ローンチパッド
CandyDrop
キャンディーを集めてAirDropを獲得
Launchpool
クイックステーキング
潜在的な新しいトークンを獲得しよう
HODLer Airdrop
GTを保有して、大量のAirDropを無料で入手
Launchpad
次の大きなトークンプロジェクトを一足先に
Alphaポイント
オンチェーン資産を取引して、Airdrop報酬を楽しもう!
先物ポイント
先物ポイントを獲得し、Airdrop報酬を受け取りましょう。
出典: 新志源
 画像ソース: Unbounded AI によって生成
画像ソース: Unbounded AI によって生成
現在、GPT-4 や PaLM などの巨大なニューラル ネットワーク モデルが登場し、驚くべき少数サンプル学習機能を実証しています。
簡単なプロンプトが与えられると、テキストについて推論したり、物語を書いたり、質問に答えたり、プログラムしたりすることができます…
ただし、LLM は、複雑で複数のステップからなる推論タスクで人間に負けることが多く、無駄に苦労します。
これに関して、中国科学院とイェール大学の研究者らは、「類推的思考」を通じてLLMの推論を強化できる「思考伝播」の新しいフレームワークを提案した。
 用紙のアドレス:
用紙のアドレス:
「思考の拡散」は人間の認知に触発されており、新しい問題に遭遇したとき、戦略を導き出すためにすでに解決した類似の問題と比較することがよくあります。
したがって、この方法の核心は、入力問題を解決する前に、入力に関連する「類似の」問題を LLM に探索させることです。
最後に、同社のソリューションはそのまま使用したり、有益な計画のための洞察を抽出したりできます。
「思考コミュニケーション」が LLM の論理機能の固有の限界に対する新しいアイデアを提案し、大規模なモデルが人間と同じように「類推」を使用して問題を解決できるようにすることは予見できます。

LLM がプロンプトに基づく基本的な推論に優れていることは明らかですが、最適化や計画などの複雑な複数ステップの問題を扱う場合には依然として困難が伴います。
一方、人間は、同様の経験からの直観を利用して、新しい問題を解決します。
大規模モデルには固有の制限があるため、これを行うことはできません。
LLM の知識は完全にトレーニング データのパターンから得られるため、言語や概念を真に理解することはできません。したがって、統計モデルとしては、複雑な組み合わせによる一般化を実行することが困難です。
 最も重要なことは、LLM には体系的な推論能力が欠けており、人間のように段階的に推論して困難な問題を解決することができないということです。
最も重要なことは、LLM には体系的な推論能力が欠けており、人間のように段階的に推論して困難な問題を解決することができないということです。
さらに、大規模モデルの推論は局所的で「近視眼的」であるため、LLM が最適な解決策を見つけて、長期にわたって推論の一貫性を維持することは困難です。
つまり、数学的証明、戦略計画、論理的推論における大規模モデルの欠点は、主に次の 2 つの中心的な問題に起因しています。
**- 以前の経験からの洞察を再利用できない。 **
人間は、新たな問題の解決に役立つ再利用可能な知識と直感を実践から蓄積します。対照的に、LLM は各問題に「ゼロから」アプローチし、以前のソリューションを借用しません。
**- 複数ステップの推論における複合エラー。 **
人間は自分自身の推論の連鎖を監視し、必要に応じて最初のステップを変更します。しかし、推論の初期段階で LLM が犯す間違いは、その後の推論を間違った道に導くため、増幅されます。
上記の弱点は、全体的な最適化や長期計画を必要とする複雑な課題に対処する際の LLM の適用を大きく妨げます。
この点に関して、研究者たちはまったく新しいソリューション思考のコミュニケーションを提案しました。
類推的な思考を通じて、LLM はより人間らしく推論することができます。
研究者らによると、ゼロから推論する場合、同様の問題を解決して得られた洞察を再利用することができず、中間の推論段階でエラーが蓄積されてしまいます。
「思考拡散」では、入力問題に関連する同様の問題を調査し、同様の問題の解決策からインスピレーションを得ることができます。
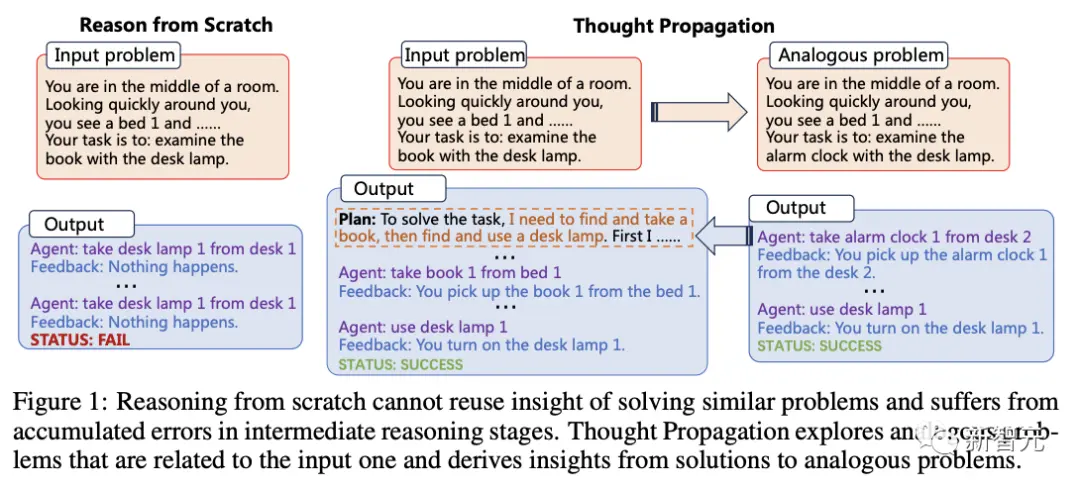 下図は「Thought Propagation (TP)」と他の代表的な技術の比較を示したもので、入力問題pに対してIO、CoT、ToTがゼロから推論して解sを導き出します。
下図は「Thought Propagation (TP)」と他の代表的な技術の比較を示したもので、入力問題pに対してIO、CoT、ToTがゼロから推論して解sを導き出します。
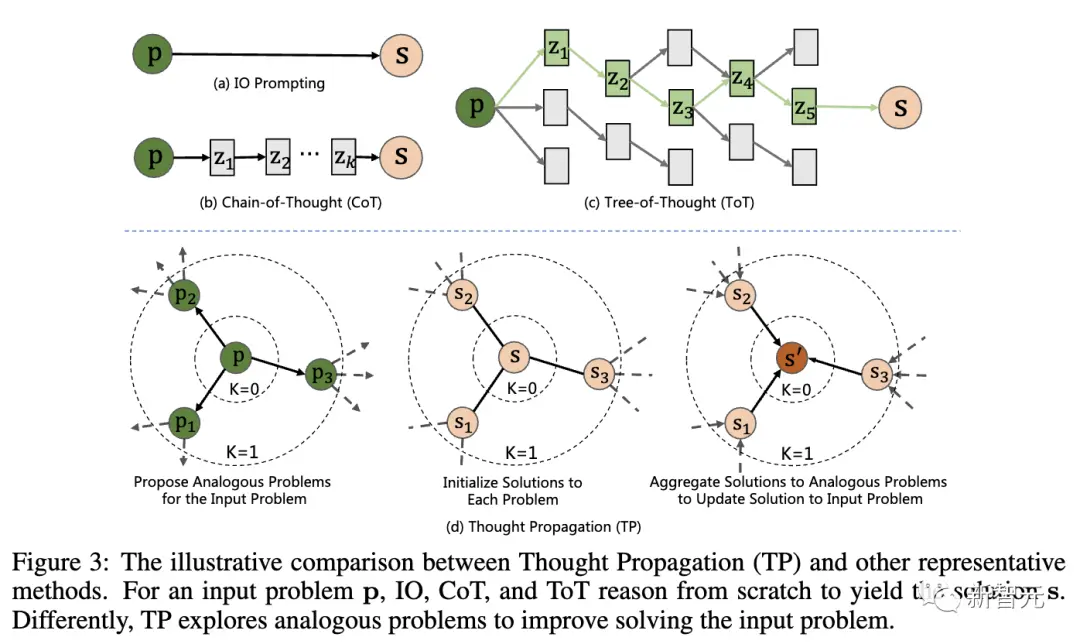 具体的には、TP には 3 つの段階が含まれます。
具体的には、TP には 3 つの段階が含まれます。
**1. 同様の質問をする: **LLM は、プロンプトを通じて入力された質問と類似した一連の類似した質問を生成します。これにより、モデルが関連する可能性のある過去の経験を取得できるようになります。
**2. 類似の問題を解決する: ** LLM に、CoT などの既存のプロンプト テクノロジを通じて類似の問題をそれぞれ解決させます。
**3. 解決策の要約: ** 2 つの異なるアプローチがあります - 類似の解決策に基づいて入力問題に対する新しい解決策を直接推論する方法と、類似の解決策を入力問題と比較することによって高レベルの計画または戦略を導き出す方法です。
これにより、大規模なモデルで以前の経験とヒューリスティックを再利用でき、また、最初の推論を類推的なソリューションとクロスチェックして、それらのソリューションを改良することができます。
「思考の伝播」はモデルとは何の関係もなく、任意のプロンプト手法に基づいて単一の問題解決ステップを実行できることは言及する価値があります。
この方法の重要な新しさは、LLM の類推的思考を刺激して、複雑な推論プロセスを導くことです。
「考えるコミュニケーション」がLLMをより人間らしくできるかどうかは、その成果にかかっています。
中国科学院とイェール大学の研究者は、次の 3 つのタスクで評価を実施しました。
**- 最短パスの推論: **グラフ内のノード間の最適なパスを見つけるには、グローバルな計画と検索が必要です。単純なグラフであっても、標準的な手法は失敗します。
**- クリエイティブ ライティング: ** 一貫したクリエイティブなストーリーを作成することは、終わりのない課題です。高レベルのアウトライン プロンプトが与えられると、LLM は一貫性やロジックを失うことがよくあります。
- LLM エージェントの計画: テキスト環境と対話する LLM エージェントは、長期的な戦略に苦労していました。彼らの計画はしばしば「逸脱」したり、サイクルに陥ったりします。
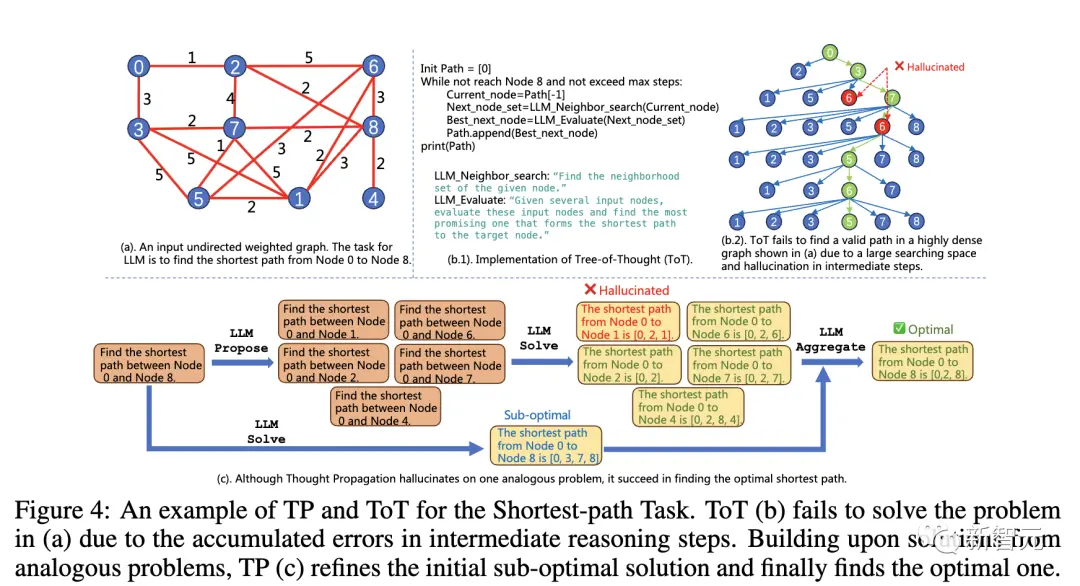
最短経路推論タスクでは、既存の方法で遭遇する問題は解決できません。
(a) のグラフは非常に単純ですが、推論は 0 から始まるため、これらの方法では、LLM が次善の解決策 (b、c) を見つけるか、中間ノード (d) を繰り返し訪問することしかできません。
 以下は TP と ToT を組み合わせた例です。
以下は TP と ToT を組み合わせた例です。
ToT (b) は、中間の推論ステップでのエラーの蓄積により、(a) の問題を解くことができません。同様の問題の解決策に基づいて、TP © は最初の次善の解決策を改良し、最終的に最適な解決策を見つけます。
 ベースラインと比較すると、最短パス タスクを処理する TP のパフォーマンスが 12% 大幅に向上し、最適かつ効果的な最短パスが生成されます。
ベースラインと比較すると、最短パス タスクを処理する TP のパフォーマンスが 12% 大幅に向上し、最適かつ効果的な最短パスが生成されます。
さらに、OLR が最も低いため、TP によって生成された有効パスは、ベースラインと比較して最適パスに最も近くなります。
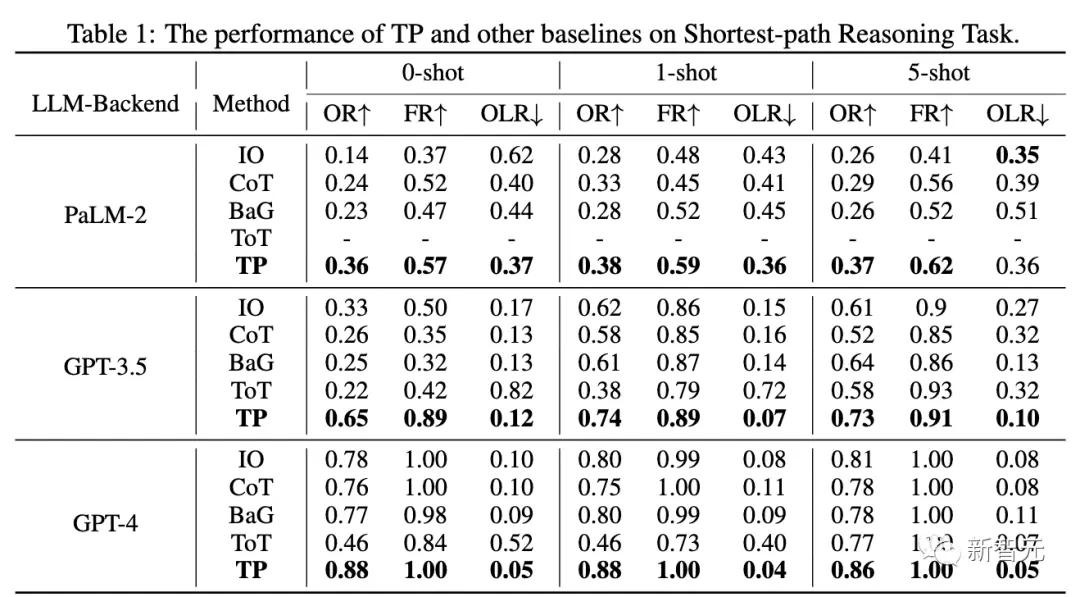 同時に、研究者らは、最短パス タスクの複雑さとパフォーマンスに対する TP 層の数の影響をさらに研究しました。
同時に、研究者らは、最短パス タスクの複雑さとパフォーマンスに対する TP 層の数の影響をさらに研究しました。
異なる設定では、レイヤー 1 TP のトークン コストは ToT と同様になります。ただし、レイヤー 1 TP は、最適な最短パスを見つけるという点で非常に競争力のあるパフォーマンスを達成しています。
さらに、レイヤー 1 TP のパフォーマンス向上もレイヤー 0 TP (IO) と比較して非常に大幅です。図 5(a) は、レイヤー 2 TP のトークン コストの増加を示しています。
## 文芸
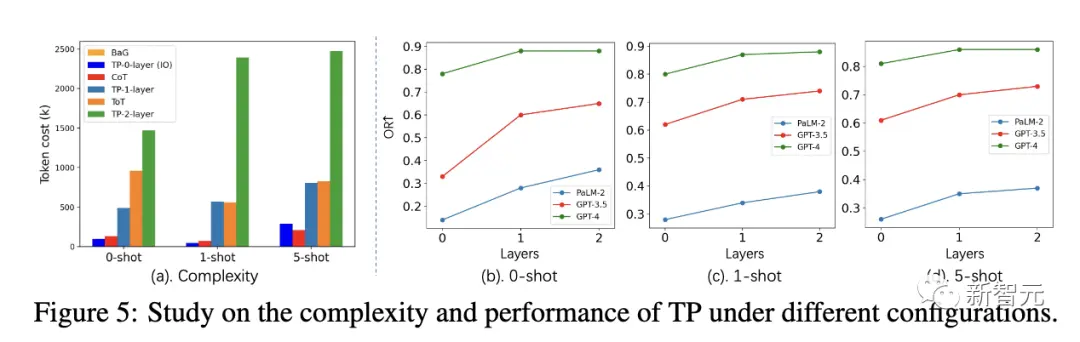
以下の表 2 は、GPT-3.5 および GPT-4 の TP とベースラインのパフォーマンスを示しています。一貫性の点では、TP はベースラインを上回っています。さらに、ユーザー調査では、TP により人間の創造的な文章の好みが 13% 増加しました。
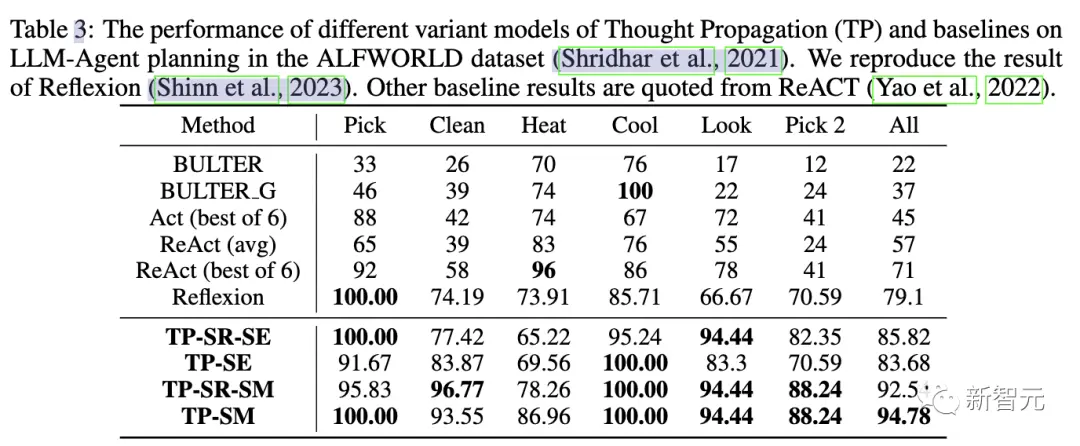
3 番目のタスク評価では、研究者らは ALFWorld ゲーム スイートを使用して、134 の環境で LLM エージェント計画タスクをインスタンス化しました。
TP は、LLM エージェント計画におけるタスク完了率を 15% 増加させます。これは、同様のタスクを完了するときに計画を成功させるための反射型 TP の優位性を示しています。
 上記の実験結果は、「思考の伝播」がさまざまな推論タスクに一般化でき、これらすべてのタスクで良好に機能することを示しています。
上記の実験結果は、「思考の伝播」がさまざまな推論タスクに一般化でき、これらすべてのタスクで良好に機能することを示しています。
強化された LLM 推論の鍵
「思考伝播」モデルは、複雑な LLM 推論のための新しいテクノロジーを提供します。
類推的思考は人間の問題解決能力の特徴であり、より効率的な検索やエラー修正など、さまざまなシステム上の利点につながる可能性があります。
同様に、LLM は、再利用可能な知識の欠如や局所的なエラーの連鎖など、LLM 自体の弱点を、類推的な思考を促すことでより適切に克服できます。
ただし、これらの発見にはいくつかの制限があります。
有用な類推質問を効率的に生成することは容易ではなく、類推パスの長いチェーンは扱いにくくなる可能性があります。同時に、複数段階の推論チェーンを制御および調整することは依然として困難です。
しかし、「思考の伝播」は、LLM の推論上の欠陥を創造的に解決することにより、依然として興味深い方法を提供します。
さらなる発展により、類推的思考により LLM の推論がさらに強力になる可能性があります。そしてこれは、大規模な言語モデルでより人間らしい推論を実現する方法も示しています。
## 著者について
 彼は、中国科学院オートメーション研究所および中国科学院大学のパターン認識国家実験重点実験室の教授であり、IAPR フェローであり、IEEE の上級メンバーでもあります。
彼は、中国科学院オートメーション研究所および中国科学院大学のパターン認識国家実験重点実験室の教授であり、IAPR フェローであり、IEEE の上級メンバーでもあります。
以前は大連理工大学で学士号と修士号を取得し、2009 年に中国科学院オートメーション研究所で博士号を取得しました。
彼の研究対象は、生体認証アルゴリズム (顔認識と合成、虹彩認識、人物の再識別)、表現学習 (弱い学習/自己教師あり学習または転移学習を使用した事前学習ネットワーク)、生成学習 (生成モデル、画像生成、画像翻訳) です。 )。
IEEE TPAMI、IEEE TIP、IEEE TIFS、IEEE TNN、IEEE TCSVT などの有名な国際ジャーナルや、CVPR、ICCV、ECCV、 NeurIPS。
彼は IEEE TIP、IEEE TBIOM、および Pattern Recognition の編集委員会のメンバーであり、CVPR、ECCV、NeurIPS、ICML、ICPR、IJCAI などの国際会議の地域議長を務めてきました。
 Yu Junchi は中国科学院オートメーション研究所の博士課程 4 年生で、指導教官は Heran 教授です。
Yu Junchi は中国科学院オートメーション研究所の博士課程 4 年生で、指導教官は Heran 教授です。
以前は Tencent 人工知能研究所でインターンをし、Tingyang Xu 博士、Yu Rong 博士、Yatao Bian 博士、Junzhou Huang 教授と一緒に働いていました。現在、イェール大学コンピューターサイエンス学部の交換留学生として、レックス・イン教授に師事しています。
彼の目標は、優れた解釈性と移植性を備えた Trustworthy Graph Learning (TwGL) メソッドを開発し、生化学におけるその応用を探ることです。
参考文献: