Introdução: porque a IA está a revalorizar o papel do armazenamento na infraestrutura cripto

Fonte da imagem: Página de mercado da Gate
Até 2026, os preços do armazenamento e do tráfego de saída — tanto em cloud como em soluções auto-hospedadas — continuam a aumentar de forma constante. Com o crescimento explosivo de conjuntos de dados de treino de IA, bases de dados vetoriais e registos de inferência, o "preço unitário por GB" e as "taxas de sincronização entre regiões" voltam a ser destaque nos relatórios semanais de CFO e líderes de infraestrutura. Neste contexto, o sentimento de mercado mostra elevada sensibilidade à "oferta alternativa": ativos de armazenamento descentralizado como STORJ registam aumentos acentuados de curto prazo, transformando rapidamente problemas estruturais em hotspots de negociação. A verdadeira questão não está nas oscilações diárias de preço, mas sim: à medida que as empresas pagam faturas mais elevadas pela retenção de modelos e Agentes a longo prazo, porque é que o mercado ajusta as expectativas para soluções de armazenamento on-chain, verificável ou baseadas em DePIN?
Importa clarificar: "armazenamento" no contexto cripto não representa um único produto. Pode referir-se a arquivamento web permanente e modelos de segurança económica, armazenamento de objetos quase em tempo real e gestão de camadas hot-cold, ou simplesmente a um módulo dentro de uma pilha (em conjunto com mercados de Hashrate e Data Availability, DA). As secções seguintes categorizam projetos e roadmaps por tipo de problema, evitando misturas de diferentes camadas tecnológicas numa narrativa única de "token de armazenamento" e separando a volatilidade de preço de aspetos como disponibilidade, SLA, conformidade e TCO de longo prazo.
Antes de analisar projetos específicos, utilizar a estrutura em camadas abaixo para alinhar áreas de foco.
-
Congelamento de versões para dados de treino e avaliação
- É necessária imutabilidade a longo prazo e auditabilidade pública via cadeia de carimbos temporais?
- Um custo de escrita único mais elevado é aceitável para reduzir riscos de disputas a jusante?
-
Gestão do ciclo de vida para pesos de modelos e resultados intermédios
- O foco está no arquivamento e backup (leituras de baixa frequência) ou no carregamento para inferência online (sensível à latência)?
- É necessário controlo por contrato on-chain para renovações, listas de acesso e liquidação?
-
Estado de Agente e sessão
- É necessária autorização programável (por exemplo, por chamador, tarefa ou janela temporal)?
- Para atualizações de estado de alta frequência, camadas KV ou mutáveis são mais práticas do que blobs puramente permanentes.
-
Aprovisionamento empresarial e conformidade
- Os compradores questionam frequentemente sobre SLA, região, encriptação e Gestão de chaves, formatos de prova verificável e faturação de tráfego de saída.
- Soluções descentralizadas focadas apenas no número de nodos, mas sem SLO mensuráveis, terão dificuldades na adoção empresarial.
Estes quatro aspetos determinam se o foco de avaliação deve incidir em camadas permanentes tipo Arweave, clouds verificáveis estilo Filecoin Onchain Cloud, armazenamento de objetos programável como Walrus/Akave, ou módulos full-stack como 0G, que integra armazenamento numa arquitetura de cadeia nativa para IA.
Comparação de rotas técnicas: posse verificável, armazenamento permanente, compatibilidade de objetos e DePIN full-stack
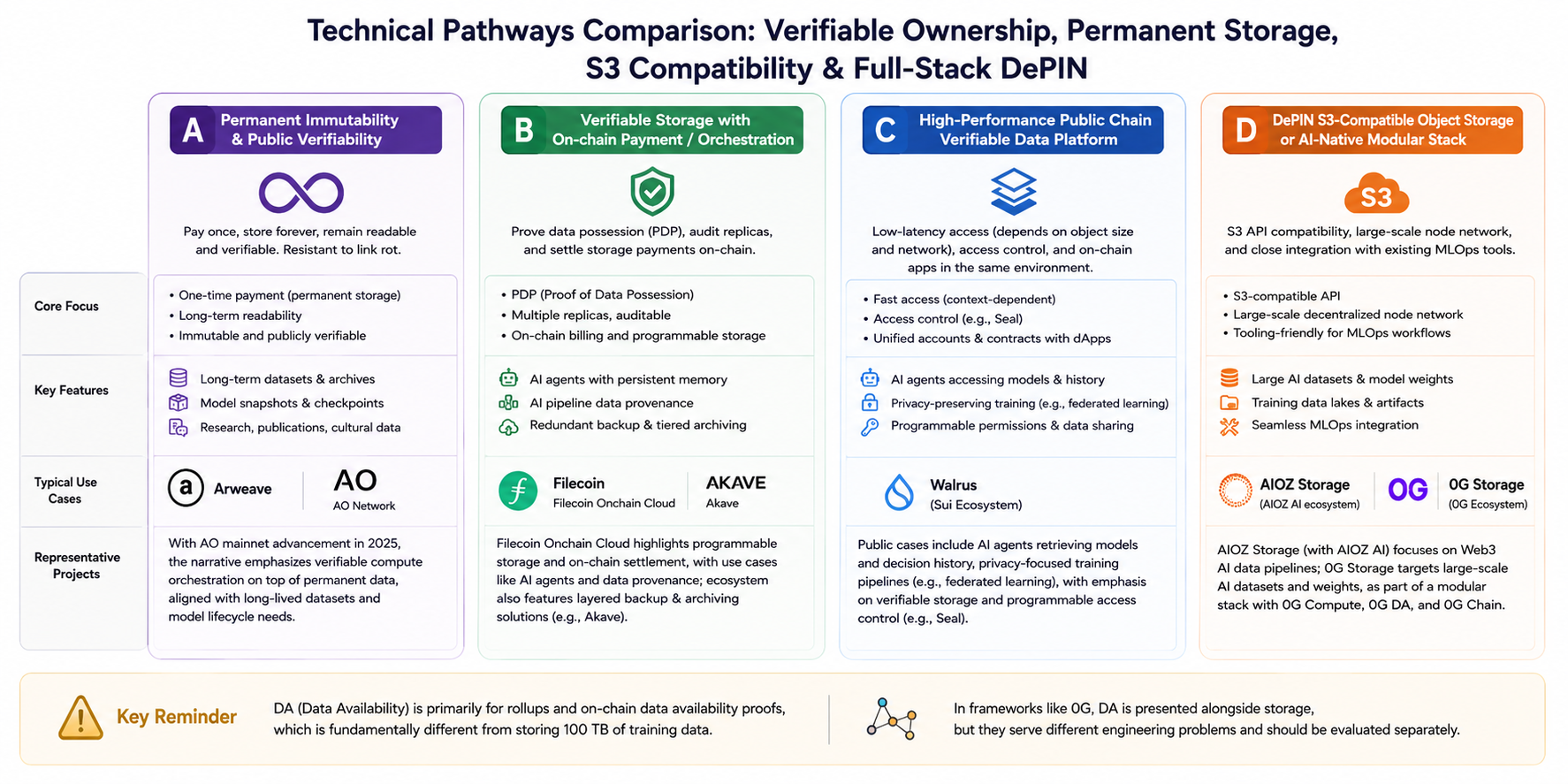
Para comparação lado a lado, estas rotas podem ser abstraídas em quatro categorias (com alguma sobreposição, mas foco narrativo distinto):
Rota A: Imutabilidade permanente e reprodutibilidade pública
- Palavras-chave: pagamento único, legibilidade a longo prazo, combate à deterioração de links.
- Exemplo: Arweave. Após o lançamento da mainnet AO em 2025, a narrativa do ecossistema destaca a orquestração de computação verificável sobre dados permanentes, respondendo à necessidade de alinhamento de conjuntos de dados e instantâneos de modelos a longo prazo.
Rota B: Armazenamento verificável com orquestração de pagamento/contrato on-chain
- Palavras-chave: PDP (Proof of Data Possession), auditabilidade multi-réplica, faturação on-chain.
- Exemplo: Filecoin Onchain Cloud. A documentação pública destaca armazenamento programável e liquidação on-chain, com cenários como armazenamento persistente gerido por Agente de IA e proveniência de dados em pipelines de IA. O ecossistema inclui backup e arquivamento em camadas com produtos como Akave.
Rota C: Plataformas de dados verificáveis em cadeias públicas de alto desempenho
- Palavras-chave: leituras de baixa latência (dependendo do tamanho do objeto e da rede), controlo de acesso (por exemplo, Seal), contas e contratos unificados com aplicações on-chain.
- Exemplo: Walrus (ecossistema Sui). Casos oficiais e de parceiros incluem armazenamento de modelos de Agente de IA e histórico de decisões, caminhos de treino relacionados com privacidade (como aprendizagem federada), com foco em permissões verificáveis e programáveis.
Rota D: Armazenamento de objetos compatível com S3 habilitado por DePIN ou componente modular nativo para IA
- Palavras-chave: API S3, escala de rede de nodos, integração fluida com ferramentas MLOps existentes.
- Exemplos: AIOZ Storage (posicionado ao lado de AIOZ AI na pipeline de dados Web3 IA); 0G Storage na documentação 0G, descrito como camada de armazenamento para grandes conjuntos de dados de IA e pesos de modelos, formando uma pilha modular com 0G Compute, 0G DA e 0G Chain.
Distinção importante: DA (Data Availability) serve principalmente rollups e provas de disponibilidade de dados on-chain. Armazenar "100 TB de dados de treino" é um desafio de engenharia distinto; contudo, em estruturas full-stack como 0G, DA e armazenamento são apresentados em conjunto e devem ser avaliados separadamente.
Visão geral de projetos representativos (classificados por rota)
As entradas seguintes baseiam-se em roadmaps públicos e blogs oficiais, não estão ordenadas por capitalização de mercado ou desempenho de token, e não constituem aconselhamento de investimento.
Camada permanente: Arweave e ecossistema AO
- Posicionamento: Focado em permaweb e legibilidade a longo prazo, ideal para instantâneos de modelos e conjuntos de dados, ciência aberta e publicação resistente à censura.
- Integração IA: Mais orientado para cadeias de evidência e reprodutibilidade do que para leituras de baixa latência garantidas.
- Pontos de avaliação: Economia de escrita, disponibilidade de gateways e dependência de caminhos de leitura em determinados provedores de gateway.
Cloud verificável: Filecoin Onchain Cloud e produtos de camada superior como Akave
- Posicionamento: Productiza posse verificável, estratégias de réplica e pagamento on-chain para backup empresarial, arquivamento de conformidade e pipelines auditáveis.
- Integração IA: Materiais públicos destacam automação de Agente para armazenamento e proveniência em pipelines de treino/inferência.
- Pontos de avaliação: Escala de conjuntos de dados e casos de cliente, custo de integração de ferramentas de prova, desempenho entre regiões.
Plataforma de dados verificável: Walrus
- Posicionamento: Construído para verificabilidade, programabilidade e controlo de privacidade (por exemplo, Seal), profundamente integrado no ecossistema de aplicações Sui.
- Integração IA: Parcerias de ecossistema abrangem ciclo de vida de dados de Agente e colaborações de treino com privacidade.
- Pontos de avaliação: Latência por tamanho de objeto, limites de encriptação e Gestão de chaves, profundidade de integração.
Armazenamento de objetos DePIN: AIOZ Storage e outros
- Posicionamento: Compatível com S3, destaca escala de nodos e migração de baixo atrito.
- Integração IA: Alinhado diretamente com práticas de engenharia como alojamento de conjuntos de dados e distribuição de artefactos.
- Pontos de avaliação: Comparação de custos justa com cloud centralizada requer pressupostos de mesma região, camadas hot/cold e egress.
Full-stack modular: 0G
- Posicionamento: Integra armazenamento, Hashrate, DA e cadeia como módulos sob uma visão unificada de deAIOS/AI L1.
- Integração IA: A documentação enfatiza elevado throughput, camada de armazenamento para pesos e logs, e camada KV para embeddings e estado de Agente.
- Pontos de avaliação: Se a maturidade de cada módulo corresponde ao gargalo mais crítico (frequentemente Hashrate ou pipeline de dados).
Outros projetos frequentemente referenciados mas não focados em armazenamento
- Por exemplo, Fluence e outros projetos GPU/Hashrate descentralizado: Citados em discussões "IA + DePIN", mas não devem ser classificados como infraestrutura de armazenamento salvo se oferecem explicitamente SLA de armazenamento de objetos em larga escala.
Mesmo com narrativas alinhadas à IA, três restrições principais mantêm-se na implementação:
-
Restrições de engenharia: latência, consistência e toolchains
- Sistemas distribuídos exigem frequentemente middleware adicional para ficheiros pequenos, elevado QPS, sincronização entre regiões e uploads retomáveis.
- "Descentralização" não significa automaticamente menor custo; o TCO para arquivamento cold e leituras hot deve ser comparado.
-
Restrições de modelo económico: incentivos de token e pagamento real
- Muitas redes incentivam tanto miners/nodos como utilizadores finais.
- A volatilidade do preço do token afeta retenção de fornecedores, impactando disponibilidade e qualidade de serviço a longo prazo.
-
Conformidade e governação de dados: chaves, transfronteiras e direitos de autor
- Conjuntos de dados de IA envolvem frequentemente direitos de autor e informação pessoal; a verificabilidade on-chain não resolve por si só questões legais de origem.
- Clientes empresariais questionam custódia de chaves, direitos de eliminação e residência de dados: existe tensão inerente entre armazenamento permanente e o "direito ao esquecimento", que exige coordenação entre equipas de produto e jurídicas.
A narrativa "IA + armazenamento" está em alta, mas a verdadeira usabilidade depende da clarificação das cargas de trabalho: se os objetos servem para arquivamento cold ou leituras hot; SLO para throughput e latência; como responsabilidades de chave e conformidade são implementadas contratualmente; e se os incentivos de token estão alinhados com pagamentos reais. As quatro rotas em camadas (camada permanente, cloud verificável, armazenamento de objetos no ecossistema on-chain e armazenamento modular full-stack) podem coexistir mas não são intercambiáveis: a camada permanente destaca-se na consistência a longo prazo e replay público; clouds verificáveis são fortes em faturação e orquestração; soluções compatíveis com S3 reduzem custos de migração; e abordagens modulares full-stack oferecem uma narrativa integrada mas requerem validação de maturidade para cada módulo.
O filtro final é simples: primeiro, verificar se o uso verificável e casos de cliente sustentam a narrativa; depois comparar TCO e latência em bases iguais; e por fim, discutir tokens e avaliação. Esta abordagem minimiza equívocos comuns, como tratar DA como "armazém de corpus" ou projetos de Hashrate como "infraestrutura de armazenamento".
Isenção de responsabilidade: este artigo compila informação técnica e de indústria e não constitui qualquer tipo de aconselhamento de investimento. Detalhes sobre fases de mainnet, parceiros e métricas de desempenho podem sofrer alterações com atualizações oficiais. Consultar os livros brancos, documentação e divulgações de auditoria mais recentes das equipas de projeto.







