Fonte original: Heart of the Machine
 Fonte da imagem: Gerado por Unbounded AI
Fonte da imagem: Gerado por Unbounded AI
A inteligência artificial está a avançar rapidamente, mas há muitos problemas. A nova API de visão GPT da OpenAI faz as pessoas suspirarem que o pé da frente é muito eficaz, e o pé de trás está reclamando do problema da ilusão.
As alucinações sempre foram a falha fatal dos grandes modelos. Devido ao grande e complexo conjunto de dados, é inevitável que haja informações desatualizadas e erradas nele, resultando em um teste severo de qualidade de saída. O excesso de informações repetitivas também pode enviesar grandes modelos, o que também é uma forma de ilusão. Mas as alucinações não são insolúveis. O uso cuidadoso e a filtragem rigorosa de conjuntos de dados durante o processo de desenvolvimento, bem como a construção de conjuntos de dados de alta qualidade, bem como a otimização da estrutura do modelo e dos métodos de treinamento podem aliviar o problema da ilusão até certo ponto.
Há tantos grandes modelos em voga, e quão eficazes eles são no alívio das alucinações? Aqui está uma tabela de classificação que contrasta claramente a diferença.
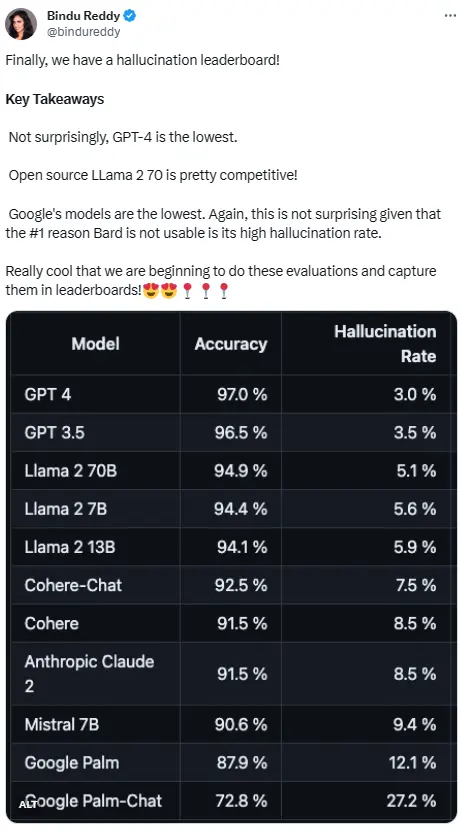 A tabela de classificação é publicada pela plataforma Vectara focada em IA. A tabela de classificação foi atualizada em 1º de novembro de 2023, e a Vectara disse que continuaria acompanhando as avaliações de alucinação à medida que o modelo fosse atualizado.
A tabela de classificação é publicada pela plataforma Vectara focada em IA. A tabela de classificação foi atualizada em 1º de novembro de 2023, e a Vectara disse que continuaria acompanhando as avaliações de alucinação à medida que o modelo fosse atualizado.
Endereço do projeto:
Para determinar essa tabela de classificação, Vectara conduziu um estudo de consistência factual no modelo de resumo usando uma variedade de conjuntos de dados de código aberto e treinou um modelo para detetar alucinações na saída LLM. Eles usaram um modelo semelhante ao SOTA e, em seguida, alimentaram 1.000 documentos curtos para cada um desses LLMs por meio de uma API pública e pediram que resumissem cada documento usando apenas os fatos apresentados no documento. Destes 1000 documentos, apenas 831 foram resumidos por cada modelo, e os restantes foram rejeitados por pelo menos um modelo devido a limitações de conteúdo. Usando esses 831 arquivos, Vectara calculou a precisão geral e taxa de alucinação para cada modelo. A taxa de rejeição de respostas para cada modelo é detalhada na coluna “Taxa de resposta”. Nenhum dos conteúdos enviados para o modelo contém conteúdo ilegal ou inseguro, mas as palavras-gatilho nele contidas são suficientes para acionar alguns filtros de conteúdo. Estes documentos são principalmente do corpus CNN/Daily Mail.
 É importante notar que o Vectara avalia a precisão do resumo, não a precisão factual geral. Isso permite comparar a resposta do modelo com as informações fornecidas. Em outras palavras, o resumo de saída é avaliado como “factualmente consistente” como o documento de origem. Uma vez que não se sabe em que dados cada LLM é treinado, é impossível determinar alucinações para qualquer problema em particular. Além disso, para construir um modelo que possa determinar se uma resposta é uma ilusão sem uma fonte de referência, o problema da alucinação precisa ser abordado, e um modelo que é tão grande ou maior do que o LLM que está sendo avaliado precisa ser treinado. Como resultado, Vectara optou por olhar para a taxa de alucinação na tarefa de resumo, pois tal analogia seria uma boa maneira de determinar o realismo geral do modelo.
É importante notar que o Vectara avalia a precisão do resumo, não a precisão factual geral. Isso permite comparar a resposta do modelo com as informações fornecidas. Em outras palavras, o resumo de saída é avaliado como “factualmente consistente” como o documento de origem. Uma vez que não se sabe em que dados cada LLM é treinado, é impossível determinar alucinações para qualquer problema em particular. Além disso, para construir um modelo que possa determinar se uma resposta é uma ilusão sem uma fonte de referência, o problema da alucinação precisa ser abordado, e um modelo que é tão grande ou maior do que o LLM que está sendo avaliado precisa ser treinado. Como resultado, Vectara optou por olhar para a taxa de alucinação na tarefa de resumo, pois tal analogia seria uma boa maneira de determinar o realismo geral do modelo.
Detetar o endereço do modelo de ilusão:
Além disso, LLMs estão sendo cada vez mais usados em pipelines RAG (Retri Augmented Generation) para responder a consultas de usuários, como integrações do Bing Chat e do Google Chat. Em um sistema RAG, o modelo é implantado como um agregador de resultados de pesquisa, de modo que a tabela de classificação também é um bom indicador de quão preciso o modelo é quando usado em um sistema RAG.
Devido ao desempenho consistentemente excelente do GPT-4, parece ser esperado que ele tenha a menor taxa de alucinação. No entanto, alguns internautas disseram que ele ficou surpreso que GPT-3.5 e GPT-4 não estavam muito distantes.
 LLaMA 2 tem um melhor desempenho após GPT-4 e GPT-3.5. Mas o desempenho do grande modelo do Google realmente não é satisfatório. Alguns internautas disseram que o Google BARD costuma usar “ainda estou treinando” para prevaricar suas respostas erradas.
LLaMA 2 tem um melhor desempenho após GPT-4 e GPT-3.5. Mas o desempenho do grande modelo do Google realmente não é satisfatório. Alguns internautas disseram que o Google BARD costuma usar “ainda estou treinando” para prevaricar suas respostas erradas.
 Com essa tabela de classificação, podemos ter um julgamento mais intuitivo das vantagens e desvantagens de diferentes modelos. Alguns dias atrás, OpenAI lançou GPT-4 Turbo, não, alguns internautas imediatamente propôs atualizá-lo na tabela de classificação também.
Com essa tabela de classificação, podemos ter um julgamento mais intuitivo das vantagens e desvantagens de diferentes modelos. Alguns dias atrás, OpenAI lançou GPT-4 Turbo, não, alguns internautas imediatamente propôs atualizá-lo na tabela de classificação também.
 Veremos como será o próximo ranking e se haverá mudanças significativas.
Veremos como será o próximo ranking e se haverá mudanças significativas.
Link de referência:
Isenção de responsabilidade: As informações contidas nesta página podem ser provenientes de terceiros e não representam os pontos de vista ou opiniões da Gate. O conteúdo apresentado nesta página é apenas para referência e não constitui qualquer aconselhamento financeiro, de investimento ou jurídico. A Gate não garante a exatidão ou o carácter exaustivo das informações e não poderá ser responsabilizada por quaisquer perdas resultantes da utilização destas informações. Os investimentos em ativos virtuais implicam riscos elevados e estão sujeitos a uma volatilidade de preços significativa. Pode perder todo o seu capital investido. Compreenda plenamente os riscos relevantes e tome decisões prudentes com base na sua própria situação financeira e tolerância ao risco. Para mais informações, consulte a
Isenção de responsabilidade.
