En bref
- Microsoft a publié deux modes différents qui associent GPT et Claude pour améliorer la qualité de la recherche en IA.
- Critique fait collaborer les modèles, tandis que Council les fait travailler en parallèle, pendant qu’un troisième juge repère les écarts.
- Ce workflow à deux modèles corrige les hallucinations, les citations faibles et d’autres problèmes liés à la recherche en IA avec un seul modèle.
L’IA de recherche approfondie fait partie des courses aux armements technologiques les plus en vogue cette année. Google a annoncé son agent de recherche pour Gemini en décembre 2024, OpenAI a publié son propre agent de recherche en février 2025, xAI a suivi, Perplexity a redoublé d’efforts, et Anthropic a bâti une solide base de fidèles parmi les professionnels qui ont besoin de réponses détaillées et sourcées, en lançant son agent en avril de l’an dernier.
Chaque entreprise a essayé de vous convaincre que son unique modèle d’IA est le chercheur le plus intelligent de la pièce. Microsoft vient de dire : Pourquoi n’en choisir qu’un ?
La société a annoncé deux nouvelles fonctionnalités lundi pour l’outil Researcher de Copilot — appelées Critique et Council — qui font travailler les GPT d’OpenAI et les Claude d’Anthropic sur la même tâche de recherche, l’un après l’autre. Le résultat, d’après les tests de Microsoft face à un benchmark du secteur, est supérieur à tous les systèmes inclus dans ce test, y compris les modèles des plus grandes entreprises d’IA.
Présentation de Critique, un nouveau système de recherche approfondie multi-modèles dans M365 Copilot.
Vous pouvez utiliser plusieurs modèles ensemble pour générer des réponses et des rapports optimaux. pic.twitter.com/m4RlQmCKzs
— Satya Nadella (@satyanadella) March 30, 2026
« Critique est un nouveau système de recherche approfondie multi-modèles conçu pour des tâches de recherche complexes. Il sépare la génération de l’évaluation et utilise une combinaison de modèles provenant des laboratoires Frontier, notamment Anthropic et OpenAI », explique Microsoft. « Un modèle dirige la phase de génération — planification de la tâche, itération à travers la récupération des informations et production d’un premier brouillon — tandis qu’un second modèle se concentre sur la relecture et l’affinage, agissant comme un évaluateur expert avant que le rapport final ne soit produit. »
Voici le problème de base que Critique est conçu à corriger : aujourd’hui, chaque outil de recherche en IA fonctionne de la même manière. Vous posez une question, un modèle planifie une recherche, parcourt des sources, rédige un rapport et vous le rend. Ce seul modèle fait tout, sans personne pour vérifier son travail.
Cela peut laisser passer certaines hallucinations, certaines erreurs dans les citations, des affirmations fausses ou inexactes, etc.
Critique casse ce workflow en deux. GPT gère la première phase : il planifie la recherche, récupère des sources et rédige un premier brouillon. Ensuite, Claude intervient comme un éditeur strict, en examinant le rapport pour en vérifier la exactitude factuelle, la qualité des citations et le point de savoir si la réponse a réellement traité la question posée. Ce n’est qu’après cette relecture que le rapport final parvient à l’utilisateur. Microsoft indique que les rôles peuvent aussi finir par s’inverser, avec Claude qui rédige et GPT qui critique, mais pour l’instant GPT commence.
Sur le benchmark DRACO — un test standardisé couvrant 100 tâches de recherche complexes dans 10 domaines, dont la médecine, le droit et la technologie — Copilot avec Critique a obtenu 57.4. points, tandis que la seule version d’Anthropic Claude Opus 4.6 a obtenu 42.7, atteignant à elle seule 57.4. Le système combiné de Microsoft bat le meilleur résultat suivant d’environ 14%.
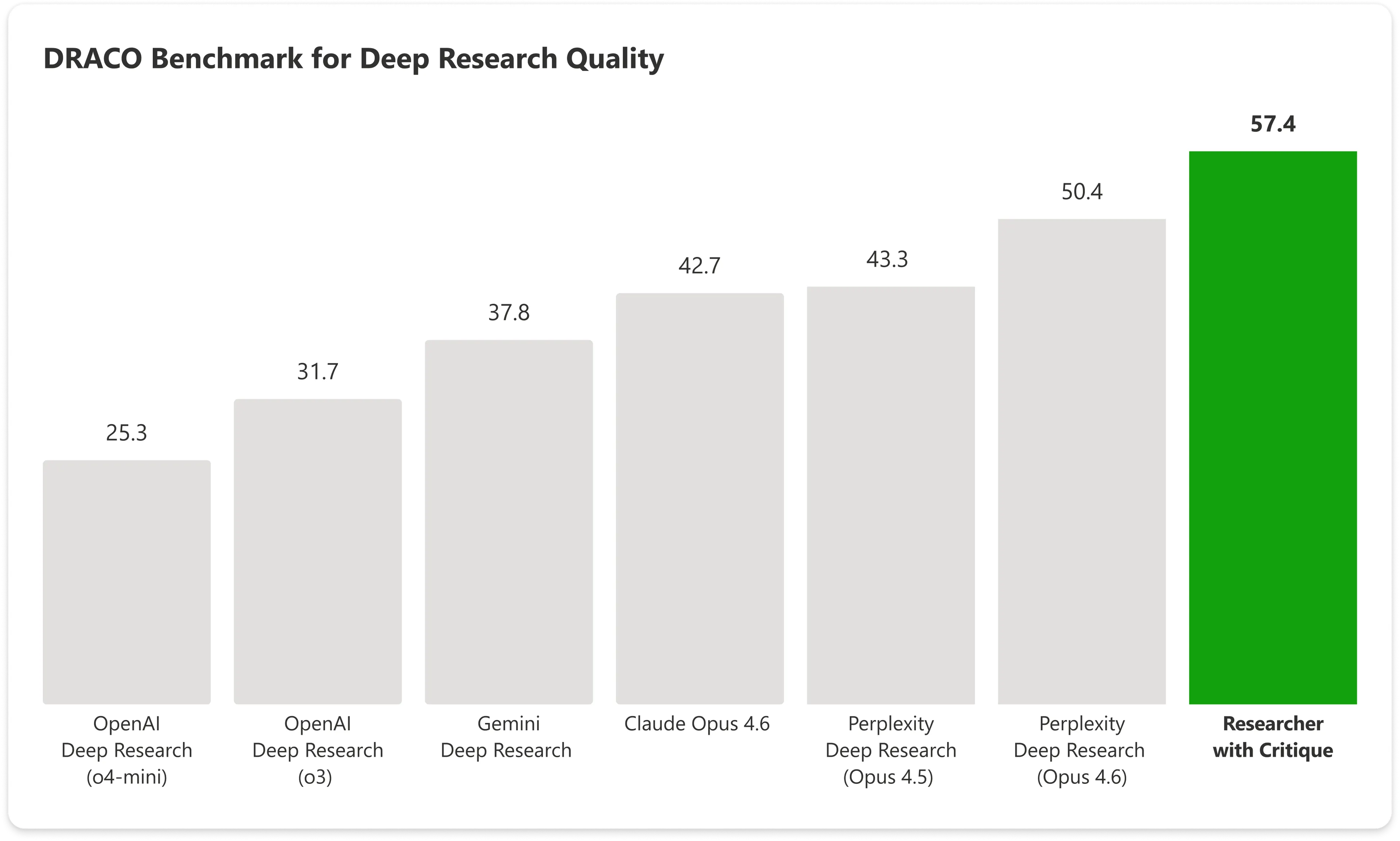
Image : Microsoft
Les plus grandes améliorations se sont vues dans l’étendue de l’analyse et la qualité de la présentation, l’exactitude factuelle enregistrant elle aussi un progrès significatif.
La deuxième fonctionnalité, Council, adopte une approche différente du même problème. Au lieu qu’un modèle examine le travail de l’autre, Council fait tourner GPT et Claude simultanément et place leurs rapports complets côte à côte. Un troisième modèle « juge » lit ensuite les deux et rédige un résumé expliquant où les deux IA sont d’accord, où elles divergent, et quelles perspectives uniques chacune a relevées que l’autre a manquées. Jusqu’à présent, comparer manuellement des outils de recherche en IA était quelque chose que les utilisateurs devaient faire eux-mêmes.
Dans Critique, les modèles collaborent essentiellement entre eux, tandis que dans Council les modèles s’opposent l’un à l’autre.
Critique est l’expérience par défaut dans Researcher, tandis que Council vous oblige à sélectionner « Model Council » dans le sélecteur pour activer le mode côte à côte. Ces deux fonctionnalités sont actuellement disponibles pour les utilisateurs inscrits au programme Frontier de Microsoft, le canal d’accès anticipé pour les capacités les plus récentes de Copilot. Une licence Microsoft 365 Copilot (30 $/utilisateur/mois) est nécessaire, mais les utilisateurs doivent également être inscrits à Frontier pour y accéder.
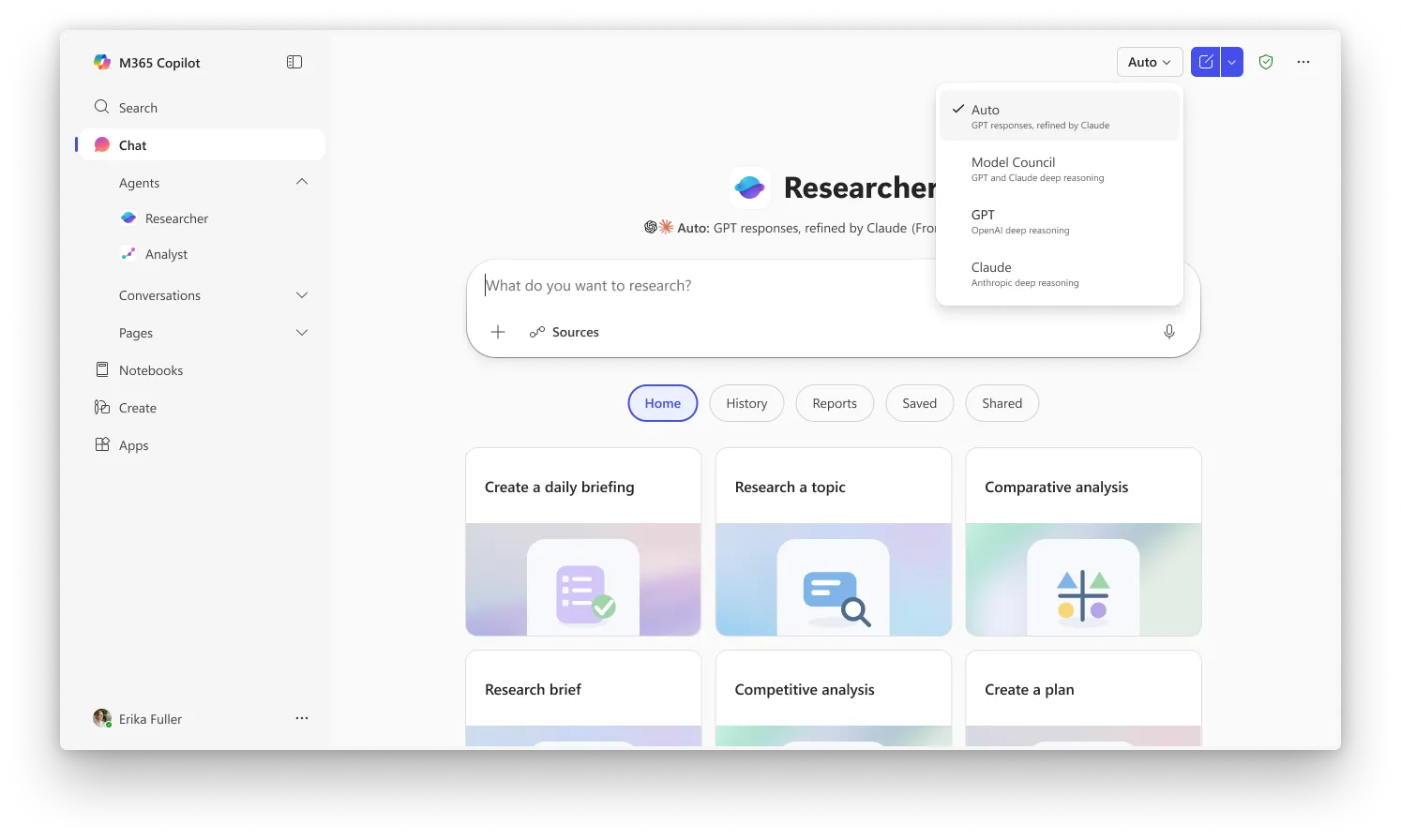
Image : Microsoft
OpenAI et Microsoft ont un partenariat à plusieurs milliards de dollars, mais le pari de Microsoft est qu’aucun modèle ne reste longtemps au sommet, et que la vraie valeur réside dans la couche d’orchestration qui fait acheminer les tâches vers la combinaison qui fonctionne le mieux.
Avertissement : Les informations contenues dans cette page peuvent provenir de tiers et ne représentent pas les points de vue ou les opinions de Gate. Le contenu de cette page est fourni à titre de référence uniquement et ne constitue pas un conseil financier, d'investissement ou juridique. Gate ne garantit pas l'exactitude ou l'exhaustivité des informations et n'est pas responsable des pertes résultant de l'utilisation de ces informations. Les investissements en actifs virtuels comportent des risques élevés et sont soumis à une forte volatilité des prix. Vous pouvez perdre la totalité du capital investi. Veuillez comprendre pleinement les risques pertinents et prendre des décisions prudentes en fonction de votre propre situation financière et de votre tolérance au risque. Pour plus de détails, veuillez consulter l'
avertissement.
