Fonte original: New Zhiyuan
 Fonte da imagem: Gerado por Unbounded AI
Fonte da imagem: Gerado por Unbounded AI
Há algum tempo, o Google DeepMind propôs um novo método “Step-Backing”, que fez diretamente a tecnologia abrir o cérebro.
Para simplificar, é deixar o modelo de linguagem grande abstrair o problema por si só, obter um conceito ou princípio de dimensão superior e, em seguida, usar o conhecimento abstrato como uma ferramenta para raciocinar e derivar a resposta para o problema.
 Endereço:
Endereço:
Os resultados também foram muito bons, pois experimentaram o modelo PaLM-2L e provaram que esta nova técnica funcionava muito bem no tratamento de certas tarefas e problemas.
Por exemplo, MMLU tem uma melhoria de 7% no desempenho físico e químico, uma melhoria de 27% no TimeQA, e uma melhoria de 7% no MuSiQue.
Entre eles, o MMLU é um conjunto de dados de teste de compreensão de linguagem multitarefa em grande escala, o TimeOA é um conjunto de dados de teste de perguntas sensíveis ao tempo e o MusiQue é um conjunto de dados de perguntas e respostas multi-hop contendo 25.000 perguntas de 2 a 4 saltos.
Entre eles, um problema multi-hop refere-se a uma pergunta que só pode ser respondida usando um caminho de inferência multi-hop formado por múltiplos triplos.
Abaixo, vamos dar uma olhada em como essa tecnologia é implementada.
Afasta-te!
Depois de ler a introdução no início, os leitores podem não entender muito. O que significa para os LLMs abstrair o problema e obter um conceito ou princípio de dimensão superior?
Vamos dar um exemplo específico.
Por exemplo, se o usuário quiser fazer uma pergunta relacionada à “força” em física, então o LLM pode voltar ao nível da definição básica e princípio de força ao responder a tal pergunta, que pode ser usada como base para raciocínio adicional sobre a resposta.
Com base nessa ideia, quando o usuário entra pela primeira vez, é mais ou menos assim:
Você agora é um especialista em conhecimento do mundo, hábil em pensar cuidadosamente e responder perguntas passo a passo com uma estratégia de questionamento retrógrada.
Recuar é uma estratégia de pensamento para compreender e analisar um determinado problema ou situação a partir de uma perspetiva mais macro e fundamental. Respondendo, assim, melhor à pergunta original.
É claro que o exemplo de física dado acima ilustra apenas um caso. Em alguns casos, a estratégia de back-down pode permitir que o LLM tente identificar o escopo e o contexto do problema. Alguns problemas recuam um pouco mais, e outros caem menos.
Tese
Em primeiro lugar, os pesquisadores apontam que o campo do processamento de linguagem natural (NLP) inaugurou uma revolução revolucionária com LLMs baseados em Transformers.
A expansão do tamanho do modelo e o aumento do corpus pré-treinado trouxeram melhorias significativas nas capacidades do modelo e na eficiência da amostragem, bem como nas capacidades emergentes, como a inferência em várias etapas e o seguimento de instruções.
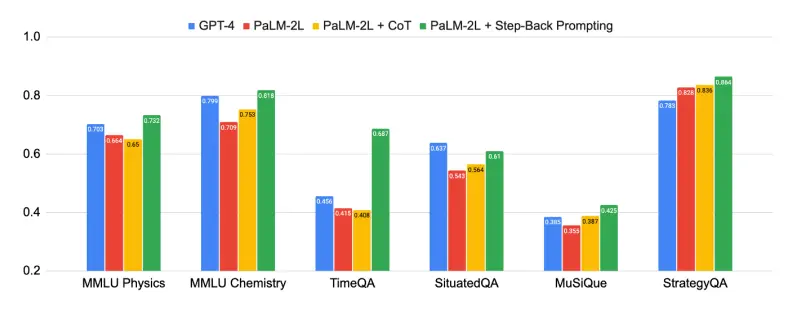 A figura acima mostra o poder do raciocínio retrógrado, e o método de “raciocínio abstrato” proposto neste artigo fez melhorias significativas em uma variedade de tarefas difíceis que exigem raciocínio complexo, como ciência, tecnologia, engenharia e matemática, e raciocínio multi-hop.
A figura acima mostra o poder do raciocínio retrógrado, e o método de “raciocínio abstrato” proposto neste artigo fez melhorias significativas em uma variedade de tarefas difíceis que exigem raciocínio complexo, como ciência, tecnologia, engenharia e matemática, e raciocínio multi-hop.
Algumas tarefas foram muito desafiadoras e, no início, PaLM-2L e GPT-4 eram apenas 40% precisos no TimeQA e MuSiQue. Depois de aplicar o raciocínio retrógrado, o desempenho do PaLM-2L melhorou em toda a linha. Melhorou em 7% e 11% em física e química MMLU, 27% em TimeQA e 7% em MuSiQue.
Não só isso, mas os pesquisadores também conduziram a análise de erros, e descobriram que a maioria dos erros que ocorrem ao aplicar o raciocínio retrógrado são devidos às limitações inerentes à capacidade de inferência dos LLMs, e não estão relacionados às novas tecnologias.
A abstração é mais fácil para os LLMs aprenderem, por isso aponta o caminho para o desenvolvimento do raciocínio retrógrado.
Embora tenham sido feitos progressos, o raciocínio complexo em várias etapas pode ser um desafio. Isto é verdade mesmo para os LLMs mais avançados.
Este artigo mostra que a supervisão do processo com função de verificação passo-a-passo é uma solução eficaz para melhorar a correção das etapas intermediárias de raciocínio.
Eles introduziram técnicas como prompts de cadeia de pensamento para gerar uma série coerente de etapas de inferência intermediárias, aumentando a taxa de sucesso de seguir o caminho de decodificação correto.
Ao falar sobre a origem dessa tecnologia PROMP, os pesquisadores apontaram que, quando confrontados com tarefas desafiadoras, os seres humanos tendem a dar um passo atrás e abstrato, de modo a derivar conceitos e princípios de alto nível para orientar o processo de raciocínio.
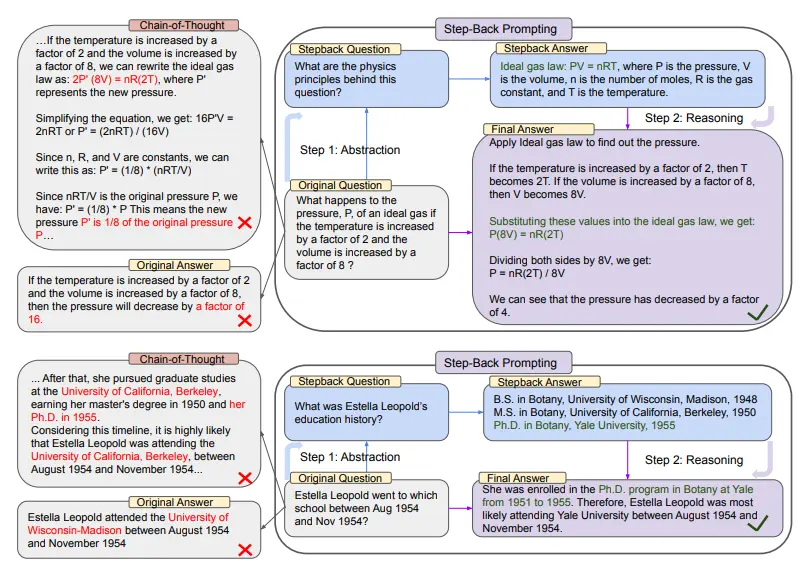 Na parte superior da figura acima, tomando como exemplo a física do ensino médio de MMLU, através da abstração retrógrada, LLM obtém o primeiro princípio da lei dos gases ideais.
Na parte superior da figura acima, tomando como exemplo a física do ensino médio de MMLU, através da abstração retrógrada, LLM obtém o primeiro princípio da lei dos gases ideais.
No segundo semestre, há um exemplo do TimeQA, onde o conceito de alto nível da história da educação é o resultado da abstração do LLM com base nessa estratégia.
Do lado esquerdo de todo o diagrama, podemos ver que o PaLM-2L não foi bem sucedido em responder à pergunta original. A cadeia de pensamento indica que, no meio da etapa de raciocínio, o LLM cometeu um erro (destacado em vermelho).
E à direita, o PaLM-2L, com a aplicação da tecnologia backward, respondeu com sucesso à pergunta.
Entre as muitas habilidades cognitivas, o pensamento abstrato é onipresente para a capacidade humana de processar grandes quantidades de informações e derivar regras e princípios gerais.
Para citar alguns, Kepler destilou milhares de medições nas Três Leis do Movimento Planetário de Kepler, que descrevem com precisão as órbitas dos planetas ao redor do Sol.
Ou, na tomada de decisões críticas, os seres humanos também acham a abstração útil porque fornece uma visão mais ampla do ambiente.
O foco deste artigo é como os LLMs podem lidar com tarefas complexas envolvendo muitos detalhes de baixo nível através de uma abordagem em duas etapas de abstração e raciocínio.
O primeiro passo é ensinar os LLMs a dar um passo atrás e derivar conceitos abstratos de alto nível a partir de exemplos concretos, como conceitos fundamentais e primeiros princípios dentro de um domínio.
O segundo passo é usar habilidades de raciocínio para basear a solução em conceitos de alto nível e primeiros princípios.
Os pesquisadores usaram um pequeno número de exemplos em LLMs para realizar inferência para trás. Eles experimentaram uma série de tarefas envolvendo raciocínio específico de domínio, resolução de problemas com uso intensivo de conhecimento, raciocínio de senso comum multi-hop que exigia conhecimento factual.
Os resultados mostram que o desempenho do PaLM-2L é significativamente melhorado (até 27%), o que prova que a inferência backward é muito eficaz para lidar com tarefas complexas.
Durante os experimentos, os pesquisadores experimentaram os seguintes tipos diferentes de tarefas:
(1)STEM
(2) Conhecimento de GQ
(3) Raciocínio multi-hop
Os pesquisadores avaliaram a aplicação em tarefas STEM para medir a eficácia da nova abordagem no raciocínio em campos altamente especializados. (Este artigo abordará apenas essas questões)
Obviamente, o problema no benchmark MMLU requer um raciocínio mais profundo por parte do LLM. Além disso, requerem a compreensão e aplicação de fórmulas, que muitas vezes são princípios e conceitos físicos e químicos.
Neste caso, o pesquisador primeiro ensina o modelo a ser abstraído na forma de conceitos e primeiros princípios, como a primeira lei do movimento de Newton, o efeito Doppler e a energia livre de Gibbs. A pergunta implícita aqui é: “Quais são os princípios e conceitos físicos ou químicos envolvidos na resolução desta tarefa?”
A equipe forneceu demonstrações que ensinaram o modelo a memorizar os princípios de resolução de tarefas a partir de seu próprio conhecimento.
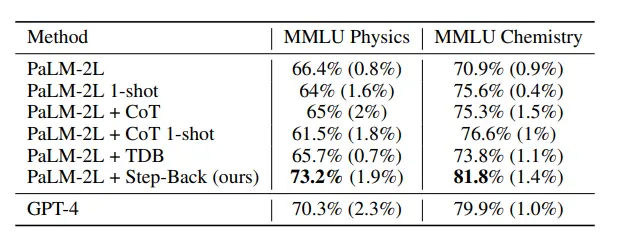 A tabela acima mostra o desempenho do modelo usando a técnica de inferência backward, e o LLM com a nova tecnologia teve um bom desempenho em tarefas STEM, atingindo o nível mais avançado além do GPT-4.
A tabela acima mostra o desempenho do modelo usando a técnica de inferência backward, e o LLM com a nova tecnologia teve um bom desempenho em tarefas STEM, atingindo o nível mais avançado além do GPT-4.
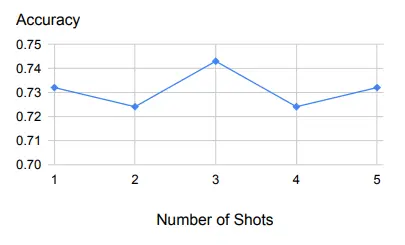 A tabela acima é um exemplo de um pequeno número de amostras e demonstra um desempenho robusto com tamanhos de amostra variáveis.
A tabela acima é um exemplo de um pequeno número de amostras e demonstra um desempenho robusto com tamanhos de amostra variáveis.
Primeiro, como podemos ver no gráfico acima, a inferência retrógrada é muito robusta para um pequeno número de exemplos usados como demonstrações.
Além de um exemplo, o mesmo será válido para adicionar mais exemplos.
Isto sugere que a tarefa de recuperar princípios e conceitos relevantes é relativamente fácil de aprender, e um exemplo de demonstração é suficiente.
É claro que, no decorrer da experiência, ainda haverá alguns problemas.
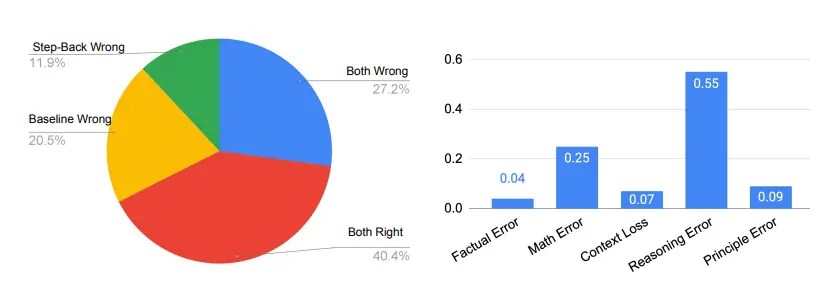
Os cinco tipos de erros que ocorrem em todos os artigos, exceto os erros de princípio, ocorrem na etapa de raciocínio do LLM, enquanto os erros de princípio indicam o fracasso da etapa de abstração.
Como você pode ver no lado direito da figura abaixo, os erros de princípio na verdade representam apenas uma pequena fração dos erros do modelo, com mais de 90% dos erros ocorrendo na etapa de inferência. Dos quatro tipos de erros no processo de raciocínio, os erros de raciocínio e os erros matemáticos são os principais locais onde os erros estão localizados.
Isso está de acordo com as descobertas em estudos de ablação de que apenas alguns exemplos são necessários para ensinar LLMs como abstrair. A etapa de inferência ainda é um gargalo para a inferência retrógrada para concluir tarefas que exigem inferência complexa, como MMLU.
Isto é especialmente verdadeiro para a Física MMLU, onde as habilidades de raciocínio e matemática são fundamentais para a resolução bem-sucedida de problemas. Isso significa que, mesmo que o LLM recupere os primeiros princípios corretamente, ele ainda tem que passar por um típico processo de raciocínio de várias etapas para chegar à resposta final correta, o que exige que o LLM tenha raciocínio profundo e habilidades matemáticas.
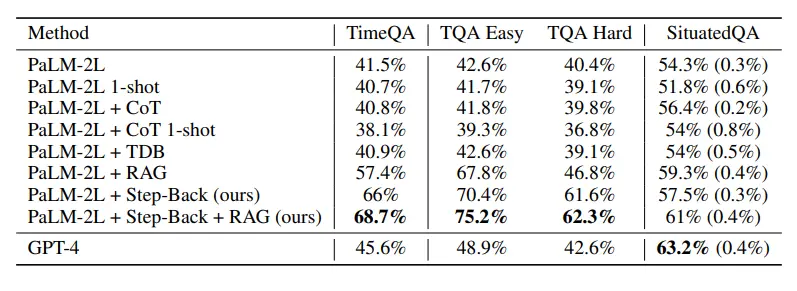
 Os pesquisadores então avaliaram o modelo no conjunto de testes do TimeQA.
Os pesquisadores então avaliaram o modelo no conjunto de testes do TimeQA.
Como mostra a figura abaixo, os modelos basais de GPT-4 e PaLM-2L atingiram 45,6% e 41,5%, respectivamente, destacando a dificuldade da tarefa.
CoT ou TDB foi aplicado zero vezes (e uma vez) no modelo basal sem qualquer melhoria.
Em contraste, a precisão do modelo de linha de base aprimorada pelo aumento regular de recuperação (RAG) aumentou para 57,4%, destacando a natureza intensiva de fatos da tarefa.
Os resultados do Step-Back + RAG mostram que o LLM de volta à etapa de conceitos avançados é muito eficaz na inferência para trás, o que torna o link de recuperação LLM mais confiável, e podemos ver que o TimeQA tem uma precisão surpreendente de 68,7%.
Em seguida, os pesquisadores dividiram o TimeQA em dois níveis de dificuldade: fácil e difícil fornecidos no conjunto de dados original.
Não surpreendentemente, todos os LLMs têm um desempenho ruim no nível difícil. Enquanto a RAG foi capaz de aumentar a precisão de 42,6% para 67,8% no nível fácil, a melhoria foi muito menor para o nível duro, com os dados mostrando apenas um aumento de 40,4% para 46,8%.
E é aqui que entra a técnica do raciocínio retrógrado, pois recupera fatos sobre conceitos de nível superior e estabelece as bases para o raciocínio final.
O raciocínio retrógrado mais RAG melhorou ainda mais a precisão para 62,3%, superando os 42,6% do GPT-4.
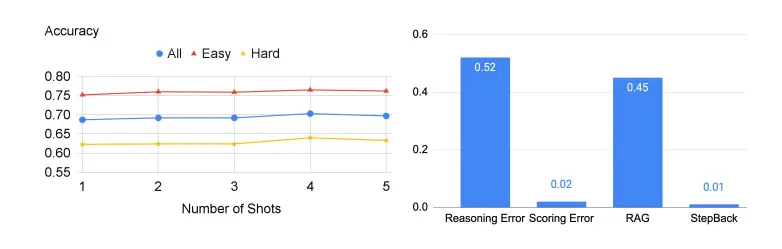
 Claro, ainda existem alguns problemas com esta tecnologia quando se trata de TimeQA.
Claro, ainda existem alguns problemas com esta tecnologia quando se trata de TimeQA.
A figura abaixo mostra a precisão do LLM nesta parte do experimento e a probabilidade de erro ocorrer à direita.
 Recursos:
Recursos:
