Aperçu de la technologie Reddio : de l'EVM parallèle à l'IA - une synthèse narrative
Auteur: Wuyue, geek web3
Dans le contexte d’une évolution de plus en plus rapide de la technologie Blockchain, l’optimisation des performances est devenue un enjeu clé. Le schéma directeur d’Éther est clairement centré sur Rollup, tandis que les caractéristiques de traitement séquentiel des transactions de l’Ethereum Virtual Machine (EVM) constituent une entrave qui ne pourra pas répondre aux futurs scénarios de calcul à haute concurrence.
Dans l’article précédent - “Le chemin de l’optimisation de l’EVM parallèle à partir de Reddio” , nous avons brièvement décrit la conception parallèle de l’EVM de Reddio. Dans cet article d’aujourd’hui, nous allons approfondir sa solution technique et ses scénarios de combinaison avec l’IA.
Le schéma technique de Reddio adopte CuEVM, un projet visant à améliorer l’efficacité de l’exécution de l’EVM en utilisant le GPU. Nous commencerons par CuEVM.
Aperçu de CUDA
CuEVM est un projet d’accélération de l’EVM avec GPU qui convertit les codes opérationnels de l’EVM d’ETH en CUDA Kernels pour une exécution parallèle sur les GPU NVIDIA. Il améliore l’efficacité de l’exécution des instructions EVM en utilisant la puissance de calcul parallèle des GPU. Les utilisateurs de cartes graphiques NVIDIA sont susceptibles d’entendre souvent le terme CUDA.
**Compute Unified Device Architecture, cela est en fait une plate-forme de calcul parallèle et un modèle de programmation développés par NVIDIA. Il permet aux développeurs d’utiliser la capacité de calcul parallèle du GPU pour des calculs généraux (comme le Mining dans Crypto, les opérations ZK, etc.), et pas seulement le traitement graphique.
En tant que cadre de calcul parallèle ouvert, CUDA est essentiellement une extension du langage C/C++, et tout programmeur de bas niveau familier avec C/C++ peut s’y mettre rapidement. Dans CUDA, un concept important est le noyau (kernel), qui est également une fonction C++.

Mais contrairement à une fonction C++ classique qui n’est exécutée qu’une seule fois, ces fonctions de base sont exécutées par N threads CUDA différents en parallèle lors de l’appel de syntaxe <<<…>>>.
Chaque thread de CUDA est attribué un identifiant de thread indépendant et utilise une structure hiérarchique de threads pour attribuer des threads à des blocs et des grilles afin de gérer un grand nombre de threads simultanés. Avec le compilateur nvcc de NVIDIA, nous pouvons compiler le code CUDA en un programme exécutable sur le GPU.

Le flux de travail de base de CuEVM
Après avoir compris une série de concepts fondamentaux de CUDA, on peut examiner le flux de travail de CuEVM.
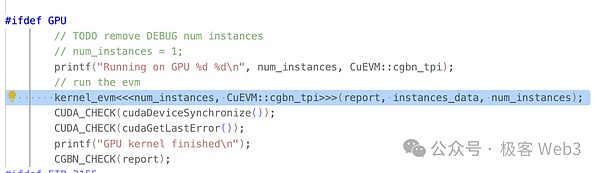
L’entrée principale de CuEVM est run_interpreter, à partir de laquelle les transactions à traiter en parallèle sont saisies sous forme de fichier json. Comme on peut le voir dans les cas d’utilisation du projet, les entrées sont toutes des contenus EVM standard et n’ont pas besoin d’être traitées ou traduites séparément par les développeurs.

Dans run_interpreter(), vous pouvez voir qu’il appelle la syntaxe kernel_evm() du noyau avec la syntaxe <<…>> définie par CUDA. Comme mentionné précédemment, les fonctions de noyau sont appelées en parallèle sur le GPU.
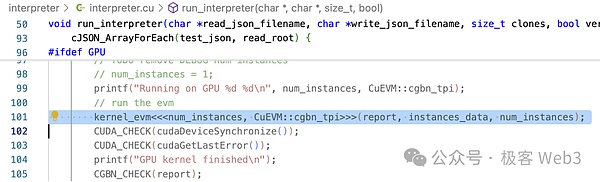
Dans la méthode kernel_evm(), evm->run() est appelée, et nous pouvons voir qu’il y a beaucoup de jugements de branche pour convertir l’opcode EVM en opérations CUDA.
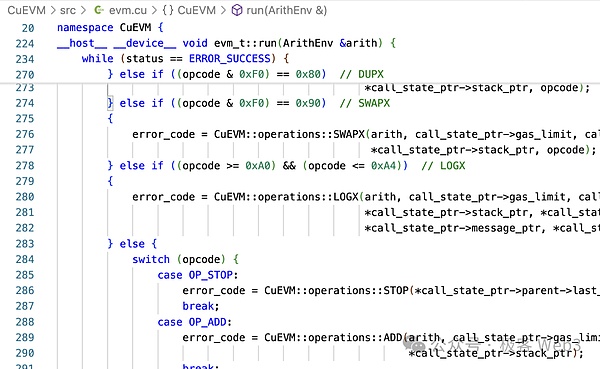
Prenons l’opcode ADD dans l’EVM comme exemple. Nous pouvons voir qu’il est converti en cgbn_add. CGBN (Cooperative Groups Big Numbers) est une bibliothèque de calcul arithmétique à grande précision à haute performance pour CUDA.

Ces deux étapes ont converti le code opération EVM en opération CUDA. On peut dire que CuEVM est également une implémentation de toutes les opérations EVM sur CUDA. Enfin, la méthode run_interpreter() renvoie le résultat de l’opération, c’est-à-dire l’état du monde et d’autres informations.
La logique de base de CuEVM a été présentée jusqu’ici.
CuEVM a la capacité de traiter les transactions en parallèle, mais l’objectif de CuEVM (ou le cas d’utilisation principal) est de réaliser des tests de Fuzzing : Le Fuzzing est une technique de test logiciel automatisée qui consiste à envoyer une grande quantité de données invalides, inattendues ou aléatoires à un programme pour observer sa réponse, afin d’identifier d’éventuelles erreurs et problèmes de sécurité.
Nous pouvons voir que le Fuzzing est très adapté au traitement parallèle. CuEVM ne traite pas les problèmes de conflit de transactions, ce n’est pas ce qui l’intéresse. Si vous souhaitez intégrer CuEVM, vous devez également traiter les transactions en conflit.
Nous avons déjà présenté le mécanisme de traitement des conflits utilisé par Reddio dans un article précédent intitulé “Le chemin de l’optimisation de l’EVM parallèle vu depuis Reddio”, nous n’allons donc pas nous attarder ici. Une fois que Reddio a classé les transactions avec le mécanisme de traitement des conflits, elles peuvent être envoyées à CuEVM. En d’autres termes, le mécanisme de classement des transactions de Reddio L2 se compose de deux parties : le traitement des conflits et l’exécution parallèle de CuEVM.
Layer2, EVM parallèle, la bifurcation de l’IA
L’article précédent a mentionné que la mise en parallèle de l’EVM et de la L2 n’est qu’un début pour Reddio, et que sa feuille de route future sera clairement combinée avec l’intelligence artificielle. Reddio, qui utilise les GPU pour des transactions parallèles à grande vitesse, est naturellement adapté à de nombreuses fonctionnalités de calcul AI.
- La capacité de traitement parallèle des GPU est forte, ce qui convient à l’exécution des opérations de convolution dans l’apprentissage en profondeur, ces opérations étant essentiellement des multiplications de matrices à grande échelle, et les GPU sont optimisés pour ce type de tâches.
- La structure de hiérarchie des threads GPU peut correspondre aux différentes structures de données dans le calcul AI, en améliorant l’efficacité de calcul grâce à l’hyperallocation de threads et à l’exécution des unités de Warp, et en masquant la latence de la mémoire.
- L’intensité de calcul est un indicateur clé de la performance de calcul de l’IA. Les GPU optimisent l’intensité de calcul, telle que l’introduction de Tensor Core, pour améliorer les performances de multiplication de matrices dans le calcul de l’IA et réaliser un équilibre efficace entre le calcul et le transfert de données.
Alors, comment l’IA se combine-t-elle avec L2 ?
Nous savons que dans la conception de l’architecture Rollup, l’ensemble du réseau ne se compose pas seulement d’ordonnanceurs, mais également de certains rôles similaires à des superviseurs et des relais pour vérifier ou collecter des transactions. Ils utilisent essentiellement le même client que l’ordonnanceur, mais assument des fonctions différentes. Dans un Rollup traditionnel, les fonctions et les autorisations de ces rôles mineurs sont très limitées, comme le rôle de “watcher” dans Arbitrum, qui est essentiellement passif, défensif et philanthropique, et son modèle de profit est également douteux.
Reddio adoptera l’architecture de l’agrégateur Décentralisation, les Mineurs fourniront des GPU en tant que Nœuds. ** Tout le réseau Reddio peut évoluer d’un simple L2 à un réseau intégré L2+AI, ce qui permet de bien mettre en œuvre certains cas d’utilisation AI+Bloc chaîne : **
Le réseau de base d’interaction de l’agent AI
Avec l’évolution continue de la technologie Blockchain, le potentiel d’application des AI Agents dans le réseau Blockchain est énorme. Prenons l’exemple des AI Agents chargés d’exécuter des transactions financières, ces agents intelligents peuvent prendre des décisions complexes et exécuter des opérations de transaction de manière autonome, et même réagir rapidement dans des conditions à haute fréquence. Cependant, il est pratiquement impossible pour L1 de supporter une charge de transaction énorme lorsqu’il s’agit de traiter de telles opérations intensives.

En tant que projet L2, Reddio peut considérablement améliorer la capacité de traitement parallèle des transactions grâce à l’accélération GPU. Par rapport à L1, le L2 prend en charge l’exécution parallèle des transactions, ce qui lui confère une plus grande capacité de traitement et lui permet de gérer efficacement les demandes de transactions à haute fréquence de nombreux agents IA, garantissant ainsi le bon fonctionnement du réseau.
Dans le trading à haute fréquence, les exigences de vitesse de transaction et de temps de réponse des agents d’IA sont extrêmement strictes. L2 réduit le temps de vérification et d’exécution des transactions, réduisant ainsi considérablement la latence. Cela est essentiel pour les agents d’IA qui ont besoin de répondre en millisecondes. En déplaçant un grand nombre de transactions vers L2, cela contribue également à atténuer les problèmes de congestion de Mainnet. Rendre les opérations des agents d’IA plus économiques et efficaces.
Avec la maturité de projets L2 tels que Reddio, l’agent AI jouera un rôle plus important off-chain dans le Bloc, stimulant l’innovation de la Finance décentralisée et d’autres scénarios d’application de la chaîne Bloc combinés à l’IA.
DécentralisationPuissance de calcul市场
Reddio adoptera à l’avenir l’architecture du Décentralisation classificateur, où les Mineurs décident du droit de classement en utilisant la Puissance de calcul GPU. Les performances des GPU des participants de l’ensemble du réseau augmenteront progressivement avec la concurrence, atteignant même un niveau utilisable pour l’entraînement de l’IA.
Construire un marché de Puissance de calcul GPU Décentralisation pour fournir des ressources de Puissance de calcul à moindre coût pour l’entraînement et l’inférence de l’IA. De la Puissance de calcul GPU de différents niveaux, allant des ordinateurs personnels aux clusters de salles informatiques, peut être ajoutée à ce marché pour contribuer à la Puissance de calcul inutilisée et générer des revenus. Ce modèle peut réduire les coûts de calcul de l’IA et permettre à davantage de personnes de participer au développement et à l’application de modèles d’IA.
Dans les cas d’utilisation de la Puissance de calcul Décentralisation, le trieuse peut ne pas être principalement responsable du calcul direct de l’IA. Sa fonction principale est de traiter les transactions et de coordonner la Puissance de calcul de l’IA dans l’ensemble du réseau. **En ce qui concerne la Puissance de calcul et la répartition des tâches, il existe deux modes: **
- Distribution centralisée de haut en bas. En raison de l’existence d’un trieur, le trieur peut distribuer les demandes de puissance de calcul reçues aux nœuds répondant aux exigences et ayant une bonne réputation. Bien que ce mode de distribution présente théoriquement des problèmes de centralisation et d’injustice, en réalité, les avantages d’efficacité l’emportent largement sur les inconvénients. À long terme, le trieur doit satisfaire à la positivité de l’ensemble du réseau pour se développer durablement, c’est-à-dire qu’il existe une contrainte implicite mais directe qui garantit que le trieur ne sera pas trop biaisé.
- Sélection de tâches spontanées de bas en haut. Les utilisateurs peuvent également soumettre des demandes de calcul AI à un Nœud tiers, ce qui est évidemment plus efficace que de les soumettre directement à un ordonnanceur dans des domaines d’application AI spécifiques, et cela permet également d’éviter l’examen et le parti pris de l’ordonnanceur. Une fois les calculs terminés, ce Nœud synchronise les résultats de calcul avec l’ordonnanceur et les met en chaîne.
On peut voir que dans l’architecture L2 + AI, le marché de la Puissance de calcul a une grande flexibilité et peut rassembler la Puissance de calcul dans deux directions pour maximiser l’utilisation des ressources.
Inférence hors chaîne AI
Actuellement, la maturité du modèle Open Source est suffisante pour répondre à divers besoins. Avec la normalisation des services d’inférence IA, il est possible d’explorer la mise en chaîne de la Puissance de calcul pour réaliser une tarification automatisée. Cependant, cela nécessite de relever plusieurs défis techniques :
- Distribution et enregistrement efficaces des demandes : L’inférence de modèles volumineux exige une latence élevée, il est donc crucial d’avoir un mécanisme de distribution des demandes efficace. Bien que les volumes de données des demandes et des réponses soient énormes et confidentiels, ils ne doivent pas être rendus publics sur la chaîneBloc-off, mais il est nécessaire de trouver un équilibre entre l’enregistrement et la vérification, par exemple, en utilisant le stockage des hachages.
- Vérification de la Puissance de calculNœud : Nœud a-t-il réellement accompli la tâche de calcul spécifiée ? Par exemple, est-ce que Nœud a faussement déclaré des résultats de calcul de petit modèle pour remplacer un grand modèle ?
- Raisonnement sur les smart contracts : il est souvent nécessaire de combiner des modèles d’IA avec des smart contracts pour effectuer des calculs dans de nombreux scénarios. En raison de l’incertitude associée au raisonnement de l’IA, il n’est pas possible de l’utiliser pour tous les aspects hors chaîne, de sorte que la logique des futurs dApp d’IA sera probablement en partie hors chaîne et en partie régie par des contrats hors chaîne, qui imposeront des limitations sur la validité et la légitimité des entrées fournies hors chaîne. Dans l’écosystème d’Éther, la combinaison avec les smart contracts implique de faire face à l’inefficacité sérielle de l’EVM.
Cependant, dans l’architecture de Reddio, tout cela est relativement facile à résoudre :
- Le planificateur de distribution des demandes est beaucoup plus efficace que L1 et peut être considéré comme ayant la même efficacité que Web2. Quant à l’emplacement et la méthode de conservation des données, ils peuvent être résolus par diverses solutions DA peu coûteuses. Les résultats des calculs de l’IA peuvent finalement être vérifiés pour leur exactitude et leur bienveillance par ZKP. La caractéristique de ZKP est une vérification très rapide, mais une génération de preuves plus lente. De plus, la génération de ZKP peut également être accélérée à l’aide de GPU ou de TEE.
- Solidty → CUDA → GPU, cette ligne principale de parallélisme EVM est déjà la base de Reddio. Donc en apparence, c’est le problème le plus simple pour Reddio. Actuellement, Reddio collabore avec eliza d’AiI6z pour intégrer son module dans Reddio, ce qui est une direction très prometteuse à explorer.
Résumé
Dans l’ensemble, les solutions Layer2, l’EVM parallèle et la technologie AI semblent être sans rapport, mais Reddio a habilement combiné ces grands domaines d’innovation en utilisant pleinement les caractéristiques de calcul du GPU.
En exploitant les caractéristiques de calcul parallèle du GPU, Reddio a amélioré la vitesse et l’efficacité des transactions sur Layer2, renforçant ainsi les performances de la couche 2 d’ETH. L’intégration de la technologie de l’IA dans la blockchain est une tentative nouvelle et prometteuse. L’introduction de l’IA peut fournir une analyse et un soutien décisionnel intelligents pour les opérations off-chain, permettant ainsi des applications blockchain plus intelligentes et dynamiques. Cette intégration interdisciplinaire ouvre sans aucun doute de nouvelles voies et opportunités pour l’ensemble de l’industrie.
Cependant, il convient de noter que ce domaine en est encore à ses débuts et nécessite encore beaucoup de recherche et d’exploration. L’itération et l’optimisation continues de la technologie, ainsi que l’imagination et l’action des pionniers du marché, seront des moteurs clés pour faire avancer cette innovation vers la maturité. Reddio a déjà franchi une étape importante et audacieuse à ce carrefour, et nous sommes impatients de voir plus de percées et de surprises dans ce domaine d’intégration à l’avenir.