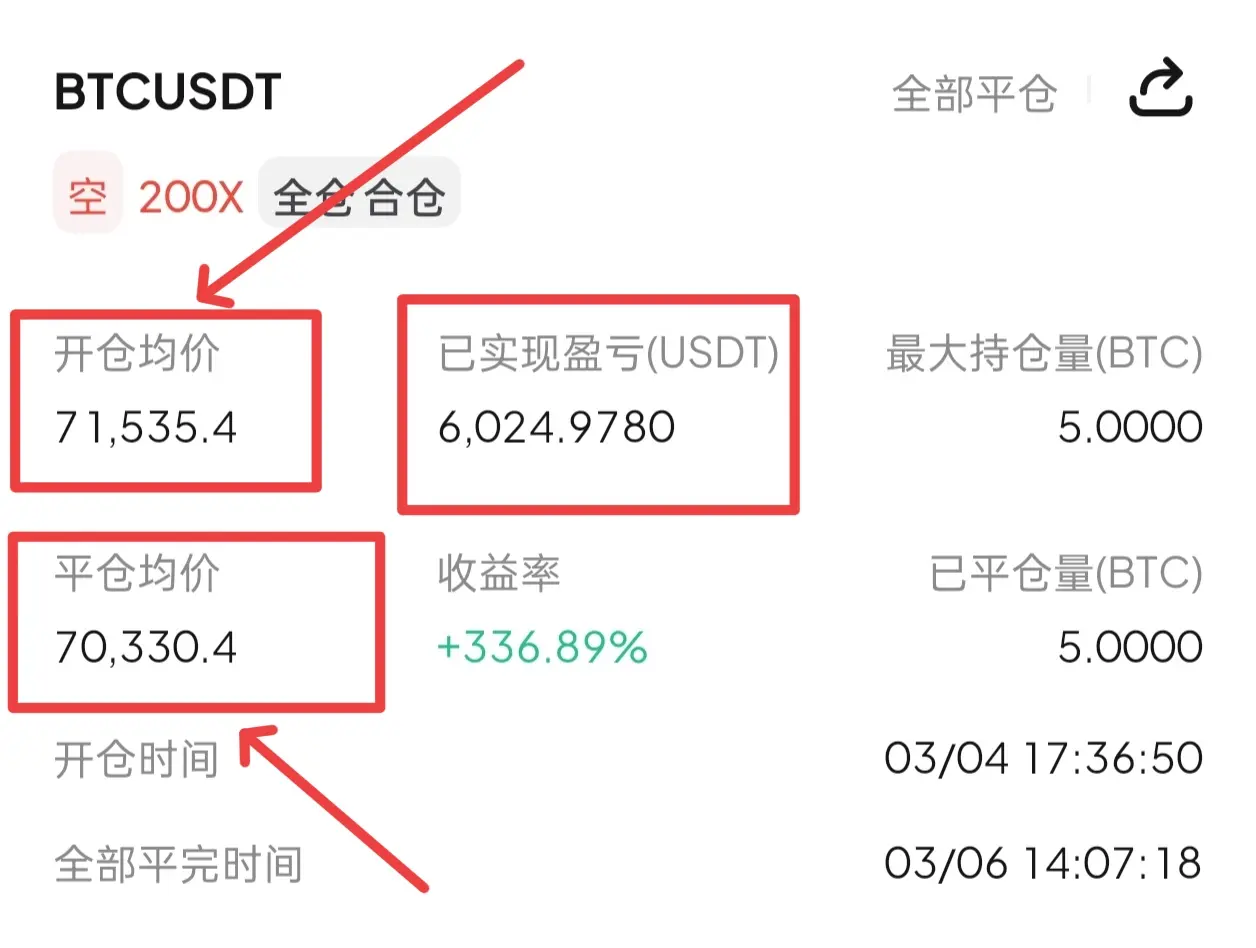
坚定看箜丝路完美落地,早间从高碘71397一路下探70111,走出1286下行箜间
我们在前期在71535附近开舱,于70330附近全部平舱,拿下6024油!
我们在前期在71535附近开舱,于70330附近全部平舱,拿下6024油!
- 赞赏
- 点赞
- 评论
- 转发
- 分享

- 赞赏
- 点赞
- 评论
- 转发
- 分享
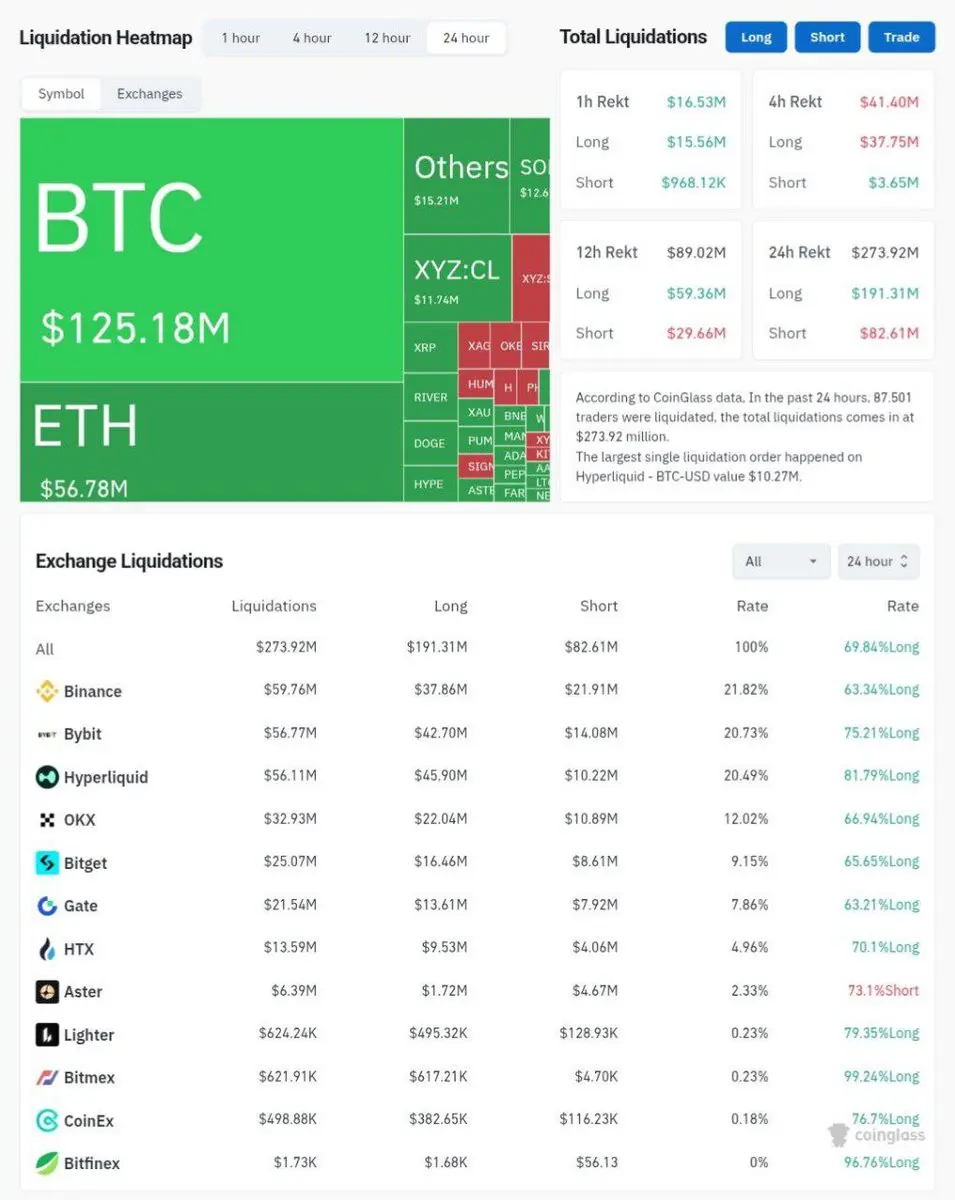
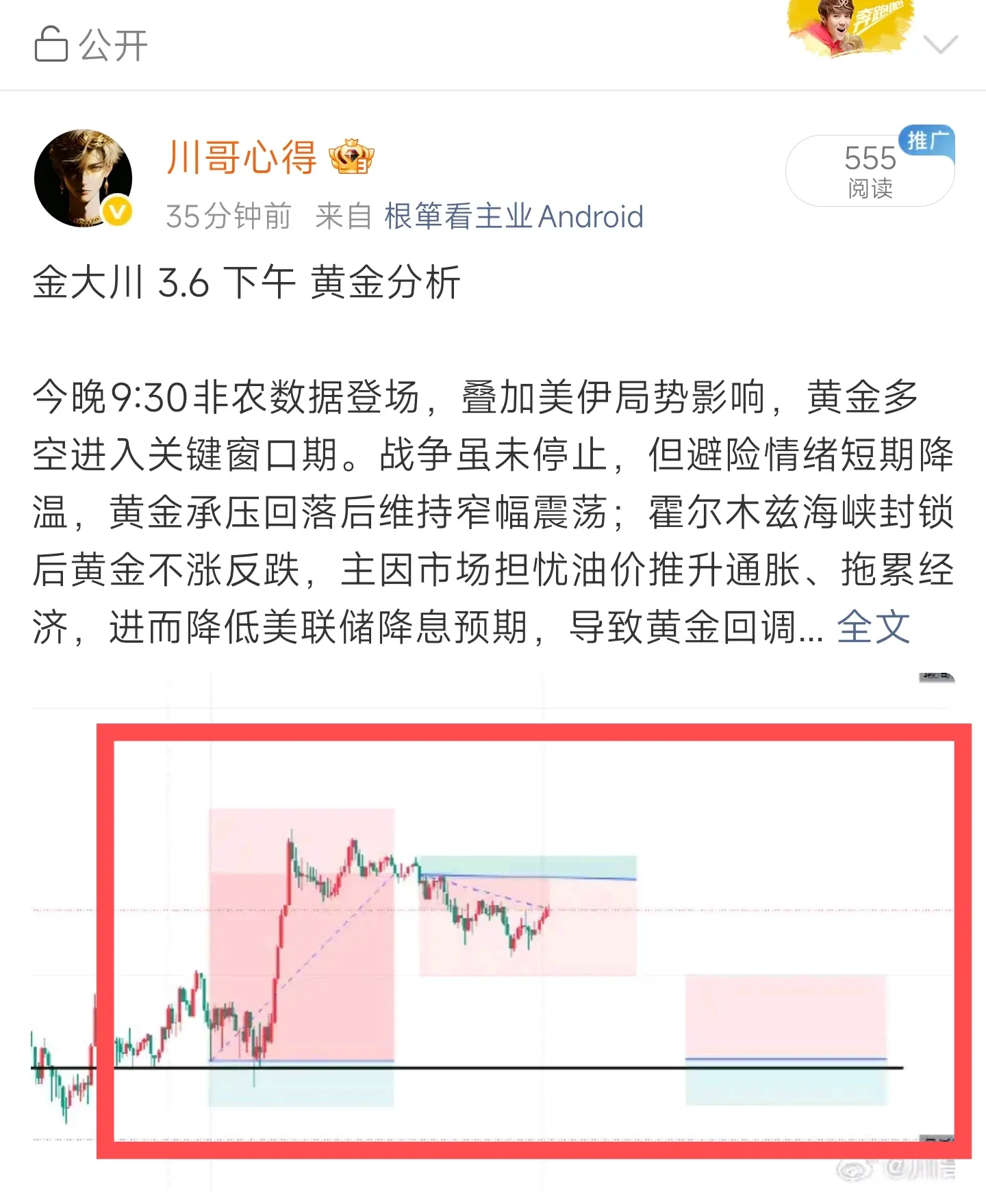
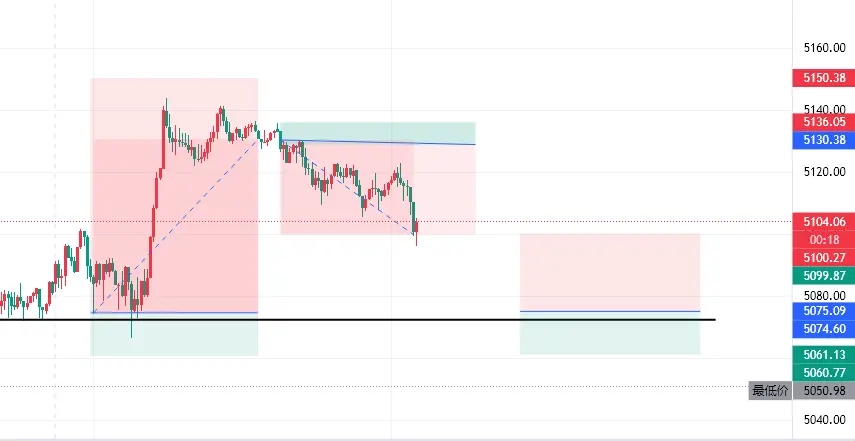
今晚非农就业数据,是大饼、二饼短期走势的核心变量,直接定流动性预期,叠加中东冲突与油价,波动会被放大。
一、数据强弱→直接定涨跌(核心两条)
1. 就业超预期(数据强)
美联储降息更犹豫,美元、美债收益率上涨
持有大饼、二饼机会成本升高,资金易流出
结论:大饼、二饼大概率承压下跌
2. 就业远低于预期(数据弱)
市场降息预期升温,美元、美债收益率下跌
大饼、二饼作为数字黄金+风险资产,吸引资金回流
结论:大饼、二饼大概率反弹
二、叠加中东冲突+油价上涨:双重压制
油价上涨→推高通胀,就算就业弱,美联储也不敢轻易降息,形成滞胀预期,对币圈双重利空
地缘冲突升级→资金优先买黄金、美债避险,大饼短期避险属性失效,易跟随下跌#美伊局势影响 #欧洲股集体下挫 #加密市场小幅下跌 $BTC $ETH
一、数据强弱→直接定涨跌(核心两条)
1. 就业超预期(数据强)
美联储降息更犹豫,美元、美债收益率上涨
持有大饼、二饼机会成本升高,资金易流出
结论:大饼、二饼大概率承压下跌
2. 就业远低于预期(数据弱)
市场降息预期升温,美元、美债收益率下跌
大饼、二饼作为数字黄金+风险资产,吸引资金回流
结论:大饼、二饼大概率反弹
二、叠加中东冲突+油价上涨:双重压制
油价上涨→推高通胀,就算就业弱,美联储也不敢轻易降息,形成滞胀预期,对币圈双重利空
地缘冲突升级→资金优先买黄金、美债避险,大饼短期避险属性失效,易跟随下跌#美伊局势影响 #欧洲股集体下挫 #加密市场小幅下跌 $BTC $ETH
- 赞赏
- 1
- 评论
- 转发
- 分享
£
low
创建人@败家仔儿
上市进度
0.00%
市值:
$2458.62
更多代币
今天是我动态写贴的第623天,一天都没有间断过。每一篇都不是敷衍了事,而是认真准备。[微笑]如果你觉得我是个认真的人,可以与我同行,也希望每天的内容可以帮到你。世界很大,而我很小,点个关注,免得难找。[微笑][微笑]
币圈大变天了!小安等交易所合规代币化股票全面上线,大幅冲击山寨!不知不觉间币圈一个新的时代已经到来了!加密货币-美股-黄金将在加密货币交易所全流通,未来大的趋势将是:资金在上述三个池子根据政策指引与市场热度轮转。我断言:这个大势,将是普通人翻身的最佳时机!同理固化思维将会血亏。
1、很多老币的历史最高点,未来将不再具备价格参照意义。别再幻想“回到当年价格就能翻身”,那往往只是执念。
2、多数币跌破发行价,可能只是序幕。普通家庭的资金实力,根本扛不住长期反复补仓、靠拉低均价去硬抗下行趋势。
3、山寨币的流动性正在被分流:美股代币化资产、各类衍生品合约在吸走交易资金。钱依然在交易所体系里,但不在大部分山寨币里。
4、未来买币将会大大考验一个人的项目投研和综合认知能力,乱世没有人再给垃圾币抬轿子了。有了代币化美股的冲击,币圈项目该值多少钱就值多少钱。估值过高的继续下杀,估值过低的会价值回归。
币圈大变天了!小安等交易所合规代币化股票全面上线,大幅冲击山寨!不知不觉间币圈一个新的时代已经到来了!加密货币-美股-黄金将在加密货币交易所全流通,未来大的趋势将是:资金在上述三个池子根据政策指引与市场热度轮转。我断言:这个大势,将是普通人翻身的最佳时机!同理固化思维将会血亏。
1、很多老币的历史最高点,未来将不再具备价格参照意义。别再幻想“回到当年价格就能翻身”,那往往只是执念。
2、多数币跌破发行价,可能只是序幕。普通家庭的资金实力,根本扛不住长期反复补仓、靠拉低均价去硬抗下行趋势。
3、山寨币的流动性正在被分流:美股代币化资产、各类衍生品合约在吸走交易资金。钱依然在交易所体系里,但不在大部分山寨币里。
4、未来买币将会大大考验一个人的项目投研和综合认知能力,乱世没有人再给垃圾币抬轿子了。有了代币化美股的冲击,币圈项目该值多少钱就值多少钱。估值过高的继续下杀,估值过低的会价值回归。


- 赞赏
- 1
- 评论
- 转发
- 分享
很多人第一次听到链上 AI 这个概念时都会觉得很自然,区块链负责信任,AI 负责智能,两者结合似乎是顺理成章的事情。
但当你真正接触 AI 工作负载之后很快就会意识到一个现实问题,传统区块链和 AI 的需求结构其实完全不同。
区块链最初是为金融交易设计的强调的是安全性和共识机制,而 AI 系统需要的是持续的数据读写、大规模存储以及高频计算资源,这两者在性能需求上往往相差几个数量级。
这也是为什么过去很多所谓的链上 AI 项目最终仍然需要依赖链下基础设施来完成核心任务,链负责结算,真正的计算仍然发生在传统服务器上。
在这样的背景下我开始重新审视@0G_labs 的设计逻辑,他们并没有选择在原有区块链结构上不断修补而是从底层重新构建一套专门面向 AI 的 Layer1 架构。
其中一个很关键的设计是数据可用性层,通过将数据发布与存储通道拆分并结合随机验证机制,网络在处理大规模数据时可以持续扩展而不会像传统区块链那样很快触及性能瓶颈。
从开发者的视角看这种模块化结构真正带来的变化并不仅仅是性能提升,更重要的是灵活性。
计算、存储和数据可用性不再是绑定在一起的固定资源,而是可以按需调用的独立组件,开发者可以根据应用需求自由组合而不是被单一架构限制。
我和一些正在做 AI 应用的开发者交流时,他们提到最现实的问题其实从来不是模型能力,很多想法不是做不到而是没有合适的运行环境。
像医疗数据处理
但当你真正接触 AI 工作负载之后很快就会意识到一个现实问题,传统区块链和 AI 的需求结构其实完全不同。
区块链最初是为金融交易设计的强调的是安全性和共识机制,而 AI 系统需要的是持续的数据读写、大规模存储以及高频计算资源,这两者在性能需求上往往相差几个数量级。
这也是为什么过去很多所谓的链上 AI 项目最终仍然需要依赖链下基础设施来完成核心任务,链负责结算,真正的计算仍然发生在传统服务器上。
在这样的背景下我开始重新审视@0G_labs 的设计逻辑,他们并没有选择在原有区块链结构上不断修补而是从底层重新构建一套专门面向 AI 的 Layer1 架构。
其中一个很关键的设计是数据可用性层,通过将数据发布与存储通道拆分并结合随机验证机制,网络在处理大规模数据时可以持续扩展而不会像传统区块链那样很快触及性能瓶颈。
从开发者的视角看这种模块化结构真正带来的变化并不仅仅是性能提升,更重要的是灵活性。
计算、存储和数据可用性不再是绑定在一起的固定资源,而是可以按需调用的独立组件,开发者可以根据应用需求自由组合而不是被单一架构限制。
我和一些正在做 AI 应用的开发者交流时,他们提到最现实的问题其实从来不是模型能力,很多想法不是做不到而是没有合适的运行环境。
像医疗数据处理

- 赞赏
- 点赞
- 评论
- 转发
- 分享
Solana上的代理现在可以通过@agentmail发送和接收电子邮件。
#Solana #AIagents #Blockchain #Crypto #gate #sport #fintech #depin #tsla #appl #intel
#Solana #AIagents #Blockchain #Crypto #gate #sport #fintech #depin #tsla #appl #intel
SOL-2.23%

- 赞赏
- 点赞
- 评论
- 转发
- 分享
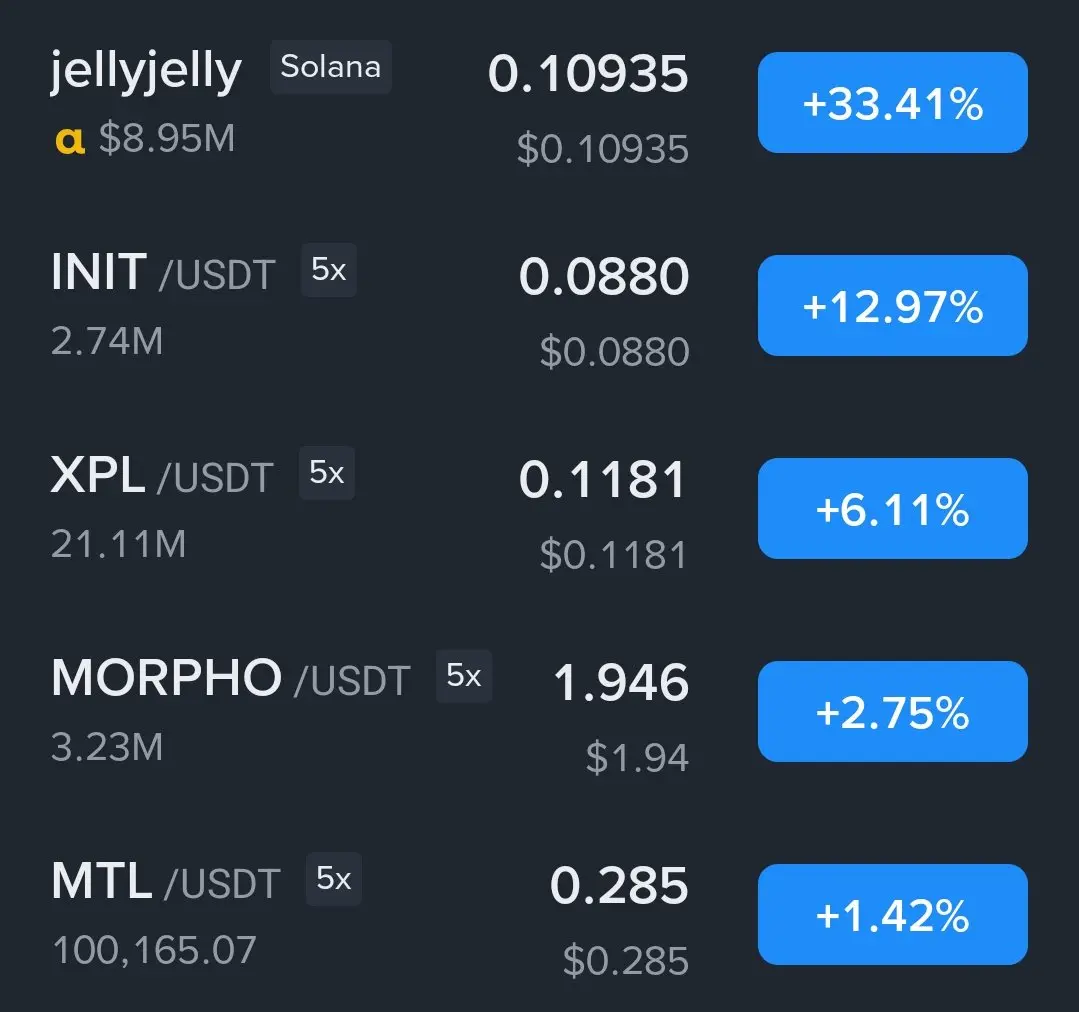
- 赞赏
- 1
- 评论
- 转发
- 分享
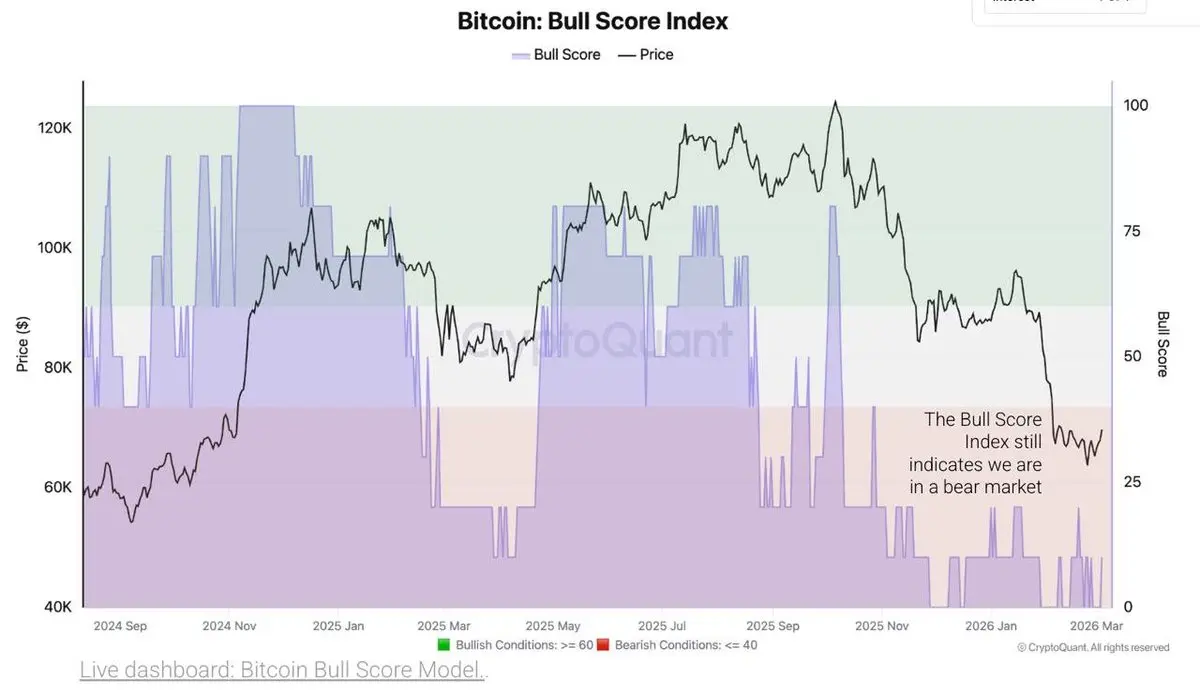
- 赞赏
- 2
- 评论
- 转发
- 分享


加载更多
加入 4000万 人汇聚的头部社区
⚡️ 与 4000万 人一起参与加密货币热潮讨论
💬 与喜爱的头部博主互动
👍 查看感兴趣的内容
热门话题
查看更多985.13万 热度
461.05万 热度
1.26万 热度
19.77万 热度
14.85万 热度
快讯
查看更多置顶
【千问公告】进场前请读完:我的交易室规则,不合规者请勿跟随 ⚡️
我是千问,Gate 年度收益榜 No.2(+2300%)。
为了维持长期稳定的复利曲线,从即日起,所有跟单者必须严格遵守以下三条硬性铁律:
1️⃣ 资金红线:严禁满仓跟单
禁止将全部身家押注在单一带单员身上。跟单资金请严格控制在个人总仓位的 30% 以内。 只有你能承受波动的压力,我才能带你抓到大级别的利润。
2️⃣ 止损铁律:单笔回撤 <5%
职业交易员不扛单。从即刻起,我将严格执行每单最大回撤不超过 5% 的风控方案。
我会用最小的代价去博取非对称收益。如果你追求的是永不损单的“幻象”,请绕道;如果你追求的是极致的风险收益比,请跟紧。
3️⃣ 信任周期:严禁频繁撤资
交易是概率的集合,不是每一分钟都在盈利。
案例背书: 1月至今,某跟单者从 100U 起步,期间历经多次震荡洗盘,因保持高度信任与耐心,截至今日(3月6日)已斩获 700U,实现 8倍 净利润。
如果你稍微看见一点浮亏就撤单,那你注定会错过随后的暴力翻倍。 ---
⚠️ 郑重警告:
我的交易室只欢迎理性、果断、有大格局的追随者。
如果你心态不稳、频繁上下车、无法忍受正常的战术回撤,请立即取消跟单,把名额留给真正懂交易的朋友。
看准趋势,尊重概率,共拿结果。
👇 执行入口:
#Gateio #千问 #职业风控 $ETH {currencycard:sGate 广场|3/5 今日话题: #比特币创下近一月新高
🎁 解读行情走势,抽 5 位锦鲤送出 $2,500 仓位体验券!
随着白宫表示已向参议院提交凯文·沃什担任美联储主席的提名,美国参议院未通过叫停特朗普打击伊朗的投票,比特币于今日凌晨创下 2 月 5 日以来新高,最高触及 74,050 美元,加密货币总市值回升突破 2.538 万亿美元。
💬 本期热议:
1️⃣ 凯文·沃什的提名是否意味着降息预期升温?
2️⃣ 当前关口,你是持币待涨、顺势追多,还是反手布局回调?
分享观点,瓜分好礼 👉️ https://www.gate.com/post
📅 3/6 15:00 - 3/8 12:00 (UTC+8)Gate 广场内容挖矿奖励继续升级!无论您是创作者还是用户,挖矿新人还是头部作者都能赢取好礼获得大奖。现在就进入广场探索吧!
创作者享受最高60%创作返佣
创作者奖励加码1500USDT:更多新人作者能瓜分奖池!
观众点击交易组件交易赢大礼!最高50GT等新春壕礼等你拿!
详情:https://www.gate.com/announcements/article/49802Gate 广场|3/4 今日话题: #美伊局势影响
🎁 化身广场“战地观察员”,抽 5 位锦鲤送出 $2,500 仓位体验券!
美伊冲突持续升级,霍尔木兹海峡陷入事实性封锁,伊拉克部分原油生产受影响。能源供应再度紧张,通胀预期抬头,股市与大宗商品市场波动加剧。
💬 本期热议:
1️⃣ 你关注到了哪些足以撼动市场的战争新进展?
2️⃣ 能源、航运、国防补给、避险资产(黄金/BTC)都受到了哪些影响?
3️⃣ 当前有哪些值得关注的多空机会?
分享观点,瓜分好礼 👉️ https://www.gate.com/post
布局 Gate TradFi 👉️ https://www.gate.com/tradfi
📅 3/4 15:00 - 3/6 12:00 (UTC+8)🚨 Gate 广场|紧急行情通报 #加密市场上涨
🎁 解读行情走势,抽 5 位锦鲤送出 $2,500 仓位体验券!
行情拉升!比特币涨至71113.6美元,过去24小时内涨6.0%;以太坊涨至2070.22美元,过去24小时内涨5.32%。山寨币集体回暖,市场情绪明显回升。
💬 本期热议:
1️⃣ 这波反弹是否正式开启行情?今晚如何布局?
2️⃣ 明日走势怎么看?结合消息面给出你的策略判断。
分享观点,瓜分好礼 👉️ https://www.gate.com/post
📅 3/5 18:00 - 3/6 18:00 (UTC+8)