Fuente original: New Zhiyuan
 Fuente de la imagen: Generado por Unbounded AI
Fuente de la imagen: Generado por Unbounded AI
Hace algún tiempo, Google DeepMind propuso un nuevo método de “Step-Backing”, que directamente hizo que la tecnología abriera el cerebro.
En pocas palabras, es dejar que el gran modelo de lenguaje abstraiga el problema por sí mismo, obtenga un concepto o principio de dimensión superior y luego use el conocimiento abstracto como una herramienta para razonar y derivar la respuesta al problema.
 Dirección:
Dirección:
Los resultados también fueron muy buenos, ya que experimentaron con el modelo PaLM-2L y demostraron que esta nueva técnica funcionaba muy bien en el manejo de ciertas tareas y problemas.
Por ejemplo, MMLU tiene una mejora del 7 % en el rendimiento físico y químico, una mejora del 27 % en TimeQA y una mejora del 7 % en MuSiQue.
Entre ellos, MMLU es un conjunto de datos de prueba de comprensión del lenguaje multitarea a gran escala, TimeOA es un conjunto de datos de prueba de preguntas sensibles al tiempo y MusiQue es un conjunto de datos de preguntas y respuestas de múltiples saltos que contiene 25,000 preguntas de 2 a 4 saltos.
Entre ellos, un problema de salto múltiple se refiere a una pregunta que solo se puede responder mediante el uso de una ruta de inferencia de salto múltiple formada por múltiples triples.
A continuación, echemos un vistazo a cómo se implementa esta tecnología.
¡Atrás!
Después de leer la introducción al principio, es posible que los lectores no la entiendan demasiado. ¿Qué significa para los LLM abstraer el problema por sí mismos y obtener un concepto o principio de dimensión superior?
Pongamos un ejemplo concreto.
Por ejemplo, si el usuario quiere hacer una pregunta relacionada con la “fuerza” en física, entonces el LLM puede retroceder al nivel de la definición básica y el principio de fuerza al responder a dicha pregunta, lo que puede usarse como base para un razonamiento adicional sobre la respuesta.
Basándonos en esta idea, cuando el usuario entra por primera vez, es más o menos así:
Ahora eres un experto en el conocimiento del mundo, experto en pensar cuidadosamente y responder preguntas paso a paso con una estrategia de cuestionamiento hacia atrás.
Dar un paso atrás es una estrategia de pensamiento para comprender y analizar un problema o situación particular desde una perspectiva más macro y fundamental. Respondiendo así mejor a la pregunta original.
Por supuesto, el ejemplo de física dado anteriormente ilustra solo un caso. En algunos casos, la estrategia de retroceso puede permitir que el LLM intente identificar el alcance y el contexto del problema. Algunos problemas retroceden un poco más y otros caen menos.
Tesis
En primer lugar, los investigadores señalan que el campo del procesamiento del lenguaje natural (PLN) ha marcado el comienzo de una revolución revolucionaria con los LLM basados en Transformer.
La expansión del tamaño del modelo y el aumento del corpus preentrenado han traído mejoras significativas en las capacidades del modelo y la eficiencia del muestreo, así como capacidades emergentes como la inferencia de varios pasos y el seguimiento de instrucciones.
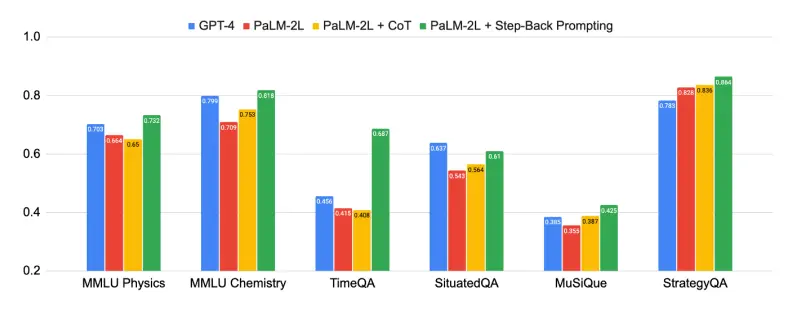 La figura anterior muestra el poder del razonamiento hacia atrás, y el método de “razonamiento abstracto” propuesto en este artículo ha logrado mejoras significativas en una variedad de tareas difíciles que requieren un razonamiento complejo, como la ciencia, la tecnología, la ingeniería y las matemáticas, y el razonamiento de múltiples saltos.
La figura anterior muestra el poder del razonamiento hacia atrás, y el método de “razonamiento abstracto” propuesto en este artículo ha logrado mejoras significativas en una variedad de tareas difíciles que requieren un razonamiento complejo, como la ciencia, la tecnología, la ingeniería y las matemáticas, y el razonamiento de múltiples saltos.
Algunas tareas fueron muy desafiantes y, al principio, PaLM-2L y GPT-4 solo tenían un 40% de precisión en TimeQA y MuSiQue. Después de aplicar el razonamiento hacia atrás, el rendimiento de PaLM-2L ha mejorado en todos los ámbitos. Mejoró un 7% y un 11% en física y química MMLU, un 27% en TimeQA y un 7% en MuSiQue.
No solo eso, sino que los investigadores también realizaron un análisis de errores y descubrieron que la mayoría de los errores que ocurren al aplicar el razonamiento hacia atrás se deben a las limitaciones inherentes de la capacidad de inferencia de los LLM y no están relacionados con las nuevas tecnologías.
La abstracción es más fácil de aprender para los LLM, por lo que señala el camino hacia un mayor desarrollo del razonamiento hacia atrás.
Si bien se han logrado avances, el razonamiento complejo de varios pasos puede ser un desafío. Esto es cierto incluso para los LLM más avanzados.
Este artículo muestra que la supervisión de procesos con función de verificación paso a paso es un remedio eficaz para mejorar la corrección de los pasos intermedios del razonamiento.
Introdujeron técnicas como las indicaciones de la cadena de pensamiento para generar una serie coherente de pasos intermedios de inferencia, aumentando la tasa de éxito de seguir la ruta de decodificación correcta.
Al hablar sobre el origen de esta tecnología PROMP, los investigadores señalaron que cuando se enfrentan a tareas desafiantes, los seres humanos tienden a dar un paso atrás y abstraerse, para derivar conceptos y principios de alto nivel para guiar el proceso de razonamiento.
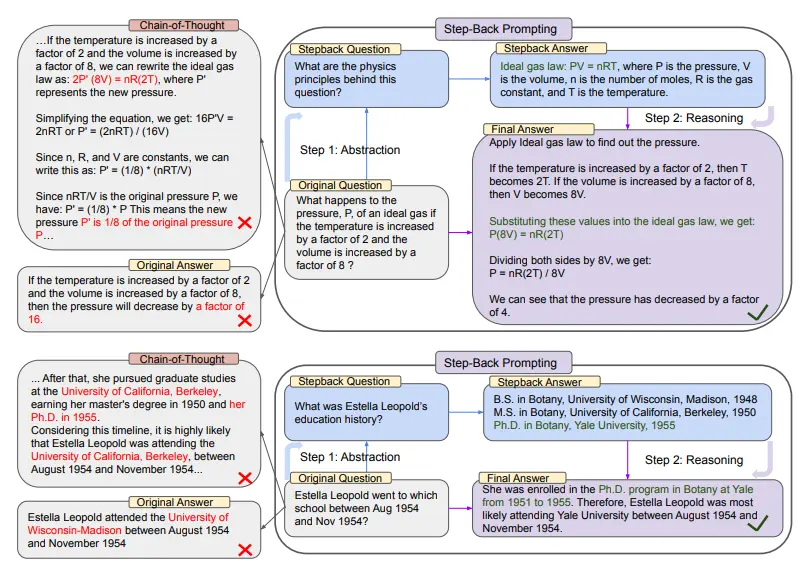 En la parte superior de la figura anterior, tomando como ejemplo la física de la escuela secundaria de MMLU, a través de la abstracción hacia atrás, LLM obtiene el primer principio de la ley de los gases ideales.
En la parte superior de la figura anterior, tomando como ejemplo la física de la escuela secundaria de MMLU, a través de la abstracción hacia atrás, LLM obtiene el primer principio de la ley de los gases ideales.
En la segunda mitad, hay un ejemplo de TimeQA, donde el concepto de alto nivel de la historia de la educación es el resultado de la abstracción de LLM basada en esta estrategia.
Desde el lado izquierdo de todo el diagrama podemos ver que PaLM-2L no tuvo éxito en responder a la pregunta original. La cadena de pensamiento indica que en medio del paso de razonamiento, el LLM cometió un error (resaltado en rojo).
Y a la derecha, el PaLM-2L, con la aplicación de la tecnología hacia atrás, respondió con éxito a la pregunta.
Entre las muchas habilidades cognitivas, el pensamiento abstracto es ubicuo para la capacidad humana de procesar grandes cantidades de información y derivar reglas y principios generales.
Por nombrar algunas, Kepler destiló miles de mediciones en las Tres Leyes del Movimiento Planetario de Kepler, que describen con precisión las órbitas de los planetas alrededor del Sol.
O, en la toma de decisiones críticas, los humanos también encuentran útil la abstracción porque proporciona una visión más amplia del entorno.
El enfoque de este artículo es cómo los LLM pueden manejar tareas complejas que involucran muchos detalles de bajo nivel a través de un enfoque de dos pasos de abstracción y razonamiento.
El primer paso es enseñar a los LLM a dar un paso atrás y derivar conceptos abstractos de alto nivel a partir de ejemplos concretos, como conceptos fundamentales y primeros principios dentro de un dominio.
El segundo paso es utilizar las habilidades de razonamiento para basar la solución en conceptos de alto nivel y primeros principios.
Los investigadores utilizaron un pequeño número de ejemplos de LLM para realizar inferencias hacia atrás. Experimentaron en una serie de tareas que involucraban el razonamiento de dominio específico, la resolución de problemas de conocimiento intensivo, el razonamiento de sentido común de múltiples saltos que requería conocimiento fáctico.
Los resultados muestran que el rendimiento de PaLM-2L mejora significativamente (hasta un 27%), lo que demuestra que la inferencia hacia atrás es muy eficaz para hacer frente a tareas complejas.
Durante los experimentos, los investigadores experimentaron con los siguientes tipos diferentes de tareas:
(1)TALLO
(2) Control de calidad del conocimiento
(3) Razonamiento multisalto
Los investigadores evaluaron la aplicación en tareas STEM para medir la efectividad del nuevo enfoque en el razonamiento en campos altamente especializados. (Este artículo solo cubrirá estas preguntas)
Obviamente, el problema en el punto de referencia de la MMLU requiere un razonamiento más profundo por parte de la LLM. Además, requieren la comprensión y aplicación de fórmulas, que a menudo son principios y conceptos físicos y químicos.
En este caso, el investigador primero enseña el modelo a abstraer en forma de conceptos y primeros principios, como la primera ley del movimiento de Newton, el efecto Doppler y la energía libre de Gibbs. La pregunta implícita aquí es: “¿Cuáles son los principios y conceptos físicos o químicos involucrados en la resolución de esta tarea?”
El equipo proporcionó demostraciones que enseñaron al modelo a memorizar los principios de la resolución de tareas a partir de su propio conocimiento.
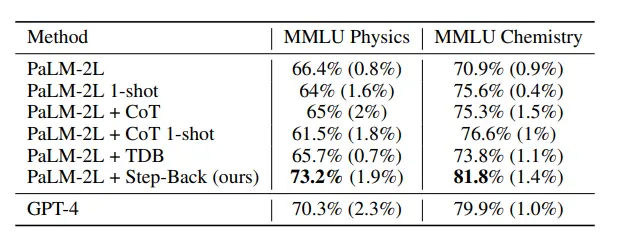 La tabla anterior muestra el rendimiento del modelo utilizando la técnica de inferencia hacia atrás, y el LLM con la nueva tecnología se desempeñó bien en tareas STEM, alcanzando el nivel más avanzado más allá de GPT-4.
La tabla anterior muestra el rendimiento del modelo utilizando la técnica de inferencia hacia atrás, y el LLM con la nueva tecnología se desempeñó bien en tareas STEM, alcanzando el nivel más avanzado más allá de GPT-4.
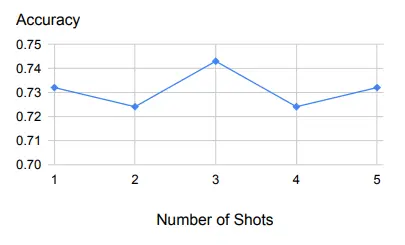 La tabla anterior es un ejemplo de un pequeño número de muestras y demuestra un rendimiento sólido con diferentes tamaños de muestra.
La tabla anterior es un ejemplo de un pequeño número de muestras y demuestra un rendimiento sólido con diferentes tamaños de muestra.
En primer lugar, como podemos ver en el gráfico anterior, la inferencia hacia atrás es muy robusta para un pequeño número de ejemplos utilizados como demostraciones.
Además de un ejemplo, lo mismo ocurrirá con la adición de más ejemplos.
Esto sugiere que la tarea de recuperar principios y conceptos relevantes es relativamente fácil de aprender, y un ejemplo de demostración es suficiente.
Por supuesto, en el transcurso del experimento, todavía habrá algunos problemas.
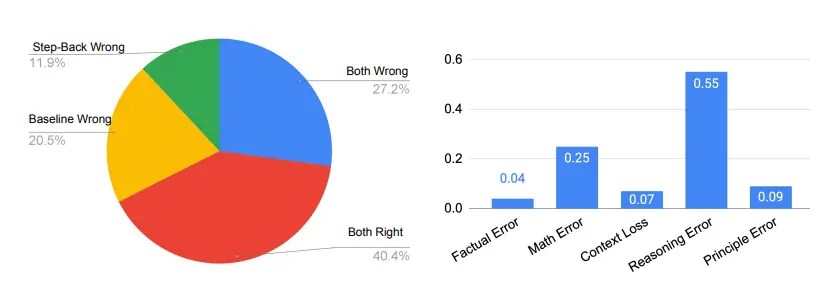
Los cinco tipos de errores que ocurren en todos los trabajos, excepto los errores de principio, ocurren en el paso de razonamiento del LLM, mientras que los errores de principio indican el fracaso del paso de abstracción.
Como puede ver en el lado derecho de la figura siguiente, los errores de principio en realidad representan solo una pequeña fracción de los errores del modelo, con más del 90% de los errores que ocurren en el paso de inferencia. De los cuatro tipos de errores en el proceso de razonamiento, los errores de razonamiento y los errores matemáticos son los principales lugares donde se localizan los errores.
Esto está en línea con los hallazgos en los estudios de ablación de que solo se necesitan unos pocos ejemplos para enseñar a los LLM cómo abstraer. El paso de inferencia sigue siendo un cuello de botella para que la inferencia hacia atrás complete tareas que requieren una inferencia compleja, como MMLU.
Esto es especialmente cierto para MMLU Physics, donde el razonamiento y las habilidades matemáticas son clave para resolver problemas con éxito. Esto significa que incluso si el LLM recupera los primeros principios correctamente, todavía tiene que pasar por un proceso de razonamiento típico de varios pasos para llegar a la respuesta final correcta, lo que requiere que el LLM tenga un razonamiento profundo y habilidades matemáticas.
 Luego, los investigadores evaluaron el modelo en el conjunto de prueba de TimeQA.
Luego, los investigadores evaluaron el modelo en el conjunto de prueba de TimeQA.
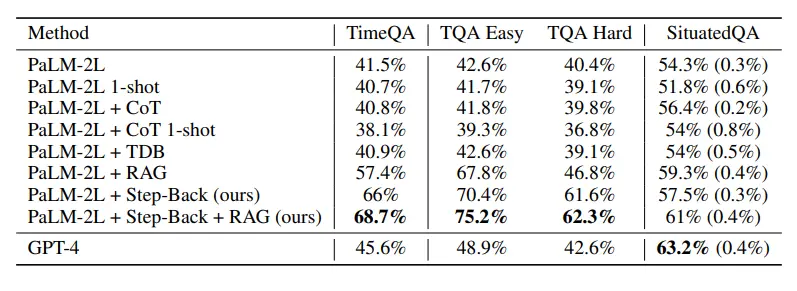
Como se muestra en la siguiente figura, los modelos de referencia de GPT-4 y PaLM-2L alcanzaron el 45,6% y el 41,5%, respectivamente, lo que pone de manifiesto la dificultad de la tarea.
CoT o TDB se aplicó cero veces (y una vez) en el modelo de referencia sin ninguna mejora.
Por el contrario, la precisión del modelo de referencia mejorada por el aumento regular de la recuperación (RAG) aumentó al 57,4%, lo que pone de manifiesto la naturaleza intensiva de la tarea.
Los resultados de Step-Back + RAG muestran que el paso de LLM de vuelta a los conceptos avanzados es muy efectivo en la inferencia hacia atrás, lo que hace que el enlace de recuperación de LLM sea más confiable, y podemos ver que TimeQA tiene una asombrosa precisión del 68.7%.
A continuación, los investigadores dividieron TimeQA en dos niveles de dificultad: fácil y difícil proporcionados en el conjunto de datos original.
No es sorprendente que todos los LLM tengan un desempeño deficiente en el nivel difícil. Mientras que RAG fue capaz de aumentar la precisión del 42,6% al 67,8% en el nivel fácil, la mejora fue mucho menor para el nivel difícil, con datos que muestran sólo un aumento del 40,4% al 46,8%.
Y aquí es donde entra en juego la técnica del razonamiento retrospectivo, ya que recupera hechos sobre conceptos de nivel superior y sienta las bases para el razonamiento final.
El razonamiento hacia atrás más RAG mejoraron aún más la precisión hasta el 62,3%, superando el 42,6% de GPT-4.
 Por supuesto, todavía hay algunos problemas con esta tecnología cuando se trata de TimeQA.
Por supuesto, todavía hay algunos problemas con esta tecnología cuando se trata de TimeQA.
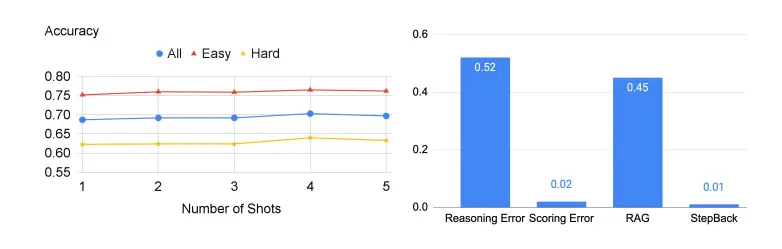
La siguiente figura muestra la precisión del LLM en esta parte del experimento y la probabilidad de que ocurra un error a la derecha.
 Recursos:
Recursos:
