المؤلف: فو يوي، جيكي ويب 3
في اليوم التالي لتطور تقنية البلوكتشين بشكل أسرع وأسرع، أصبح تحسين الأداء موضوعًا رئيسيًا، وقد أصبحت خريطة طريق بروتوكول إيثريوم واضحة للغاية بتركيزها على Rollup، بينما تعتبر خاصية معالجة المعاملات بتسلسل في EVM قيدًا لا يمكن تجاوزه، ولا يمكن أن تلبي السيناريوهات المستقبلية للحوسبة عالية التداخل.
في المقال السابق - “رؤية طريق تحسين EVM المتوازي من خلال Reddio”، قدمنا نظرة موجزة على تصميم EVM المتوازي لـ Reddio. وفي هذا المقال، سنقوم بتوضيح الحل الفني له وسيناريوهات تكامله مع الذكاء الاصطناعي بشكل أعمق.
نظرًا لأن Reddio تعتمد حلاً تقنيًا يستخدم CuEVM، وهو مشروع يستخدم وحدة معالجة الرسومات لتحسين كفاءة تنفيذ EVM، سنبدأ أولاً من CuEVM.
نظرة عامة على CUDA
CuEVM هو مشروع لتسريع EVM باستخدام GPU ، حيث يحول أوامر ETH EVM إلى CUDA Kernels لتنفيذها بشكل موازٍ على GPU NVIDIA. يتم زيادة كفاءة تنفيذ تعليمات EVM باستخدام قوة الحوسبة الموازية للـ GPU. قد يسمع مستخدمو نظام N- كارت كثيرًا عن كلمة CUDA -
يعد Compute Unified Device Architecture في الواقع نظامًا موازيًا للحوسبة ونموذجًا للبرمجة تم تطويره بواسطة NVIDIA. يتيح للمطورين استخدام قدرة الحوسبة الموازية لوحدة معالجة الرسومات (GPU) للحوسبة العامة (مثل التعدين والعمليات الرياضية ZK) وليس فقط معالجة الرسومات.
كومبيوتينغ باراليل كومبيوتينغ 01928374656574839201 كومبيوتينغ 01928374656574839201 كومبيوتينغ 01928374656574839201 كومبيوتينغ 01928374656574839201 كومبيوتينغ 01928374656574839201 كومبيوتينغ 01928374656574839201 كومبيوتينغ 01928374656574839201 كومبيوتينغ 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201 01928374656574839201

ولكن على عكس الوظائف العادية في C++ التي لا تُنفذ إلا مرة واحدة، يتم تنفيذ هذه الوظائف النواة هذه N مرة بواسطة N خيوط CUDA مختلفة بشكل متوازٍ عند استدعاء بنية التشغيل <<<… >>>.
تم تخصيص هوية موضوع منفصلة لكل خطوط CUDA، وتم تقسيمها إلى هيكلية المستوى الخطوط، بحيث يتم تخصيص الخطوط إلى كتل (blocks) و شبكات (grids) لإدارة كمية كبيرة من الخطوط المتوازية. يمكننا ترجمة كود CUDA إلى برنامج يمكن تشغيله على وحدة معالجة الرسوميات (GPU) باستخدام مترجم NVIDIA nvcc.

عملية سير العمل الأساسية لـ CuEVM
بعد فهم سلسلة من المفاهيم الأساسية لـ CUDA ، يمكنك الآن الاطلاع على سير عمل CuEVM.
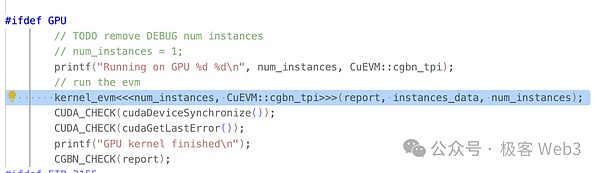
المدخل الرئيسي لـ CuEVM هو run_interpreter ، حيث يتم إدخال المعاملات التي يتم معالجتها بشكل متزامن على شكل ملف JSON. يمكن ملاحظة من حالات الاستخدام في المشروع أن المدخلات هي محتوى EVM القياسي ، ولا يلزم للمطور أي معالجة أو ترجمة إضافية.

يمكن ملاحظة في run_interpreter()، أنه يستخدم بناء الجملة <<…>> المحدد من قبل CUDA لاستدعاء وظيفة kernel_evm() النواة. كما ذكرنا في النص السابق، يتم استدعاء النواة بشكل متوازي في وحدة المعالجة الرسومية.
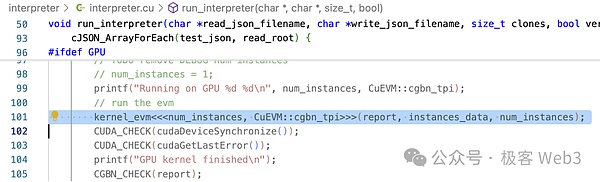
في الطريقة kernel_evm() سيتم استدعاء evm->run()، يمكننا أن نرى أن هناك الكثير من الفروع الشرطية لتحويل رموز تشغيل EVM إلى عمليات CUDA.
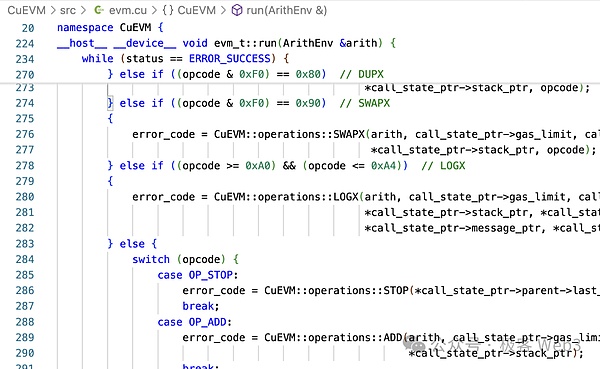
على سبيل المثال، يمكننا أن نرى أنه تم تحويل ADD إلى cgbn_add باستخدام كود العملية OP_ADD في EVM. وCGBN (Cooperative Groups Big Numbers) هو مكتبة عمليات الأعداد الصحيحة متعددة الدقة عالية الأداء لـ CUDA.

تحولت هاتين الخطوتين من رمز التشغيل EVM إلى عملية CUDA. يمكن القول أن CuEVM هو أيضًا تنفيذ لجميع عمليات EVM على CUDA. في النهاية ، تعيد طريقة run_interpreter() النتيجة الحسابية ، وهي حالة العالم وغيرها من المعلومات.
تم شرح منطق تشغيل CuEVM الأساسي حتى الآن.
**يتمتع CuEVM بقدرة معالجة المعاملات المتزامنة ، ولكن الهدف الرئيسي لمشروع CuEVM (أو الحالة التي تم عرضها بشكل رئيسي) هو إجراء اختبارات Fuzzing: ** يعد Fuzzing تقنية اختبار البرمجيات التلقائية ، حيث يتم إدخال كمية كبيرة من البيانات غير الصالحة أو غير المتوقعة أو عشوائية إلى البرنامج لمراقبة استجابة البرنامج وبالتالي تحديد الأخطاء المحتملة ومشكلات الأمان.
يمكننا أن نرى أن Fuzzing مناسب لمعالجة متوازية للغاية. بينما لا تتعامل CuEVM مع مشاكل تعارض المعاملات وما إلى ذلك، فهذا ليس ما يهمها. إذا كنت ترغب في دمج CuEVM، فإنه من الضروري معالجة المعاملات المتعارضة.
لقد قمنا بتقديم آلية معالجة التضارب المستخدمة في Reddio في مقالنا السابق “الطريق إلى تحسين EVM المتوازي من خلال Reddio”، ولا داعي لتكرارها هنا. بمجرد أن يتم ترتيب المعاملات باستخدام آلية معالجة التضارب في Reddio، يمكن إرسالها إلى CuEVM. وبعبارة أخرى، يمكن تقسيم آلية ترتيب المعاملات في Reddio L2 إلى جزئين: معالجة التضارب + تنفيذ متوازي لـ CuEVM.
تقاطع Layer2، EVM المتوازي، والذكاء الاصطناعي
وقد أشار النص السابق إلى أن تواجد EVM و L2 بشكل متوازي هو مجرد بداية لـ Reddio، وستكون خارطة طريقها المستقبلية مرتبطة بشكل واضح بالرواية الذكية. ** بفضل استخدام وحدة معالجة الرسومات لتحقيق التداول المتوازي السريع، فإن Reddio مناسبة بشكل طبيعي لعمليات الذكاء الاصطناعي من حيث الكثير من الميزات: **
- قوة المعالجة المتوازية لـ GPU تجعلها مناسبة لتنفيذ العمق العميق للتعلم التعليمي في العمليات التفاضلية الفصلية ، وهذه العمليات هي في الأساس ضرب المصفوفة على نطاق واسع ، وال GPU مصممة خصيصًا لتحسين هذا النوع من المهام.
- يمكن لهيكل التصنيف الخطي لـ GPU أن يتوافق مع بنية البيانات المختلفة في حسابات AI ، ويمكن زيادة كفاءة الحساب من خلال تجاوز الخط الزمني للموضوع ووحدات تنفيذ الوحدة وإخفاء الذاكرة.
- قوة الحساب هي المؤشر الرئيسي لقياس أداء الحساب الذكي ، حيث يقوم GPU بتحسين قوة الحساب ، مثل إدخال Tensor Core ، لتحسين أداء ضرب المصفوفات في الحساب الذكي وتحقيق توازن فعال بين الحساب ونقل البيانات.
إذا كيف يتم تواصل AI و L2 في النهاية؟
نحن نعلم أنه في تصميم البنية التحتية للـ Rollup ، ليس هناك مجرد منظمين في الشبكة بل هناك أيضًا بعض الأدوار مثل المشرفين والمرسلين للتحقق من الصفقات أو جمعها ، حيث يستخدمون بشكل أساسي نفس عميل المنظمين ولكنهم يقومون بوظائف مختلفة. في الـ Rollup التقليدي ، تكون وظائف وصلاحيات هذه الأدوار الثانوية محدودة جدًا ، مثل دور المشاهد في Arbitrum ، حيث يكون بشكل أساسي دفاعيًا ويعمل للمصلحة العامة ، ويمكن أن يثير شكوكًا في نمط الربح.
ستعتمد Reddio على ترتيب غير مركزي للمعالجة وستوفر GPU كعقدة للمعدن. يمكن لشبكة Reddio بأكملها التطور من L2 بسيط إلى شبكة شاملة L2+AI، مما يسمح بتحقيق بعض حالات استخدام AI+كتلة سلسلة.
شبكة AI Agent التفاعلية الأساسية
مع تطور تقنية البلوكتشين، فإن لدى وكيل الذكاء الاصطناعي إمكانيات هائلة في شبكة البلوكتشين. دعونا نأخذ وكيل الذكاء الاصطناعي الذي يقوم بتنفيذ المعاملات المالية كمثال، يمكن لهؤلاء الوكلاء الذكيين أن يتخذوا قرارات معقدة وينفذوا عمليات تداول بشكل مستقل، وحتى يمكنهم الاستجابة بسرعة في ظروف التداول عالي التردد. ومع ذلك، من الصعب تقريبًا على L1 تحمل أحمال معاملات ضخمة عند معالجة عمليات مكدسة من هذا النوع.

وبوصفه مشروع L2 ، يمكن لـ Reddio زيادة قدرته على معالجة المعاملات المتوازية بشكل كبير من خلال تسريع وحدة معالجة الرسومات (GPU). بالمقارنة مع L1 ، يتمتع L2 بطاقة إخراج أعلى ويمكنه معالجة طلبات المعاملات العالية التردد لعدد كبير من وكلاء AI بكفاءة ، مما يضمن سير شبكة سلس.
في التداول عالي التردد، تكون متطلبات وكلاء الذكاء الصناعي بشأن سرعة التداول ووقت الإستجابة صارمة للغاية. يقلل L2 من وقت التحقق والتنفيذ للصفقات، مما يقلل بشكل كبير من وقت الإستجابة. هذا أمر حيوي بالنسبة لوكلاء الذكاء الصناعي الذين يحتاجون إلى استجابة في ميلي ثانية. من خلال نقل حجم كبير من الصفقات إلى L2، تخفف أيضًا من مشكلة الازدحام في الشبكة الرئيسية. مما يجعل عمل وكلاء الذكاء الصناعي أكثر كفاءة اقتصادية.
随着Reddio等L2项目的成熟,AI Agent将在كتلةداخل السلسلة发挥更重要的作用,推动التمويل اللامركزي 和其他كتلة链应用场景与AI结合的创新。
اللامركزيةقوة الحوسبة市场
ستعتمد Reddio في المستقبل على ترتيب الجهاز اللامركزي، حيث يتم تحديد حقوق الترتيب بواسطة قوة الحوسبة GPU، وستزيد أداء GPU لمشاركي الشبكة بشكل تدريجي مع التنافس، حتى يمكن أن يصل إلى مستوى يمكن استخدامه في تدريب الذكاء الاصطناعي.
بناء سوق الحوسبة غير المركزية لقوة الحوسبة GPU، لتوفير موارد الحوسبة بتكلفة أقل لتدريب واستدلال الذكاء الاصطناعي. يمكن لمختلف مستويات قوة الحوسبة GPU، من الحواسيب الشخصية إلى مجاميع الغرف، الانضمام إلى هذا السوق والمساهمة بقوتها الحوسبة الشاغرة وكسب الأرباح، هذا النمط يمكن أن يسقط تكلفة حوسبة الذكاء الاصطناعي، ويجعل المزيد من الأشخاص يشاركون في تطوير وتطبيق نماذج الذكاء الاصطناعي.
في حالة استخدام اللامركزية في حالات الاستخدام لقوة الحوسبة ، قد لا يكون المرتب الأولي مسؤولًا بشكل رئيسي عن عمليات الذكاء الاصطناعي المباشرة ، بل يكون وظيفته الرئيسية هي معالجة المعاملات وتنسيق قوة الحوسبة للذكاء الاصطناعي في الشبكة بأكملها. ** وفيما يتعلق بقوة الحوسبة وتوزيع المهام ، هناك نوعان من النماذج: **
- التوزيع المركزي الهرمي. بفضل وجود جهاز فرز، يمكن لجهاز الفرز توزيع طلبات قوة الحوسبة التي يتلقاها على العقدة التي تلبي المتطلبات ولديها سمعة جيدة. على الرغم من وجود مشكلات مركزية وغير عادلة نظريًا في هذه الطريقة، إلا أن المزايا الكبيرة التي توفرها في الكفاءة تفوق بكثير على العيوب، وعلى المدى البعيد، يجب على جهاز الفرز أن يلبي صفة الإيجابية لشبكة بأكملها للتطور على المدى البعيد، وبالتالي هناك قيود ضمنية ولكنها مباشرة تضمن عدم وجود انحيازات كبيرة جدًا في جهاز الفرز.
- اختيار المهمة الذاتي الاندفاع من الأسفل إلى الأعلى. يمكن أيضًا للمستخدمين تقديم طلبات حسابية للذكاء الاصطناعي إلى العقد الخارجية ، وهذا بالطبع أكثر كفاءة من تقديمها مباشرة إلى المرتبة ، ويمكن أيضًا منع المراجعة والتحيز من المرتبة. بعد الانتهاء من العملية ، يتم مزامنة نتائج العملية هذه من العقدة إلى المرتبة وتسجيلها على السلسلة الرئيسية.
نلاحظ أن سوق قوة الحوسبة لديه مرونة كبيرة في هيكل L2 + AI ، ويمكن تجميع قوة الحوسبة من اتجاهين لزيادة أقصى قدر من استخدام الموارد.
داخل السلسلةAI推理
الآن ، وصل نضوج نموذج مفتوح المصدر إلى مستوى يكفي لتلبية متطلبات متنوعة. مع توحيد خدمات الاستدلال الذكي ، ** يصبح من الممكن استكشاف كيفية ربط قوة الحوسبة بالسلسلة لتحقيق التسعير التلقائي. ** ومع ذلك ، فإن هذا يتطلب التغلب على تحديات تقنية متعددة:
- توزيع الطلبات والتسجيل الفعال: تتطلب النماذج الكبيرة للتحليل الاستنتاجي وقت الإستجابة العالي ، لذا فإن آلية توزيع الطلبات الفعالة ذات أهمية كبيرة. على الرغم من أن حجم البيانات المطلوبة والرد عليها كبير ويحتوي على معلومات سرية للغاية ولا يمكن تقديمها بشكل علني في كتلة السلسلة ، إلا أنه يجب العثور على توازن بين التسجيل والتحقق - على سبيل المثال ، من خلال تخزين هاش.
- قوة الحوسبةعقدة输出的验证: عقدة是否真正地完成了所制定的运算任务?如,عقدة虚报用小模型运算结果代替大模型。
- الاستدلال بالعقود الذكية: في العديد من السيناريوهات، من الضروري دمج نموذج الذكاء الاصطناعي مع العقد الذكي للقيام بالعمليات. نظرًا لأن الاستدلال بالذكاء الاصطناعي يتسم بعدم اليقين، فمن غير الممكن استخدامه في جميع جوانب السلسلة، لذا فإن منطق تطبيقات الذكاء الاصطناعي القادمة قد يكون جزئيًا داخل السلسلة وجزئيًا في العقد الذكي الخارجي، حيث يتم تحديد صحة وصلاحية البيانات المقدمة من الخارج للعقد الذكي داخل السلسلة. وفي بيئة إثيريوم، يتعين على دمج العقد الذكي مع التنفيذ العاجل والمتوالي غير الفعال للآلة الافتراضية لإثيريوم.
ولكن في هيكل Reddio، يمكن حل هذه المشاكل بسهولة نسبية:
- يتم توزيع المرتبة بشكل أكثر كفاءة بكثير من L1 على الطلبات ، ويمكن اعتبارها مكافئة لكفاءة Web2. يمكن حل موضع وطريقة الحفظ للبيانات بواسطة مجموعة متنوعة من حلول DA ذات تكلفة منخفضة.
- يمكن تحقق نتائج عمليات الذكاء الاصطناعي في النهاية بواسطة ZKP للتحقق من صحتها ونواياها الحسنة. وميزة ZKP هي أن التحقق سريع جدًا ، ولكن إنشاء البرهان بطيء نسبيًا. ويمكن استخدام تسريع GPU أو TEE لإنشاء ZKP.
- Solidty → CUDA → سلاح موجه الحاسوب الرسومي هذا هو الخط الرئيسي الموازي لـ EVM وهو أساس Reddio. لذلك من الناحية الظاهرية، هذه هي أبسط مشكلة بالنسبة لـ Reddio. حالياً، Reddio يعمل بالتعاون مع eliza من AiI6z لإدخال وحداتها إلى Reddio، وهذا اتجاه يستحق الاستكشاف بشكل كبير.
ملخص
بشكل عام ، يبدو أن حلول Layer2 و EVM الموازية وتكنولوجيا الذكاء الاصطناعي في هذه المجالات بدون ارتباط ، ومع ذلك ، يجمع Reddio بشكل ذكي بين هذه المجالات الرئيسية من خلال الاستفادة الكاملة من خصائص الحساب الرسومي للوحدة المركزية.
من خلال استغلال قدرات الحساب المتوازي للوحدات المعالجة الرسومية (GPU)، يعزز Reddio سرعة وكفاءة التداول على Layer2، مما يعزز أداء إثيريوم في الطبقة الثانية. إدماج تكنولوجيا الذكاء الاصطناعي في التكنولوجيا السلسلة هو محاولة جديدة وواعدة. إدخال التكنولوجيا الذكاء الاصطناعي يمكن أن يوفر تحليلاً ودعمًا قراريًا ذكيًا للعمليات داخل السلسلة، مما يتيح تطبيقات سلسلة كتل أكثر ذكاءً وديناميكية. هذا التكامل العابر للتخصصات بلا شك يفتح طرقًا وفرصًا جديدة لتطوير الصناعة بأكملها.
ومع ذلك ، يجب ملاحظة أن هذا المجال ما زال في مرحلة مبكرة ويتطلب الكثير من البحث والاستكشاف. ستكون التحسينات والتحسينات المستمرة في التكنولوجيا ، بالإضافة إلى الخيال والعمل للرواد في السوق ، هي القوة الدافعة الرئيسية لدفع هذا الابتكار نحو النضج. لقد قام Reddio بخطوة هامة وجريئة عند هذا التقاء ، ونتطلع إلى رؤية المزيد من الاندفاع والمفاجآت في هذا المجال المتكامل في المستقبل.