Source d’origine : qubits
 Source de l’image : Généré par Unbounded AI
Source de l’image : Généré par Unbounded AI
Certains internautes ont trouvé une autre preuve que GPT-4 est devenu « stupide ».
Il s’est interrogé :
OpenAI met en cache l’historique des réponses, ce qui permet à GPT-4 de relater directement les réponses précédemment générées.
 L’exemple le plus évident est celui des blagues.
L’exemple le plus évident est celui des blagues.
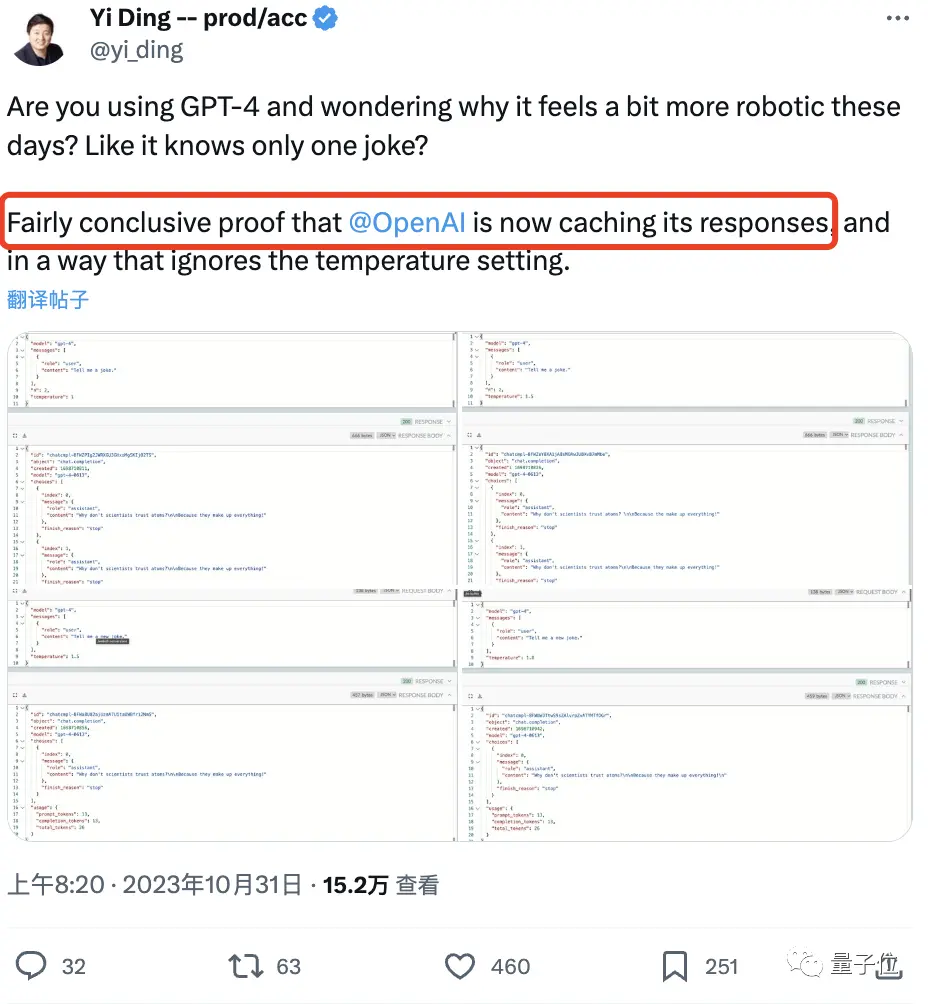
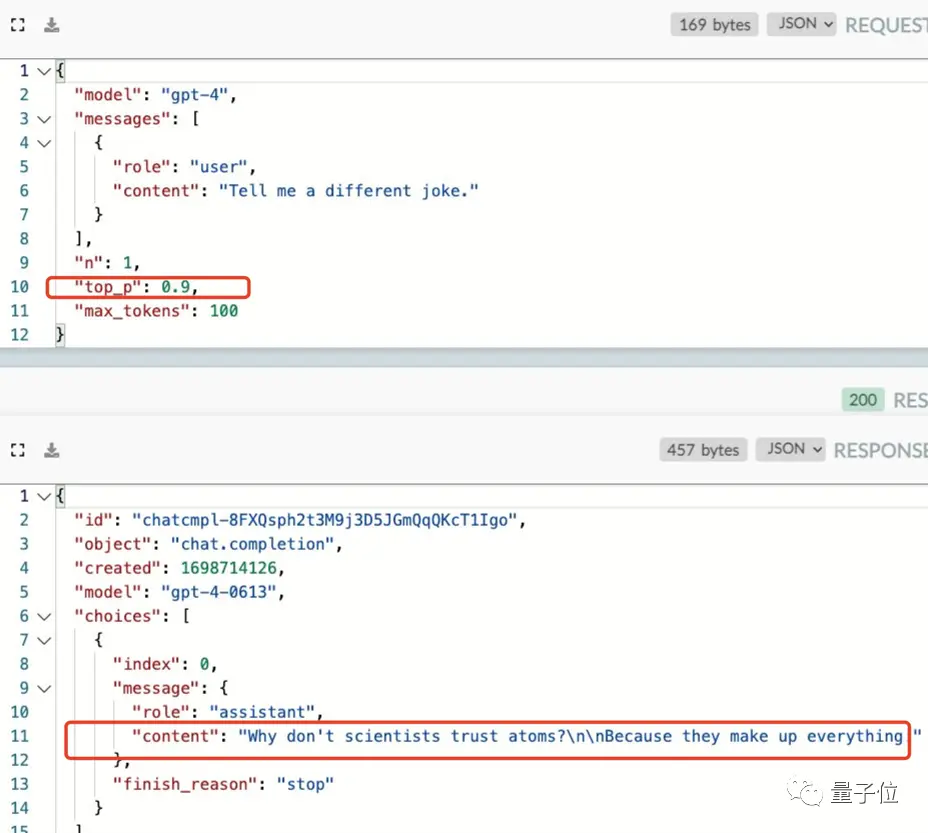
Les preuves montrent que même lorsqu’il a augmenté la valeur de température du modèle, GPT-4 a répété la même réponse « scientifiques et atomes ».
C’est la question « Pourquoi les scientifiques ne font-ils pas confiance aux atomes ? » Parce que tout est inventé « par eux ».
 Ici, il va de soi que plus la valeur de température est élevée, plus il est facile pour le modèle de générer des mots inattendus, et la même blague ne doit pas être répétée.
Ici, il va de soi que plus la valeur de température est élevée, plus il est facile pour le modèle de générer des mots inattendus, et la même blague ne doit pas être répétée.
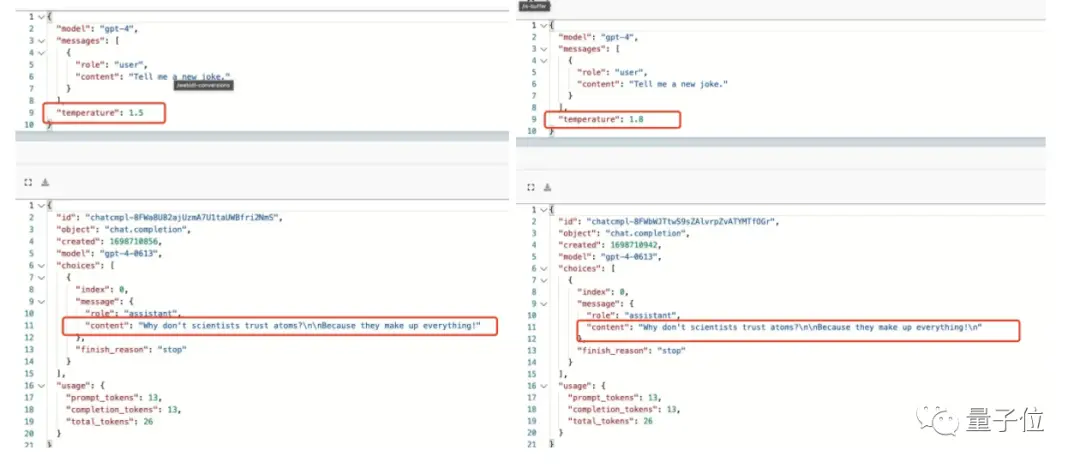
Non seulement cela, mais même si nous ne déplaçons pas les paramètres, changeons la formulation et ne mettons pas l’accent sur le fait qu’il raconte une blague nouvelle et différente, cela n’aidera pas.
 D’après le trouveur :
D’après le trouveur :
Cela montre que GPT-4 utilise non seulement la mise en cache, mais aussi des requêtes en cluster plutôt que de faire correspondre une question exactement.
Les avantages sont évidents et la vitesse de réponse peut être plus rapide.
Cependant, depuis que j’ai acheté un abonnement à un prix élevé, je ne profite que d’un tel service de récupération de cache, et personne n’est content.
 Certaines personnes ressentent après l’avoir lu :
Certaines personnes ressentent après l’avoir lu :
Si c’est le cas, n’est-il pas injuste que nous continuions à utiliser GPT-4 pour évaluer les réponses d’autres grands modèles ?
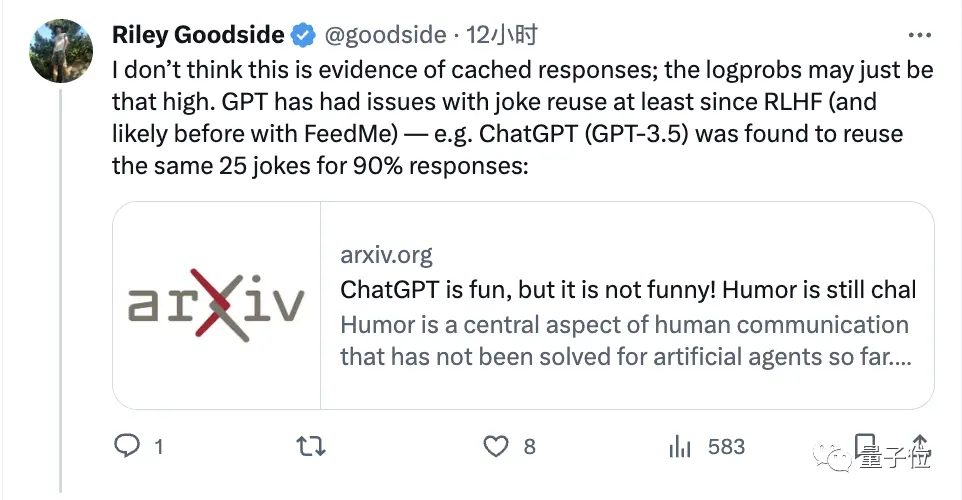
 Bien sûr, il y a aussi des gens qui ne pensent pas que c’est le résultat d’un cache externe, et peut-être que la répétitivité des réponses dans le modèle lui-même est si élevée** :
Bien sûr, il y a aussi des gens qui ne pensent pas que c’est le résultat d’un cache externe, et peut-être que la répétitivité des réponses dans le modèle lui-même est si élevée** :
Des études antérieures ont montré que ChatGPT répète les mêmes 25 blagues 90% du temps.
 Comment dites-vous cela ?
Comment dites-vous cela ?
Preuve Real Hammer GPT-4 avec Cache Reply
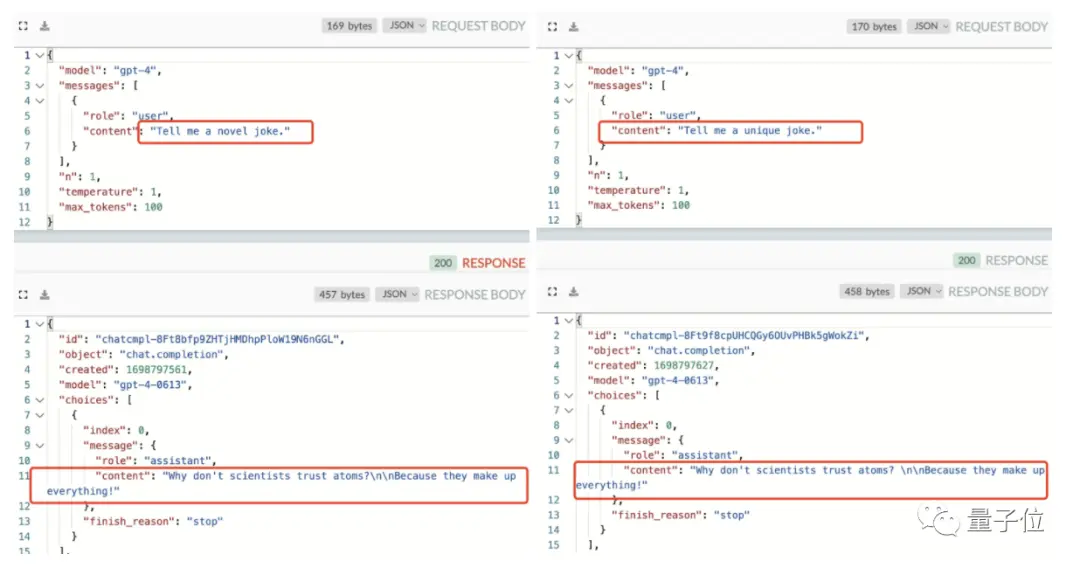
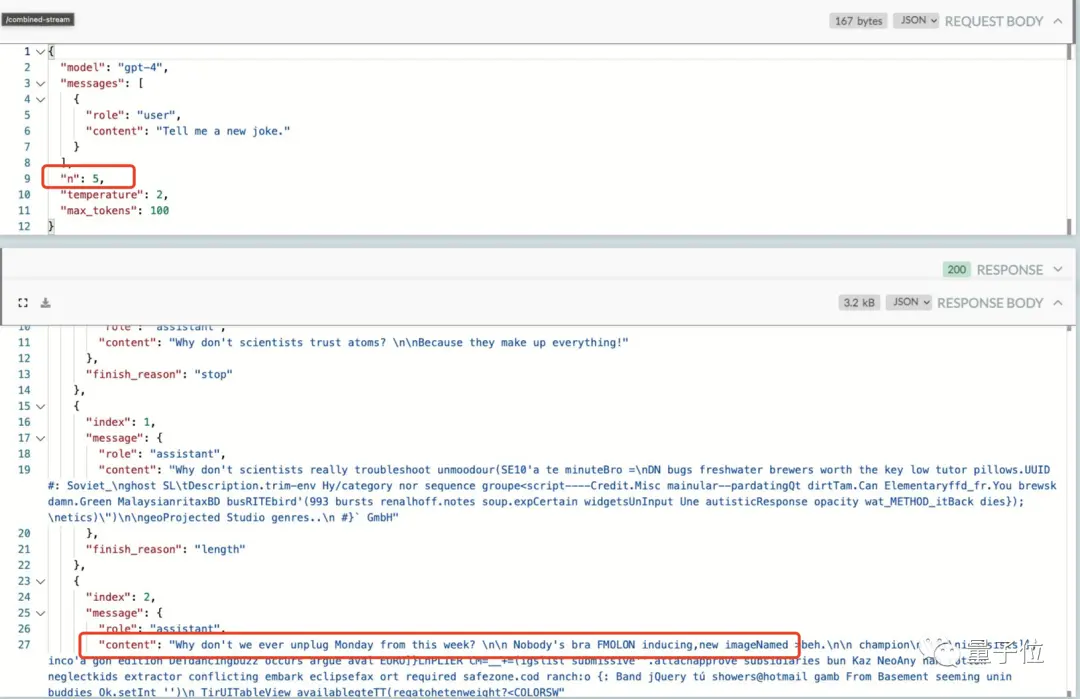
Non seulement il a ignoré la valeur de la température, mais cet internaute a également trouvé :
Il est inutile de changer la valeur top_p du modèle, GPT-4 fait exactement cela.
(top_p : Il est utilisé pour contrôler l’authenticité des résultats renvoyés par le modèle, et la valeur est réduite si vous voulez des réponses plus précises et basées sur des faits, et les réponses les plus diverses sont affichées)
 La seule façon de le déchiffrer est d’extraire le paramètre d’aléatoire n afin que nous puissions obtenir la réponse « non mis en cache » et obtenir une nouvelle blague.
La seule façon de le déchiffrer est d’extraire le paramètre d’aléatoire n afin que nous puissions obtenir la réponse « non mis en cache » et obtenir une nouvelle blague.
 Cependant, cela se fait au « prix » de réponses plus lentes, car il y a un retard dans la génération de nouveaux contenus.
Cependant, cela se fait au « prix » de réponses plus lentes, car il y a un retard dans la génération de nouveaux contenus.
Il convient de mentionner que d’autres semblent avoir trouvé un phénomène similaire sur le modèle local.
 Il a été suggéré que le « prefix-match hit » dans la capture d’écran semble prouver que le cache est effectivement utilisé.
Il a été suggéré que le « prefix-match hit » dans la capture d’écran semble prouver que le cache est effectivement utilisé.
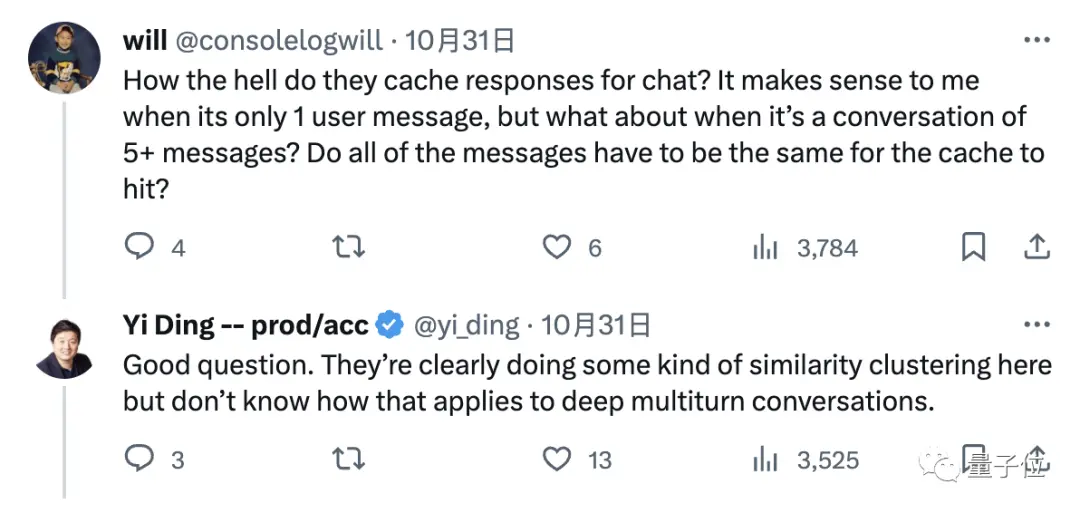
La question est donc la suivante : comment le grand modèle met-il en cache nos informations de chat ?
Bonne question, d’après le deuxième exemple montré au début, il est clair qu’il existe une sorte d’opération de « clustering », mais nous ne savons pas comment l’appliquer à des conversations profondes à plusieurs tours.
 Indépendamment de cette question, certaines personnes ont vu cela et se sont souvenues de la déclaration de ChatGPT selon laquelle « vos données sont stockées chez nous, mais une fois le chat terminé, le contenu de la conversation sera supprimé », et ont soudainement réalisé.
Indépendamment de cette question, certaines personnes ont vu cela et se sont souvenues de la déclaration de ChatGPT selon laquelle « vos données sont stockées chez nous, mais une fois le chat terminé, le contenu de la conversation sera supprimé », et ont soudainement réalisé.
 Cela ne peut qu’inciter certaines personnes à s’inquiéter de la sécurité des données :
Cela ne peut qu’inciter certaines personnes à s’inquiéter de la sécurité des données :
Cela signifie-t-il que les chats que nous lançons sont toujours enregistrés dans leur base de données ?
 Bien sûr, certaines personnes peuvent trop réfléchir à cette préoccupation :
Bien sûr, certaines personnes peuvent trop réfléchir à cette préoccupation :
C’est peut-être simplement parce que nos caches d’intégration de requêtes et de réponses sont stockés.
 Ainsi, comme l’a dit le découvreur lui-même :
Ainsi, comme l’a dit le découvreur lui-même :
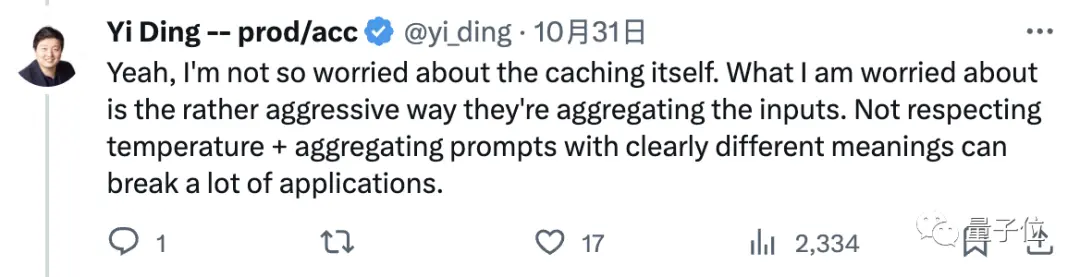
je ne m’inquiète pas trop de la mise en cache elle-même.
je crains qu’OpenAI ne soit si simple et impoli pour résumer nos questions auxquelles répondre, quels que soient les paramètres tels que la température, et agréger directement des invites avec des significations évidemment différentes, ce qui aura un impact négatif et pourrait « mettre au rebut » de nombreuses applications (basées sur GPT-4).
 Bien sûr, tout le monde n’est pas d’accord pour dire que les résultats ci-dessus prouvent qu’OpenAI utilise vraiment des réponses mises en cache.
Bien sûr, tout le monde n’est pas d’accord pour dire que les résultats ci-dessus prouvent qu’OpenAI utilise vraiment des réponses mises en cache.
Leur raisonnement est que le cas adopté par l’auteur se trouve être une blague.
Après tout, en juin de cette année, deux universitaires allemands ont testé et constaté que 90 % des 1 008 résultats de ChatGPT racontant une blague aléatoire étaient des variantes des mêmes 25 blagues.
 « Les scientifiques et les atomes » apparaît le plus fréquemment, avec 119 fois.
« Les scientifiques et les atomes » apparaît le plus fréquemment, avec 119 fois.
Vous pouvez donc comprendre pourquoi il semble que la réponse précédente soit mise en cache.
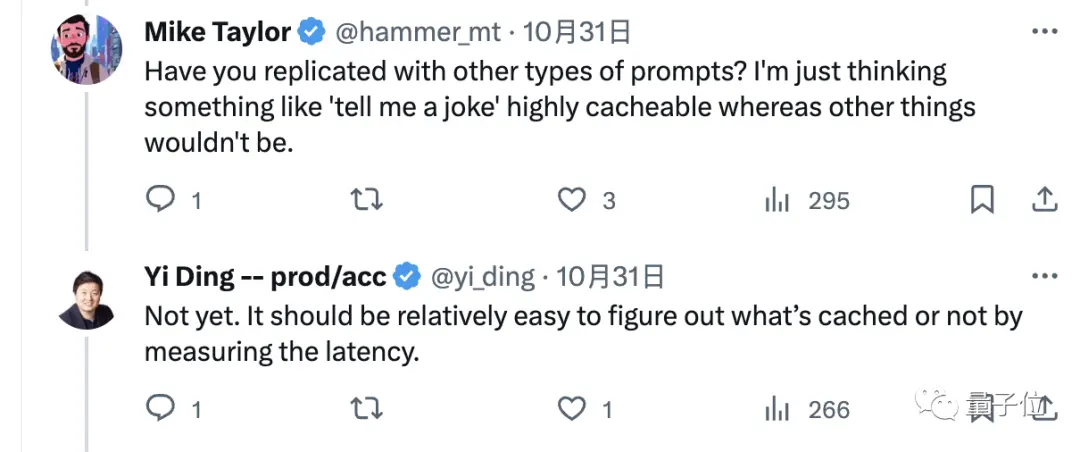
Par conséquent, certains internautes ont également proposé d’utiliser d’autres types de questions pour tester puis voir.
Cependant, les auteurs insistent sur le fait que cela ne doit pas être un problème et qu’il est facile de savoir s’il est mis en cache simplement en mesurant la latence.
 Enfin, examinons cette question d’un point de vue différent :
Enfin, examinons cette question d’un point de vue différent :
Qu’y a-t-il de mal à ce que GPT-4 raconte une blague tout le temps ?
N’avons-nous pas toujours insisté sur la nécessité de disposer de grands modèles pour produire des réponses cohérentes et fiables ? Non, comme il est obéissant (tête de chien manuelle).
 Alors, GPT-4 a-t-il des caches ou non, et avez-vous observé quelque chose de similaire ?
Alors, GPT-4 a-t-il des caches ou non, et avez-vous observé quelque chose de similaire ?
Liens de référence :