DeepSeek merilis versi preview dari DeepSeek-V4-Pro dan DeepSeek-V4-Flash pada 24 April 2026, keduanya adalah model open-weight dengan jendela konteks satu juta token dan harga yang jauh di bawah alternatif Barat yang sebanding. Model V4-Pro menelan biaya $1.74 per satu juta token input dan $3.48 per satu juta token output—kira-kira 1/20 dari harga Claude Opus 4.7 dan 98% lebih murah daripada GPT-5.5 Pro, menurut spesifikasi resmi perusahaan.
Arsitektur Model dan Skala
DeepSeek-V4-Pro memiliki 1.6 triliun total parameter, menjadikannya model open-source terbesar di pasar LLM hingga saat ini. Namun, hanya 49 miliar parameter yang aktif per sekali inferensi, menggunakan apa yang DeepSeek sebut sebagai pendekatan Mixture-of-Experts yang disempurnakan sejak V3. Desain ini memungkinkan keseluruhan model tetap “tidur” sementara hanya segmen yang relevan yang aktif untuk setiap permintaan tertentu, sehingga mengurangi biaya komputasi sambil mempertahankan kapasitas pengetahuan.
DeepSeek-V4-Flash beroperasi pada skala yang lebih kecil dengan 284 miliar total parameter dan 13 miliar parameter aktif. Menurut benchmark DeepSeek, ia “mencapai kinerja penalaran yang sebanding dengan versi Pro ketika diberi anggaran thinking yang lebih besar.”
Kedua model mendukung konteks satu juta token sebagai fitur standar—kira-kira 750,000 kata, atau kurang lebih seluruh trilogi “Lord of the Rings” ditambah teks tambahan.
Inovasi Teknis: Attention Mechanisms pada Skala
DeepSeek mengatasi masalah penskalaan komputasi yang melekat pada pemrosesan konteks panjang dengan menciptakan dua jenis attention baru, sebagaimana dijelaskan dalam paper teknis perusahaan yang tersedia di GitHub.
Mekanisme attention standar AI menghadapi masalah penskalaan yang kejam: setiap kali panjang konteks berlipat dua, biaya komputasi kira-kira menjadi empat kali lipat. Solusi DeepSeek melibatkan dua pendekatan yang saling melengkapi:
Compressed Sparse Attention bekerja dalam dua langkah. Pertama, ia mengompres kelompok token—misalnya, setiap 4 token—menjadi satu entri. Lalu, alih-alih melakukan attention ke semua entri terkompresi, ia menggunakan “Lightning Indexer” untuk memilih hanya hasil yang paling relevan untuk setiap kueri. Ini mengurangi cakupan attention model dari satu juta token menjadi kumpulan chunk penting yang jauh lebih kecil.
Heavily Compressed Attention mengambil pendekatan yang lebih agresif, menggabungkan setiap 128 token menjadi satu entri tanpa pemilihan sparse. Meskipun ini kehilangan detail yang lebih halus, ia menyediakan gambaran global yang sangat murah. Dua jenis attention ini berjalan pada lapisan yang bergantian, memungkinkan model mempertahankan keduanya: detail dan gambaran umum.
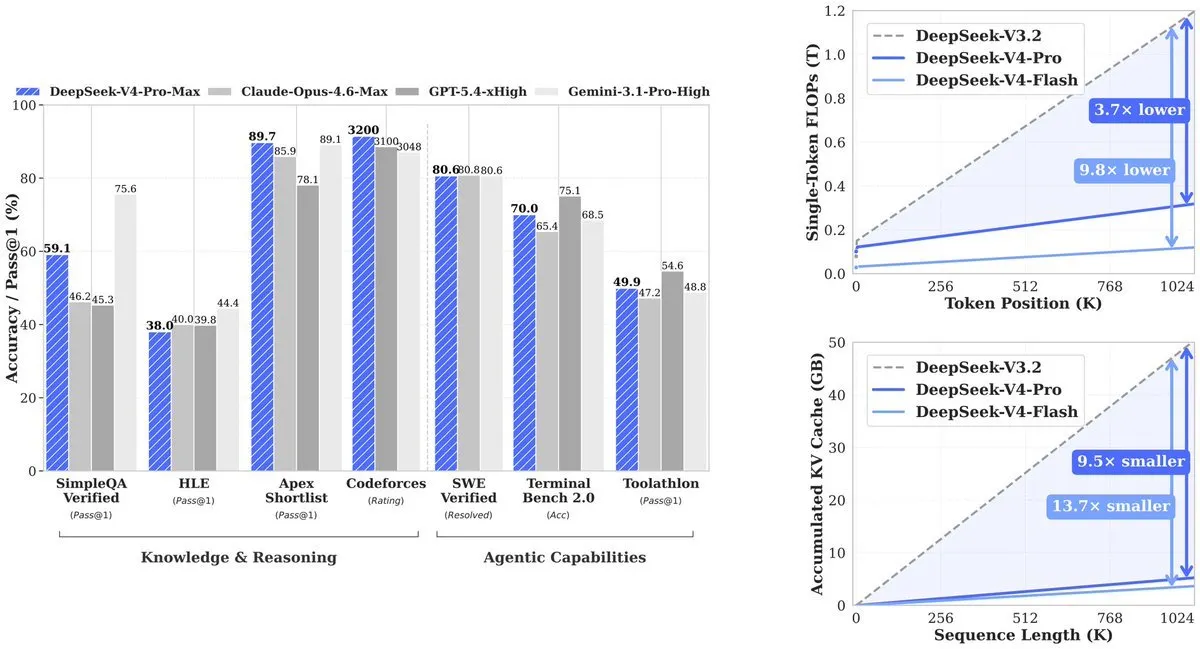
Hasilnya: V4-Pro menggunakan 27% dari komputasi yang dibutuhkan pendahulunya (V3.2). KV cache—memori yang diperlukan untuk melacak konteks—turun menjadi 10% dari V3.2. V4-Flash mendorong efisiensi lebih jauh: 10% komputasi dan 7% memori dibandingkan V3.2.
Kinerja Benchmark dan Posisi Kompetitif
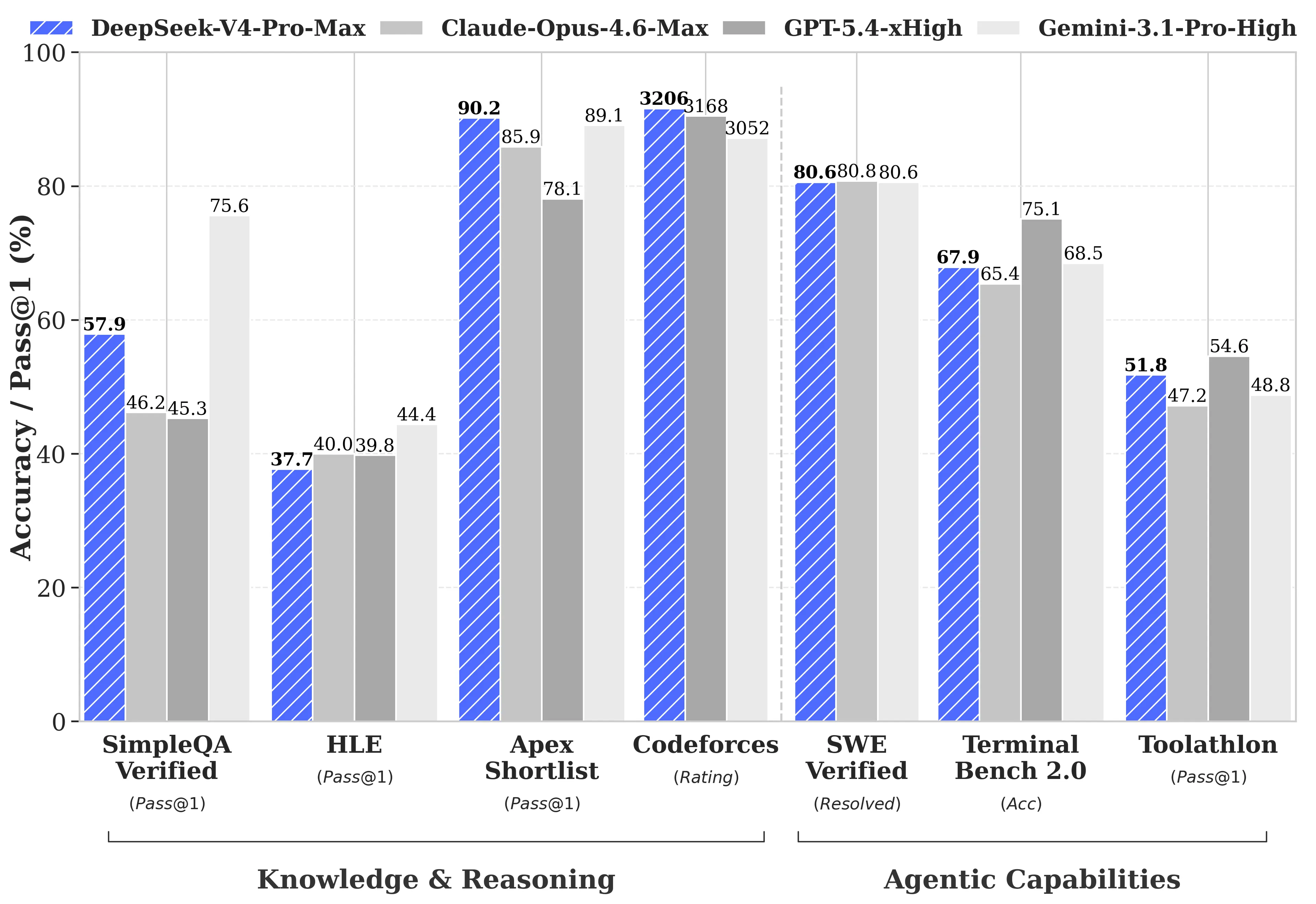
DeepSeek mempublikasikan perbandingan benchmark yang komprehensif melawan GPT-5.4 dan Gemini-3.1-Pro, termasuk area di mana V4-Pro tertinggal dari para pesaing. Pada tugas penalaran, penalaran V4-Pro tertinggal di belakang GPT-5.4 dan Gemini-3.1-Pro sekitar tiga hingga enam bulan, menurut laporan teknis DeepSeek.
Di mana V4-Pro unggul:
- Codeforces (kompetisi pemrograman): V4-Pro mencetak 3,206, menempatkannya sekitar peringkat ke-23 di antara peserta kontes manusia yang benar-benar ikut
- Apex Shortlist (soal matematika dan STEM yang dikurasi): tingkat kelulusan 90.2% dibanding Opus 4.6 sebesar 85.9% dan GPT-5.4 sebesar 78.1%
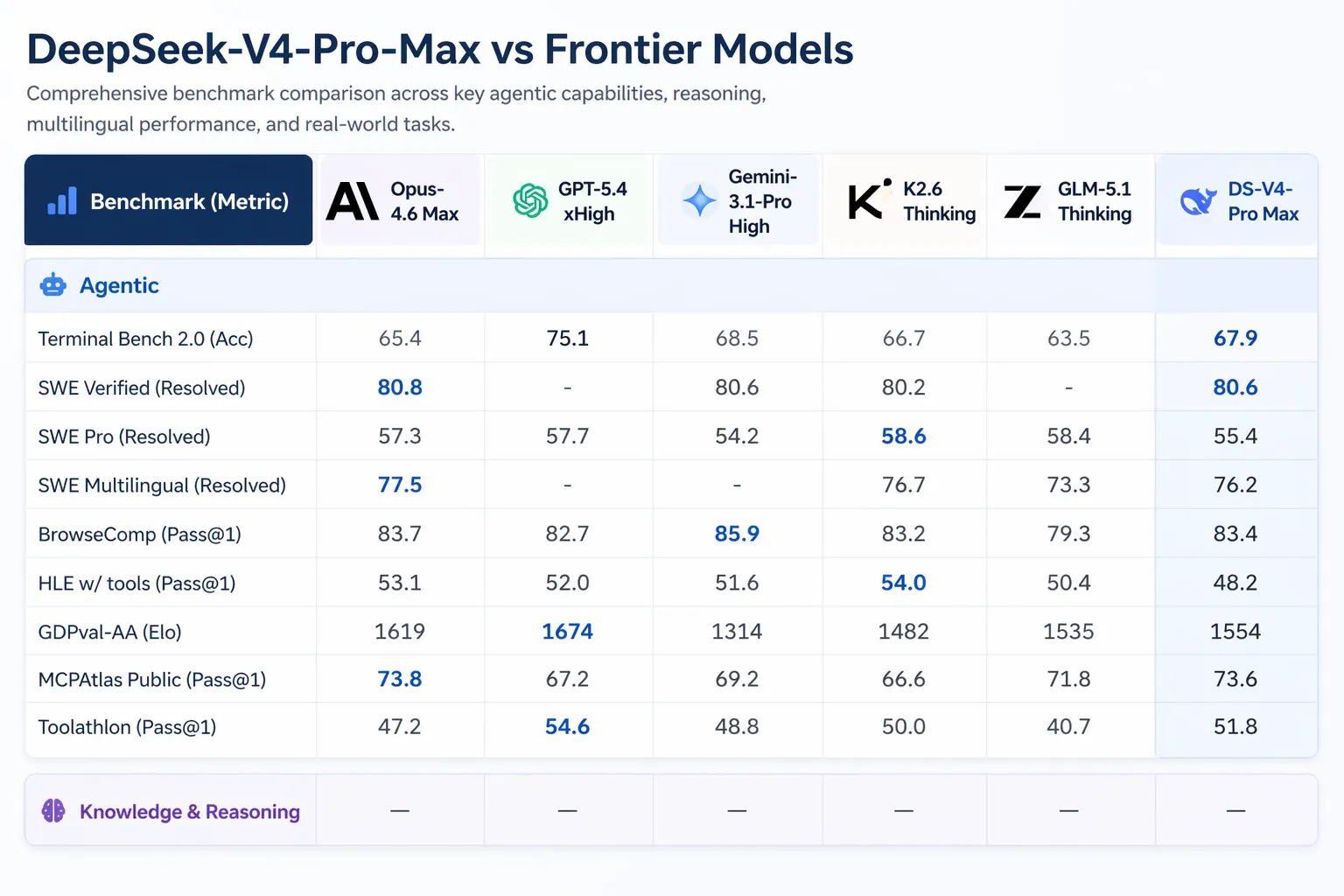
- SWE-Verified (penyelesaian isu GitHub): 80.6%, menyamai Claude Opus 4.6
Di mana V4-Pro tertinggal:
- MMLU-Pro (multitasking): Gemini-3.1-Pro pada 91.0% dibanding V4-Pro pada 87.5%
- GPQA Diamond (pengetahuan ahli): Gemini pada 94.3 dibanding V4-Pro pada 90.1
- Humanity’s Last Exam (tingkat kelulusan): Gemini-3.1-Pro pada 44.4% dibanding V4-Pro pada 37.7%
Pada tugas konteks panjang, V4-Pro memimpin model open-source dan mengalahkan Gemini-3.1-Pro pada CorpusQA (mensimulasikan analisis dokumen dunia nyata pada satu juta token), tetapi kalah dari Claude Opus 4.6 pada MRCR, yang mengukur penelusuran informasi spesifik yang terkubur dalam teks panjang.
Kemampuan Agentic dan Pemrograman
V4-Pro dapat berjalan di Claude Code, OpenCode, dan alat coding AI lainnya. Menurut survei internal DeepSeek terhadap 85 pengembang yang menggunakan V4-Pro sebagai agen coding utama mereka, 52% mengatakan model itu siap menjadi model default mereka, 39% condong menjawab ya, dan kurang dari 9% mengatakan tidak. Pengujian internal DeepSeek menunjukkan V4-Pro mengungguli Claude Sonnet dan mendekati Claude Opus 4.5 pada tugas coding agentic.
Artificial Analysis menempatkan V4-Pro pertama di antara semua model open-weight pada GDPval-AA, sebuah benchmark yang menguji pekerjaan pengetahuan bernilai ekonomi di bidang keuangan, hukum, dan riset. V4-Pro-Max mencetak 1,554 Elo, mengungguli GLM-5.1 (1,535) dan M2.7 MiniMax (1,514). Claude Opus 4.6 mencetak 1,619 pada benchmark yang sama.
V4 memperkenalkan “interleaved thinking”, yang mempertahankan seluruh rangkaian pemikiran (chain of thought) di seluruh panggilan alat. Pada model sebelumnya, ketika agen melakukan beberapa panggilan alat—misalnya, mencari di web, menjalankan kode, lalu mencari lagi—konteks penalaran model dibersihkan di antara putaran. V4 menjaga kontinuitas penalaran lintas langkah, mencegah hilangnya konteks dalam workflow otomatis yang kompleks.
Lanskap Kompetitif dan Konteks Penetapan Harga
Rilis V4 hadir di tengah aktivitas signifikan di ranah AI. Anthropic mengirimkan Claude Opus 4.7 pada 16 April 2026. OpenAI meluncurkan GPT-5.5 pada 23 April 2026, dengan GPT-5.5 Pro berharga $30 per satu juta token input dan $180 per satu juta token output. GPT-5.5 mengalahkan V4-Pro pada Terminal Bench 2.0 (82.7% versus 70.0%), yang menguji workflow agen perintah baris yang kompleks.
Xiaomi merilis MiMo V2.5 Pro pada 22 April 2026, menawarkan kemampuan multimodal penuh (image, audio, video) dengan $1 input dan $3 output per satu juta token. Tencent merilis Hy3 pada hari yang sama dengan GPT-5.5.
Untuk perspektif harga: CEO Cline Saoud Rizwan mencatat bahwa jika Uber menggunakan DeepSeek alih-alih Claude, anggaran AI 2026—yang dilaporkan cukup untuk empat bulan penggunaan—akan bertahan selama tujuh tahun.
Penyebaran dan Ketersediaan
Baik V4-Pro maupun V4-Flash berlisensi MIT dan tersedia di Hugging Face. Model-model ini untuk saat ini hanya teks; DeepSeek menyatakan pihaknya sedang mengerjakan kemampuan multimodal. Kedua model dapat dijalankan secara gratis di perangkat keras lokal atau disesuaikan berdasarkan kebutuhan perusahaan.
Endpoint yang sudah ada dari DeepSeek, deepseek-chat dan deepseek-reasoner, sudah merutekan ke V4-Flash masing-masing pada mode non-thinking dan thinking. Endpoint lama deepseek-chat dan deepseek-reasoner akan dihentikan pada 24 Juli 2026.
DeepSeek melatih V4 sebagian dengan chip Huawei Ascend, menghindari pembatasan ekspor AS. Perusahaan menyatakan bahwa setelah 950 supernode baru datang online pada akhir 2026, harga model Pro yang sudah rendah akan turun lebih lanjut.
Implikasi Praktis
Untuk perusahaan, struktur penetapan harga dapat menggeser perhitungan cost-benefit. Sebuah model yang memimpin benchmark open-source dengan harga $1.74 per satu juta token input membuat pemrosesan dokumen skala besar, peninjauan hukum, dan pipeline generasi kode jauh lebih murah dibanding enam bulan sebelumnya. Konteks satu juta token memungkinkan seluruh basis kode atau berkas pengajuan regulasi diproses dalam satu permintaan, bukan dipecah menjadi beberapa panggilan.
Untuk pengembang dan pembangun independen, V4-Flash menjadi pertimbangan utama. Dengan biaya $0.14 untuk input dan $0.28 untuk output per satu juta token, ia lebih murah dibanding model yang dianggap opsi budget setahun lalu sambil menangani sebagian besar tugas yang mampu dilakukan oleh versi Pro.