Source originale : Xinzhiyuan
 Source de l’image : générée par Unbounded AI
Source de l’image : générée par Unbounded AI
De nos jours, des modèles de réseaux neuronaux géants tels que GPT-4 et PaLM ont vu le jour et ont démontré d’étonnantes capacités d’apprentissage sur quelques échantillons.
Grâce à des invites simples, ils peuvent raisonner sur un texte, écrire des histoires, répondre à des questions, programmer…
Cependant, LLM perd souvent face aux humains dans des tâches de raisonnement complexes en plusieurs étapes et lutte en vain.
À cet égard, des chercheurs de l’Académie chinoise des sciences et de l’Université de Yale ont proposé un nouveau cadre de « propagation de la pensée » qui peut améliorer le raisonnement du LLM grâce à la « pensée analogique ».
 Adresse papier :
Adresse papier :
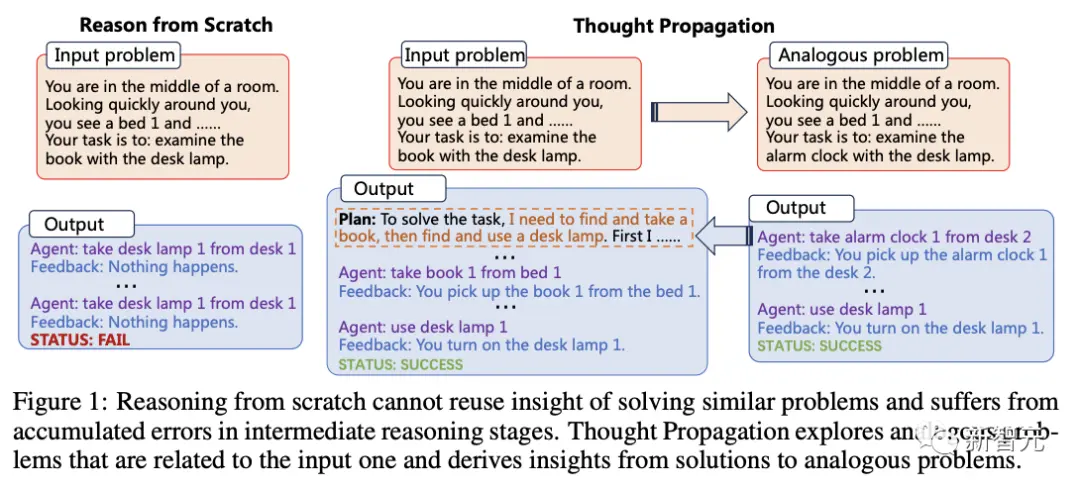
La « propagation de la pensée » s’inspire de la cognition humaine, c’est-à-dire que lorsque nous rencontrons un nouveau problème, nous le comparons souvent à des problèmes similaires que nous avons déjà résolus pour en dériver des stratégies.
Par conséquent, le cœur de cette méthode est de laisser LLM explorer des problèmes « similaires » liés à l’entrée avant de résoudre le problème d’entrée.
Enfin, leurs solutions peuvent être utilisées directement ou extraire des informations pour une planification utile.
Il est prévisible que la « communication pensante » propose de nouvelles idées sur les limitations inhérentes aux capacités logiques du LLM, permettant aux grands modèles d’utiliser « l’analogie » pour résoudre des problèmes comme ceux des humains.

Le raisonnement en plusieurs étapes LLM, vaincu par les humains
Il est évident que le LLM est bon dans le raisonnement de base basé sur des invites, mais il a encore des difficultés lorsqu’il s’agit de traiter des problèmes complexes en plusieurs étapes, tels que l’optimisation et la planification.
Les humains, quant à eux, s’appuient sur leur intuition issue d’expériences similaires pour résoudre de nouveaux problèmes.
Les grands modèles ne peuvent pas le faire en raison de leurs limitations inhérentes.
Étant donné que la connaissance du LLM provient entièrement des modèles présents dans les données de formation, elle ne peut pas vraiment comprendre le langage ou les concepts. Par conséquent, en tant que modèles statistiques, ils sont difficiles à réaliser des généralisations combinatoires complexes.
 Le plus important est que LLM manque de capacités de raisonnement systématique et ne peut pas raisonner étape par étape comme les humains pour résoudre des problèmes difficiles.
Le plus important est que LLM manque de capacités de raisonnement systématique et ne peut pas raisonner étape par étape comme les humains pour résoudre des problèmes difficiles.
De plus, le raisonnement des grands modèles est local et « myope », il est donc difficile pour LLM de trouver la meilleure solution et de maintenir la cohérence du raisonnement sur une longue période de temps.
En bref, les lacunes des grands modèles en matière de preuve mathématique, de planification stratégique et de raisonnement logique proviennent principalement de deux problèmes fondamentaux :
**- Incapacité de réutiliser les informations issues de l’expérience précédente. **
Les humains accumulent des connaissances et des intuitions réutilisables issues de la pratique qui aident à résoudre de nouveaux problèmes. En revanche, LLM aborde chaque problème « à partir de zéro » et n’emprunte pas aux solutions précédentes.
**- Erreurs composées dans le raisonnement en plusieurs étapes. **
Les humains surveillent leurs propres chaînes de raisonnement et modifient les étapes initiales si nécessaire. Mais les erreurs commises par le LLM dans les premiers stades du raisonnement sont amplifiées car elles conduisent le raisonnement ultérieur sur une mauvaise voie.
Les faiblesses ci-dessus entravent sérieusement l’application du LLM pour faire face à des défis complexes qui nécessitent une optimisation globale ou une planification à long terme.
À cet égard, les chercheurs ont proposé une toute nouvelle communication axée sur les solutions.
Cadre TP
Grâce à la pensée analogique, LLM peut raisonner davantage comme les humains.
Selon les chercheurs, raisonner à partir de zéro ne peut pas réutiliser les connaissances acquises lors de la résolution de problèmes similaires, et les erreurs s’accumuleront au cours des étapes de raisonnement intermédiaires.
La « diffusion de la pensée » peut explorer des problèmes similaires liés au problème d’entrée et s’inspirer de solutions à des problèmes similaires.
 La figure ci-dessous montre la comparaison entre la « propagation de pensée » (TP) et d’autres technologies représentatives. Pour le problème d’entrée p, IO, CoT et ToT raisonneront à partir de zéro pour arriver à la solution s.
La figure ci-dessous montre la comparaison entre la « propagation de pensée » (TP) et d’autres technologies représentatives. Pour le problème d’entrée p, IO, CoT et ToT raisonneront à partir de zéro pour arriver à la solution s.
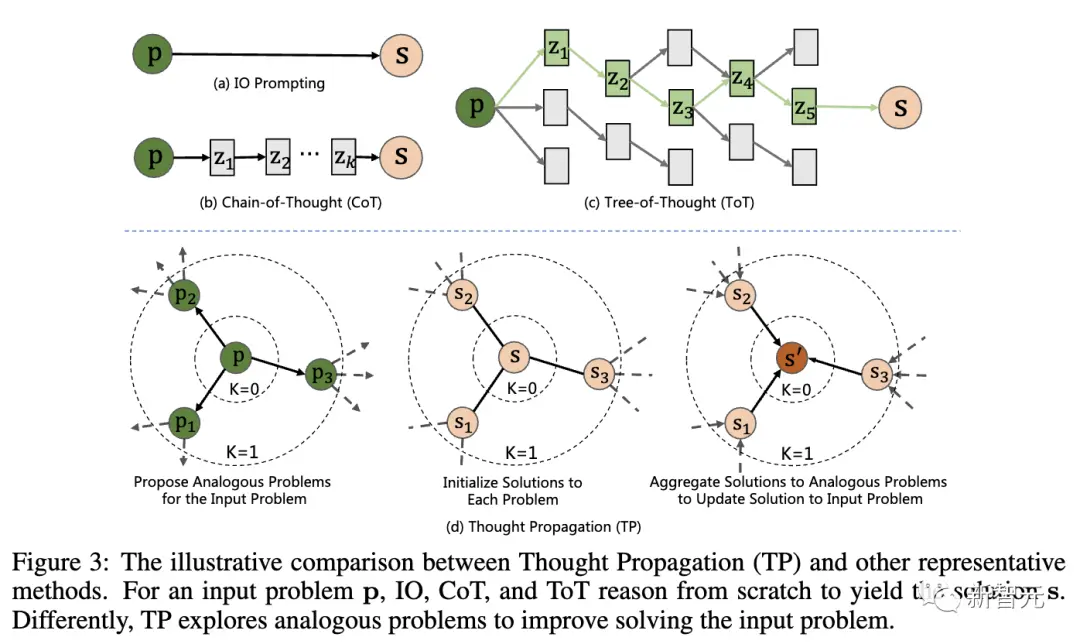 Plus précisément, TP comprend trois étapes :
Plus précisément, TP comprend trois étapes :
**1. Posez des questions similaires : **LLM génère un ensemble de questions similaires qui présentent des similitudes avec la question d’entrée via des invites. Cela guidera le modèle pour récupérer des expériences antérieures potentiellement pertinentes.
**2. Résoudre des problèmes similaires : ** Laissez LLM résoudre chaque problème similaire grâce à la technologie d’invite existante, telle que CoT.
**3. Résumer les solutions : **Il existe 2 approches différentes : déduire directement de nouvelles solutions au problème d’entrée sur la base de solutions analogues ; dériver des plans ou des stratégies de haut niveau en comparant des solutions analogues au problème d’entrée.
Cela permet aux grands modèles de réutiliser l’expérience et les heuristiques précédentes, et également de recouper leur raisonnement initial avec des solutions analogiques pour affiner ces solutions.
Il convient de mentionner que la « propagation de la pensée » n’a rien à voir avec le modèle et peut effectuer une seule étape de résolution de problème basée sur n’importe quelle méthode d’invite.
La principale nouveauté de cette méthode est de stimuler la pensée analogique LLM pour guider des processus de raisonnement complexes.
La question de savoir si « penser la communication » peut faire en sorte que le LLM ressemble davantage à un humain dépend des résultats réels.
Des chercheurs de l’Académie chinoise des sciences et de Yale ont mené l’évaluation en 3 tâches :
**- Raisonnement sur le plus court chemin : **La nécessité de trouver le meilleur chemin entre les nœuds d’un graphique nécessite une planification et une recherche globales. Même sur des graphiques simples, les techniques standards échouent.
**- Écriture créative : ** Générer des histoires cohérentes et créatives est un défi ouvert. Lorsqu’on lui donne des invites générales de haut niveau, LLM perd souvent sa cohérence ou sa logique.
- Planification des agents LLM : les agents LLM interagissant avec des environnements textuels ont eu du mal avec les stratégies à long terme. Leurs plans « dérivent » souvent ou restent bloqués dans des cycles.
Raisonnement sur le plus court chemin
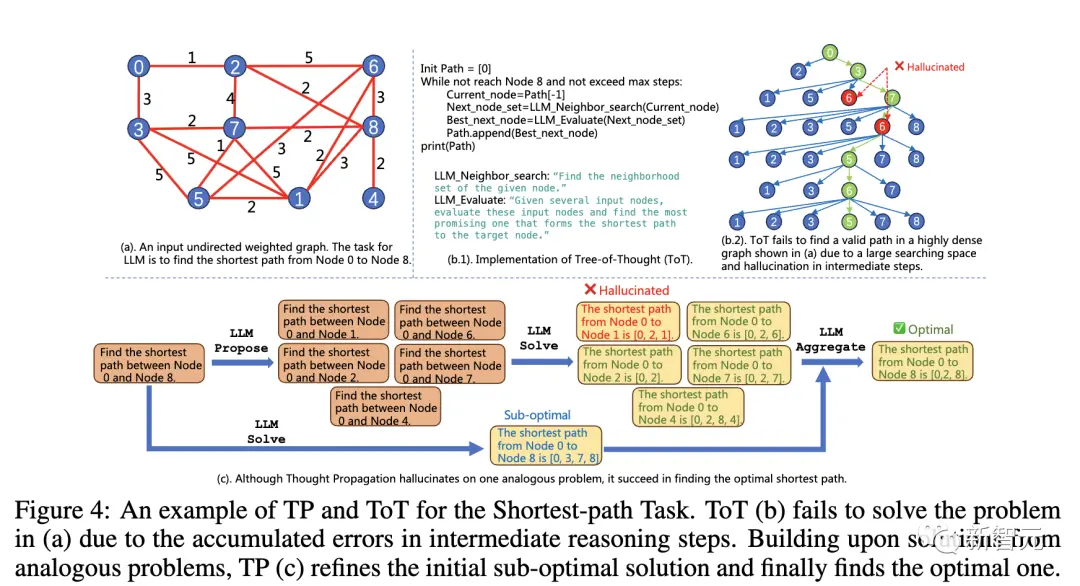
Dans la tâche de raisonnement sur le plus court chemin, les problèmes rencontrés par les méthodes existantes ne peuvent pas être résolus.
Bien que le graphique de (a) soit très simple, puisque l’inférence part de 0, ces méthodes permettent uniquement à LLM de trouver des solutions sous-optimales (b, c) ou même de visiter à plusieurs reprises le nœud intermédiaire (d).
 Ce qui suit est un exemple de combinaison de TP et ToT.
Ce qui suit est un exemple de combinaison de TP et ToT.
ToT (b) ne peut pas résoudre le problème en (a) en raison de l’accumulation d’erreurs dans les étapes de raisonnement intermédiaires. Sur la base de solutions à des problèmes similaires, TP © affine la solution sous-optimale initiale et trouve finalement la solution optimale.
 En comparaison avec la référence, les performances de TP dans le traitement de la tâche du chemin le plus court sont considérablement améliorées de 12 %, générant ainsi des chemins les plus courts optimaux et efficaces.
En comparaison avec la référence, les performances de TP dans le traitement de la tâche du chemin le plus court sont considérablement améliorées de 12 %, générant ainsi des chemins les plus courts optimaux et efficaces.
De plus, en raison de l’OLR le plus bas, le chemin effectif généré par TP est le plus proche du chemin optimal par rapport à la ligne de base.
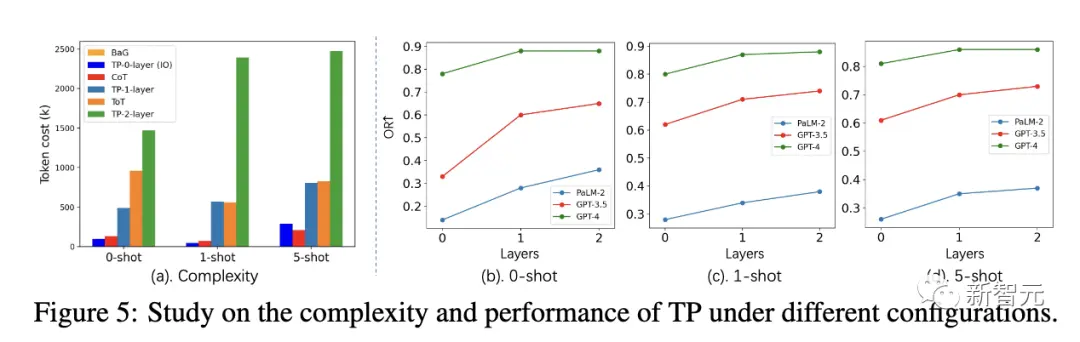
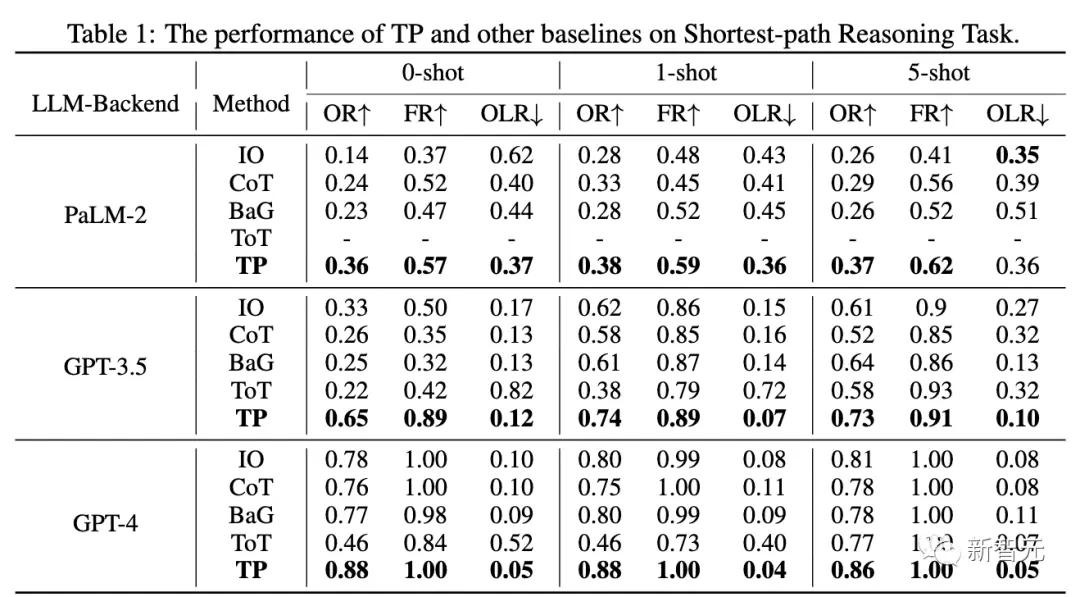 Dans le même temps, les chercheurs ont étudié plus en détail l’impact du nombre de couches TP sur la complexité et les performances de la tâche du chemin le plus court.
Dans le même temps, les chercheurs ont étudié plus en détail l’impact du nombre de couches TP sur la complexité et les performances de la tâche du chemin le plus court.
Dans différents paramètres, le coût du jeton du TP de couche 1 est similaire à celui du ToT. Cependant, la couche 1 TP a atteint des performances très compétitives dans la recherche du chemin le plus court optimal.
De plus, le gain de performances du TP de couche 1 est également très significatif par rapport au TP de couche 0 (IO). La figure 5(a) montre l’augmentation du coût du jeton pour le TP de couche 2.
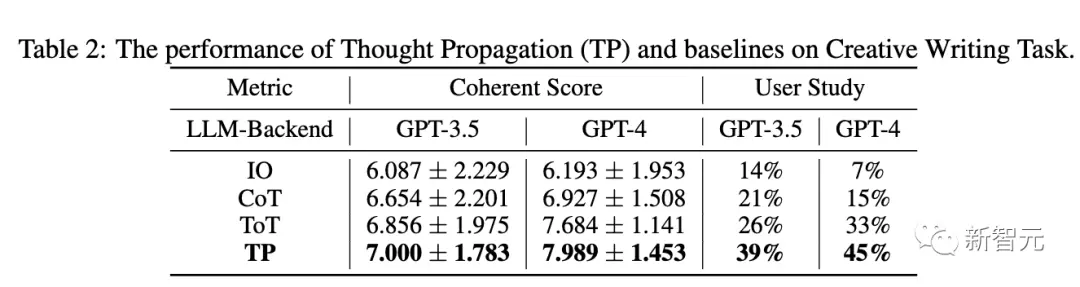
Écriture créative
Le tableau 2 ci-dessous montre les performances du TP et de la ligne de base dans GPT-3.5 et GPT-4. En termes de cohérence, TP dépasse la référence. De plus, dans des études d’utilisateurs, TP a augmenté de 13 % la préférence humaine pour l’écriture créative.
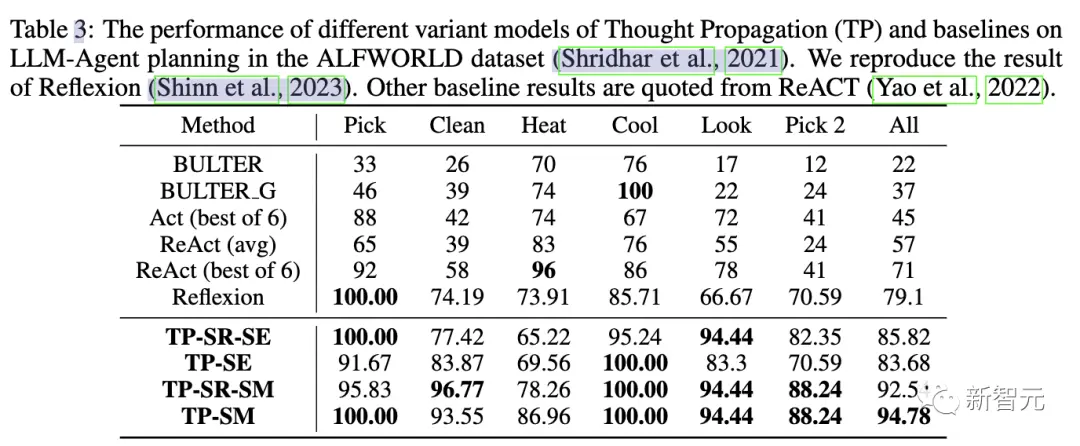
Planification des agents LLM
Lors de la troisième évaluation de la tâche, les chercheurs ont utilisé la suite de jeux ALFWorld pour instancier la tâche de planification d’agent LLM dans 134 environnements.
TP augmente le taux d’achèvement des tâches de 15 % dans la planification des agents LLM. Cela démontre la supériorité du TP réflexif pour une planification réussie lors de l’exécution de tâches similaires.
 Les résultats expérimentaux ci-dessus montrent que la « propagation de la pensée » peut être généralisée à une variété de tâches de raisonnement différentes et qu’elle fonctionne bien dans toutes ces tâches.
Les résultats expérimentaux ci-dessus montrent que la « propagation de la pensée » peut être généralisée à une variété de tâches de raisonnement différentes et qu’elle fonctionne bien dans toutes ces tâches.
Clés pour une inférence LLM améliorée
Le modèle de « propagation de la pensée » fournit une nouvelle technologie pour le raisonnement LLM complexe.
La pensée analogique est une caractéristique des capacités humaines de résolution de problèmes et peut conduire à une série d’avantages systémiques, tels qu’une recherche et une correction d’erreurs plus efficaces.
De même, le LLM peut également mieux surmonter ses propres faiblesses, telles que le manque de connaissances réutilisables et les erreurs locales en cascade, en incitant à une réflexion analogique.
Il existe cependant certaines limites à ces résultats.
Générer efficacement des questions d’analogie utiles n’est pas facile, et des chaînes plus longues de chemins de raisonnement analogique peuvent devenir lourdes. Dans le même temps, contrôler et coordonner des chaînes de raisonnement à plusieurs étapes reste difficile.
Cependant, la « propagation de la pensée » nous offre toujours une méthode intéressante en résolvant de manière créative les défauts de raisonnement du LLM.
Avec un développement ultérieur, la pensée analogique pourrait rendre le raisonnement de LLM encore plus puissant. Et cela ouvre également la voie à un raisonnement plus humain dans les grands modèles de langage.
A propos de l’auteur
Ran He
 Il est professeur au National Experimental Key Laboratory of Pattern Recognition de l’Institut d’automatisation, de l’Académie chinoise des sciences et de l’Université de l’Académie chinoise des sciences, membre de l’IAPR et membre senior de l’IEEE.
Il est professeur au National Experimental Key Laboratory of Pattern Recognition de l’Institut d’automatisation, de l’Académie chinoise des sciences et de l’Université de l’Académie chinoise des sciences, membre de l’IAPR et membre senior de l’IEEE.
Auparavant, il a obtenu sa licence et sa maîtrise à l’Université de technologie de Dalian, ainsi que son doctorat à l’Institut d’automatisation de l’Académie chinoise des sciences en 2009.
Ses intérêts de recherche portent sur les algorithmes biométriques (reconnaissance et synthèse de visages, reconnaissance de l’iris, ré-identification de personnes), l’apprentissage des représentations (réseaux de pré-formation utilisant l’apprentissage faible/auto-supervisé ou par transfert), l’apprentissage génératif (modèles génératifs, génération d’images, traduction d’images). ).
Il a publié plus de 200 articles dans des revues et conférences internationales, y compris des revues internationales célèbres telles que IEEE TPAMI, IEEE TIP, IEEE TIFS, IEEE TNN et IEEE TCSVT, ainsi que dans des conférences internationales de premier plan telles que CVPR, ICCV, ECCV et NeuroIPS.
Il est membre des comités de rédaction de l’IEEE TIP, de l’IEEE TBIOM et de Pattern Recognition, et a été président régional de conférences internationales telles que CVPR, ECCV, NeurIPS, ICML, ICPR et IJCAI.
Junchi Yu(俞UN驰)
 Yu Junchi est doctorant en quatrième année à l’Institut d’automatisation de l’Académie chinoise des sciences, et son superviseur est le professeur Heran.
Yu Junchi est doctorant en quatrième année à l’Institut d’automatisation de l’Académie chinoise des sciences, et son superviseur est le professeur Heran.
Auparavant, il a effectué un stage au laboratoire d’intelligence artificielle Tencent et a travaillé avec le Dr Tingyang Xu, le Dr Yu Rong, le Dr Yatao Bian et le professeur Junzhou Huang. Actuellement, il est étudiant en échange au département d’informatique de l’université de Yale, auprès du professeur Rex Ying.
Son objectif est de développer des méthodes d’apprentissage graphique de confiance (TwGL) avec une bonne interprétabilité et portabilité et d’explorer leurs applications en biochimie.
Les références:

