CoinWorldKing
現在、コンテンツはありません
CoinWorldKing
Good projects will help you get through the bear market!
It's been a while since I've been hit with airdrops. The Bitcoin staking project I locked in half a year ago finally unlocked today!
This month's living expenses are covered! Thanks @Lombard_Finance
I really miss those days of easy rewards. Relying on TermMax this year 🥺
It's been a while since I've been hit with airdrops. The Bitcoin staking project I locked in half a year ago finally unlocked today!
This month's living expenses are covered! Thanks @Lombard_Finance
I really miss those days of easy rewards. Relying on TermMax this year 🥺
BTC-2.11%
- 報酬
- 1
- コメント
- リポスト
- 共有
何のレポートがマスクさえも信じられないほどの衝撃を与えたのか?
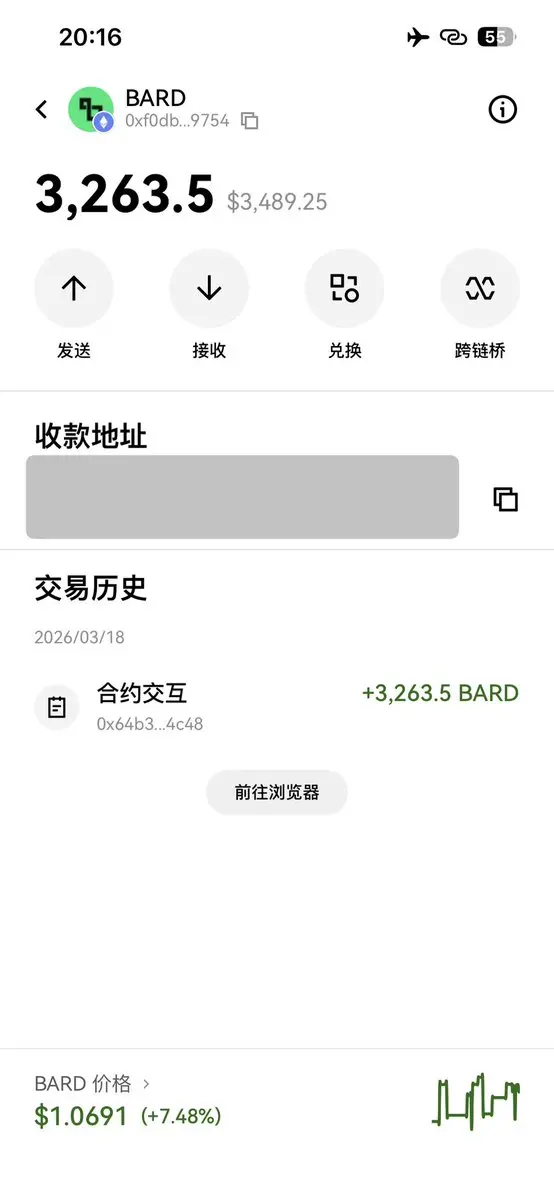
Moonshot AI(Kimiチーム)が最近発表した爆発的な技術レポート:《Attention Residuals》は、Transformerでほぼ10年使われてきた残差結合(Residual Connections)をアップグレードしたものです。その結果、Elon Muskまでもがコメントせざるを得なくなり、信じられないほどの衝撃を受けたと感じました。
このレポートの核心は一言で要約できます:
「もう各層が前のすべての情報を等しい重みでただ単に足し合わせるのはやめて、モデル自身に注意機構を学習させて、どの初期層の信号が本当に有用かを選ばせよう!」
従来のTransformer(PreNorm構造)では、各層の出力は次のようになっています:
x_{l} = x_{l-1} + sublayer(x_{l-1} / √something)
これはシンプルで乱暴なやり方で、前の100層の情報が有用かどうかに関わらず、すべてを一気に加算します。層が深くなるほど、初期の重要な信号は後の無数の層によって希釈されてほとんど見えなくなります(これをPreNorm dilutionまたは表現の希釈と呼びます)。
Kimiチームはこの「+」記号を、軽量なクロス層注意(depth-wise attention)に置き換えました。
新しい
原文表示Moonshot AI(Kimiチーム)が最近発表した爆発的な技術レポート:《Attention Residuals》は、Transformerでほぼ10年使われてきた残差結合(Residual Connections)をアップグレードしたものです。その結果、Elon Muskまでもがコメントせざるを得なくなり、信じられないほどの衝撃を受けたと感じました。
このレポートの核心は一言で要約できます:
「もう各層が前のすべての情報を等しい重みでただ単に足し合わせるのはやめて、モデル自身に注意機構を学習させて、どの初期層の信号が本当に有用かを選ばせよう!」
従来のTransformer(PreNorm構造)では、各層の出力は次のようになっています:
x_{l} = x_{l-1} + sublayer(x_{l-1} / √something)
これはシンプルで乱暴なやり方で、前の100層の情報が有用かどうかに関わらず、すべてを一気に加算します。層が深くなるほど、初期の重要な信号は後の無数の層によって希釈されてほとんど見えなくなります(これをPreNorm dilutionまたは表現の希釈と呼びます)。
Kimiチームはこの「+」記号を、軽量なクロス層注意(depth-wise attention)に置き換えました。
新しい
- 報酬
- 2
- コメント
- リポスト
- 共有
昨晩のアカデミー賞の見どころ~ Conan O’Brienが司会を務め、レッドカーペットから授賞式までハイテンションでお届け!
1. レッドカーペットの女王 Anne Hathaway
黒のValentino花柄ロングドレスに長手袋、ダイヤモンドのネックレスで、優雅さとセクシーさを兼ね備えたスタイル!
2. 『Sinners』大ヒット
Ryan Cooglerが最優秀オリジナル脚本賞を受賞!ステージで感動のスピーチを披露し、オークランド出身者の誇りが爆発。映画パフォーマンス「I Lied To You」では会場全体がスタンディングオベーション!
3. アニメのダークホース『KPop Demon Hunters』
最優秀長編アニメ賞を獲得!KPOPと悪魔ハンターの設定が超トレンディ!
4. 面白シーン
Groguは拍手できず、Sigourney WeaverとKate HudsonがBaby Yodaを奪い合い、Timothée Chalametが「階段から落ちる」シーンがSNSで拡散😂
5. 歴史的瞬間
複数の新人や少数民族が記録を打ち立て、2026年のアカデミー賞は本当に多様性に富んでいた!
原文表示1. レッドカーペットの女王 Anne Hathaway
黒のValentino花柄ロングドレスに長手袋、ダイヤモンドのネックレスで、優雅さとセクシーさを兼ね備えたスタイル!
2. 『Sinners』大ヒット
Ryan Cooglerが最優秀オリジナル脚本賞を受賞!ステージで感動のスピーチを披露し、オークランド出身者の誇りが爆発。映画パフォーマンス「I Lied To You」では会場全体がスタンディングオベーション!
3. アニメのダークホース『KPop Demon Hunters』
最優秀長編アニメ賞を獲得!KPOPと悪魔ハンターの設定が超トレンディ!
4. 面白シーン
Groguは拍手できず、Sigourney WeaverとKate HudsonがBaby Yodaを奪い合い、Timothée Chalametが「階段から落ちる」シーンがSNSで拡散😂
5. 歴史的瞬間
複数の新人や少数民族が記録を打ち立て、2026年のアカデミー賞は本当に多様性に富んでいた!




- 報酬
- いいね
- コメント
- リポスト
- 共有
ありがとう @BitMart_zh のグッズ、8周年おめでとう 🎉
8年は簡単ではありません、引き続き大きく強くしていきましょう!
原文表示8年は簡単ではありません、引き続き大きく強くしていきましょう!

- 報酬
- いいね
- コメント
- リポスト
- 共有
0からトレーディングエンジン、EVM、Transformer(47万スター)を作る
最近Githubのトレンドを見ていて、このリポジトリに完全に目覚めさせられました。ぜひ保存してください:
中身はすべてハードコアなチュートリアルで、ゼロから自分で手を動かして以下を作り出せます:
• ブロックチェーン/Web3:Bitcoin、Ethereum、Merkle Tree、コンセンサス、EVMを作成 → MEVボットやインデクサを直接書くために
• データベース:Redis、SQLite、KVストレージを作成 → Redisがなぜ高速なのか理解でき、LSM/B+木/WALの仕組みも完全理解
• AI:ニューラルネットワーク、Transformer、ミニLLMを作成 →逆伝播、アテンション、トークナイザーを自分で書きながら学ぶ
• コンテナ:Dockerを作成 → cgroup、namespace、overlayfsの仕組みを一瞬で理解
• その他:Git、トレーディングオーダーブック、検索エンジンの作成も含む
原文表示最近Githubのトレンドを見ていて、このリポジトリに完全に目覚めさせられました。ぜひ保存してください:
中身はすべてハードコアなチュートリアルで、ゼロから自分で手を動かして以下を作り出せます:
• ブロックチェーン/Web3:Bitcoin、Ethereum、Merkle Tree、コンセンサス、EVMを作成 → MEVボットやインデクサを直接書くために
• データベース:Redis、SQLite、KVストレージを作成 → Redisがなぜ高速なのか理解でき、LSM/B+木/WALの仕組みも完全理解
• AI:ニューラルネットワーク、Transformer、ミニLLMを作成 →逆伝播、アテンション、トークナイザーを自分で書きながら学ぶ
• コンテナ:Dockerを作成 → cgroup、namespace、overlayfsの仕組みを一瞬で理解
• その他:Git、トレーディングオーダーブック、検索エンジンの作成も含む
- 報酬
- いいね
- コメント
- リポスト
- 共有
徹底的に狂っている!ロブスターが深センを席巻!
深センの数百人が一斉に小さなロブスターに変身!
小さなロブスターたちの後のシェアを待ちきれない!
原文表示深センの数百人が一斉に小さなロブスターに変身!
小さなロブスターたちの後のシェアを待ちきれない!

- 報酬
- 1
- コメント
- リポスト
- 共有
戦争が勃発した後、世界は突然このデジタル身分証明書だけが命を救うことに気づいた?
Signを覚えていますか?Signチームは身近なシナリオをデモンストレーションしました:
「コーネル大学の卒業生がスマホのウォレットを開き、軽くタップするだけで、採用担当者に自分の学士号と4.0 GPAを証明。第三者のデータベース検索も、データのコピーも、痕跡も残さない。発行者は一度だけ署名し、所有者が自己管理、検証者はローカルで署名を検証するだけ」
これがSignのVerifiable Credential(VC)です!現在、世界で最も先進的で、主権レベルの実用化が進むデジタル証明書システム。
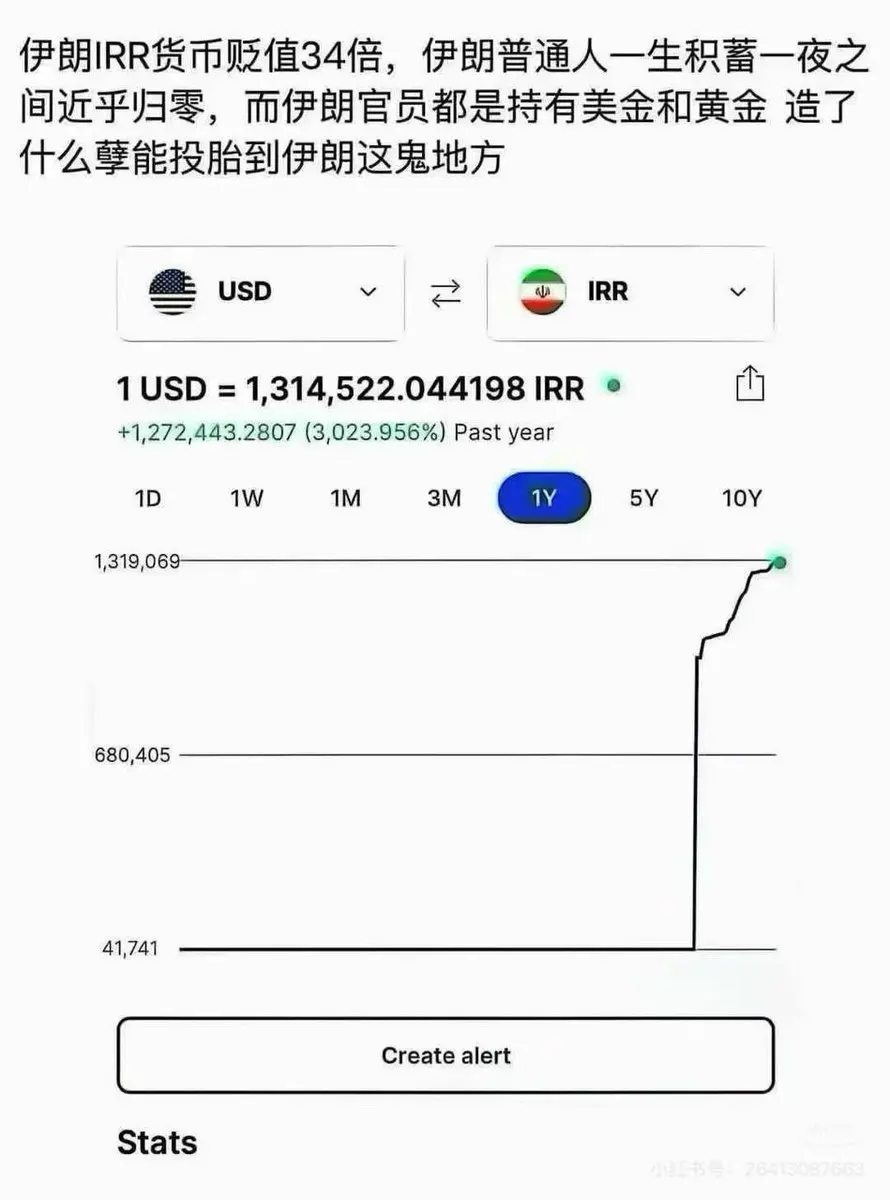
特に今、世界の情勢が不安定で、通貨が激しく変動している時に。イランを例に取ると:為替レートが一日で数十ポイント急落し、リアルは直接150万と1ドルに崩壊。そんな中、Sign VCはこの状況を直接逆転させることができます:
> プライバシーは本当に自己管理、選択的に開示
> オフラインでも継続、戦争や制裁が来ても一クリックで証明!
> 国家レベルの経済連続性、中央銀行がCBDCを発行する際、VCはお金と身分を結びつける究極の鍵、ブロックチェーン上で継続して動作
Signはすでにいくつかの国で導入されています。その中にはキルギス全国、シエラレオネ、アラブ首長国連邦アブダビも含まれます!乱世の中で、これをやりましょ
原文表示Signを覚えていますか?Signチームは身近なシナリオをデモンストレーションしました:
「コーネル大学の卒業生がスマホのウォレットを開き、軽くタップするだけで、採用担当者に自分の学士号と4.0 GPAを証明。第三者のデータベース検索も、データのコピーも、痕跡も残さない。発行者は一度だけ署名し、所有者が自己管理、検証者はローカルで署名を検証するだけ」
これがSignのVerifiable Credential(VC)です!現在、世界で最も先進的で、主権レベルの実用化が進むデジタル証明書システム。
特に今、世界の情勢が不安定で、通貨が激しく変動している時に。イランを例に取ると:為替レートが一日で数十ポイント急落し、リアルは直接150万と1ドルに崩壊。そんな中、Sign VCはこの状況を直接逆転させることができます:
> プライバシーは本当に自己管理、選択的に開示
> オフラインでも継続、戦争や制裁が来ても一クリックで証明!
> 国家レベルの経済連続性、中央銀行がCBDCを発行する際、VCはお金と身分を結びつける究極の鍵、ブロックチェーン上で継続して動作
Signはすでにいくつかの国で導入されています。その中にはキルギス全国、シエラレオネ、アラブ首長国連邦アブダビも含まれます!乱世の中で、これをやりましょ
- 報酬
- いいね
- コメント
- リポスト
- 共有
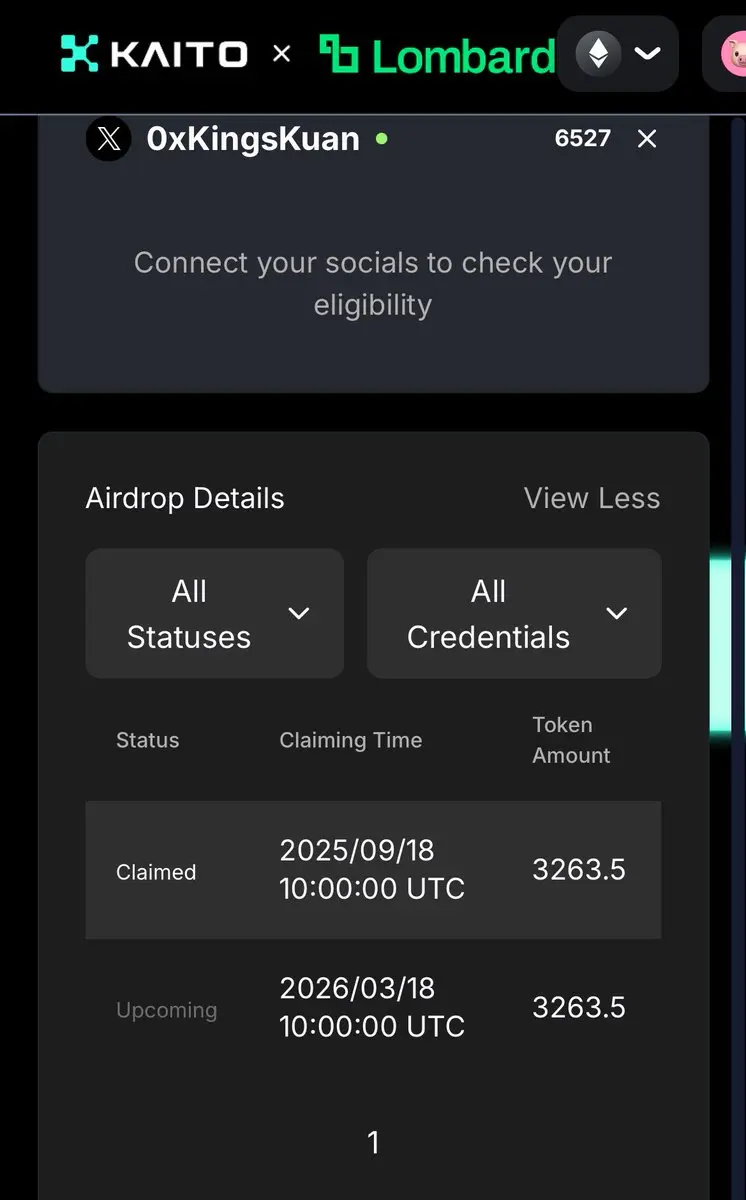
ロムバード、もう少し頑張って!
以前やりまくったビットコインのステーキングプロジェクト、ロムバードがまもなくロック解除されるから、なんとか落ち着いてほしい🥺
あの頃の熱中していた日々が懐かしい😭
以前やりまくったビットコインのステーキングプロジェクト、ロムバードがまもなくロック解除されるから、なんとか落ち着いてほしい🥺
あの頃の熱中していた日々が懐かしい😭
BTC-2.11%

- 報酬
- いいね
- コメント
- リポスト
- 共有
以前買加密 token,
現在買 API token 🫠
原文表示現在買 API token 🫠
- 報酬
- いいね
- コメント
- リポスト
- 共有
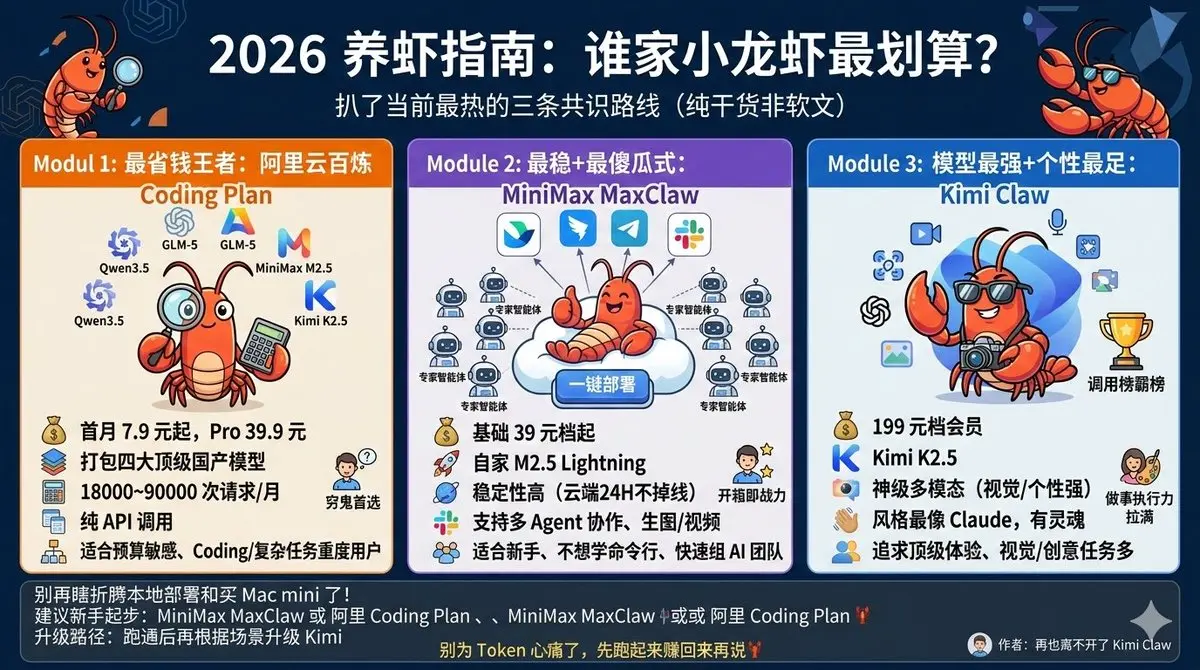
誰の小さなロブスターが最もコスパが良い/最も安定している/モデルが最も優れている?
皆さん、もうローカル展開やMac miniの購入に無駄に手を出すのはやめましょう!
最近のコミュニティ実測、X大Vのフィードバック、呼び出しランキングデータ、各大手メーカーの動きに基づき、現在最もホットな3つの合意ルート(純粋な実用情報の順序、メーカーの宣伝文ではありません)を分析しました:
1/ 最もコスパが良い王者:阿里雲百炼 Coding Plan(初月7.9元から、Pro 39.9元)
なぜ最もコスパが良いのか?
Qwen3.5 + GLM-5 + MiniMax M2.5 + Kimi K2.5の4大トップ国内モデルをパッケージ化し、月間18000〜90000回のリクエストに対応。気軽に使い分け可能。初心者が新鮮さを試すのに、初月7.9元だけで複雑なタスクを実行でき、Kimi 199元やMiniMaxの高額プランよりも圧倒的にお得です。以前は月数百ドルのTokenコストだったのに、これとコスト感知ルーティングを使えば、月コストは数十元にまで削減可能!
> モデルの実力:M2.5 Lightningは高速でほぼ無料レベル、GLM-5は安定(幻覚低)、Kimi K2.5は多モーダルで個性あり、Qwen3.5はプログラミングに強い。総合的に見て、貧乏人に優しい爆速。
> 欠点:純API呼び出しの
原文表示皆さん、もうローカル展開やMac miniの購入に無駄に手を出すのはやめましょう!
最近のコミュニティ実測、X大Vのフィードバック、呼び出しランキングデータ、各大手メーカーの動きに基づき、現在最もホットな3つの合意ルート(純粋な実用情報の順序、メーカーの宣伝文ではありません)を分析しました:
1/ 最もコスパが良い王者:阿里雲百炼 Coding Plan(初月7.9元から、Pro 39.9元)
なぜ最もコスパが良いのか?
Qwen3.5 + GLM-5 + MiniMax M2.5 + Kimi K2.5の4大トップ国内モデルをパッケージ化し、月間18000〜90000回のリクエストに対応。気軽に使い分け可能。初心者が新鮮さを試すのに、初月7.9元だけで複雑なタスクを実行でき、Kimi 199元やMiniMaxの高額プランよりも圧倒的にお得です。以前は月数百ドルのTokenコストだったのに、これとコスト感知ルーティングを使えば、月コストは数十元にまで削減可能!
> モデルの実力:M2.5 Lightningは高速でほぼ無料レベル、GLM-5は安定(幻覚低)、Kimi K2.5は多モーダルで個性あり、Qwen3.5はプログラミングに強い。総合的に見て、貧乏人に優しい爆速。
> 欠点:純API呼び出しの
- 報酬
- 1
- コメント
- リポスト
- 共有
あなたの小さなロブスターが特定されました 🆘
誰かが全ネットをスキャンし、23.49万のロブスターが直接インターネット上で裸で公開されています!デフォルトポート18789、トークン未設定、パスワード未設定、ファイアウォール未導入……
クリックすれば他人のAgentが何をしているか、どのAPIを調整しているか、どのウォレットを保存しているか、どんなコードを書いているかを見ることができます…… まるで家の鍵+銀行カード+コンピュータ管理者権限を玄関に貼り付け、「遊びに来てください」と書いているようなものです😱
これは冗談ではありません:
• APIキーが全漏洩
• ウォレットが乗っ取られる
• サーバーがマルウェアに感染してマイニングやバックドアに利用される
• 企業の秘密が丸見えになる
今最もホットな露出掲示板(他人のを勝手にクリックしないでください):
⚠️⚠️
5分でできる自己救済チェックリスト(コピーして使ってください):
1/ netstat / ss -tuln | grep 18789 → 公開監視されているか確認
2/ すぐに127.0.0.1にバインド変更、または外部アクセスを遮断
3/ Openclawを最新版にアップデート(セキュリティのデフォルト強化)
4/ --tokenを付けて強力なパスワードを設定、ま
原文表示誰かが全ネットをスキャンし、23.49万のロブスターが直接インターネット上で裸で公開されています!デフォルトポート18789、トークン未設定、パスワード未設定、ファイアウォール未導入……
クリックすれば他人のAgentが何をしているか、どのAPIを調整しているか、どのウォレットを保存しているか、どんなコードを書いているかを見ることができます…… まるで家の鍵+銀行カード+コンピュータ管理者権限を玄関に貼り付け、「遊びに来てください」と書いているようなものです😱
これは冗談ではありません:
• APIキーが全漏洩
• ウォレットが乗っ取られる
• サーバーがマルウェアに感染してマイニングやバックドアに利用される
• 企業の秘密が丸見えになる
今最もホットな露出掲示板(他人のを勝手にクリックしないでください):
⚠️⚠️
5分でできる自己救済チェックリスト(コピーして使ってください):
1/ netstat / ss -tuln | grep 18789 → 公開監視されているか確認
2/ すぐに127.0.0.1にバインド変更、または外部アクセスを遮断
3/ Openclawを最新版にアップデート(セキュリティのデフォルト強化)
4/ --tokenを付けて強力なパスワードを設定、ま
- 報酬
- 2
- コメント
- リポスト
- 共有