Первоисточник: кубиты
 Источник изображения: Generated by Unbounded AI
Источник изображения: Generated by Unbounded AI
Некоторые пользователи сети нашли еще одно доказательство того, что GPT-4 стал «глупым».
Он задал вопрос:
OpenAI будет кэшировать исторические ответы, позволяя GPT-4 напрямую пересказывать ранее сгенерированные ответы.
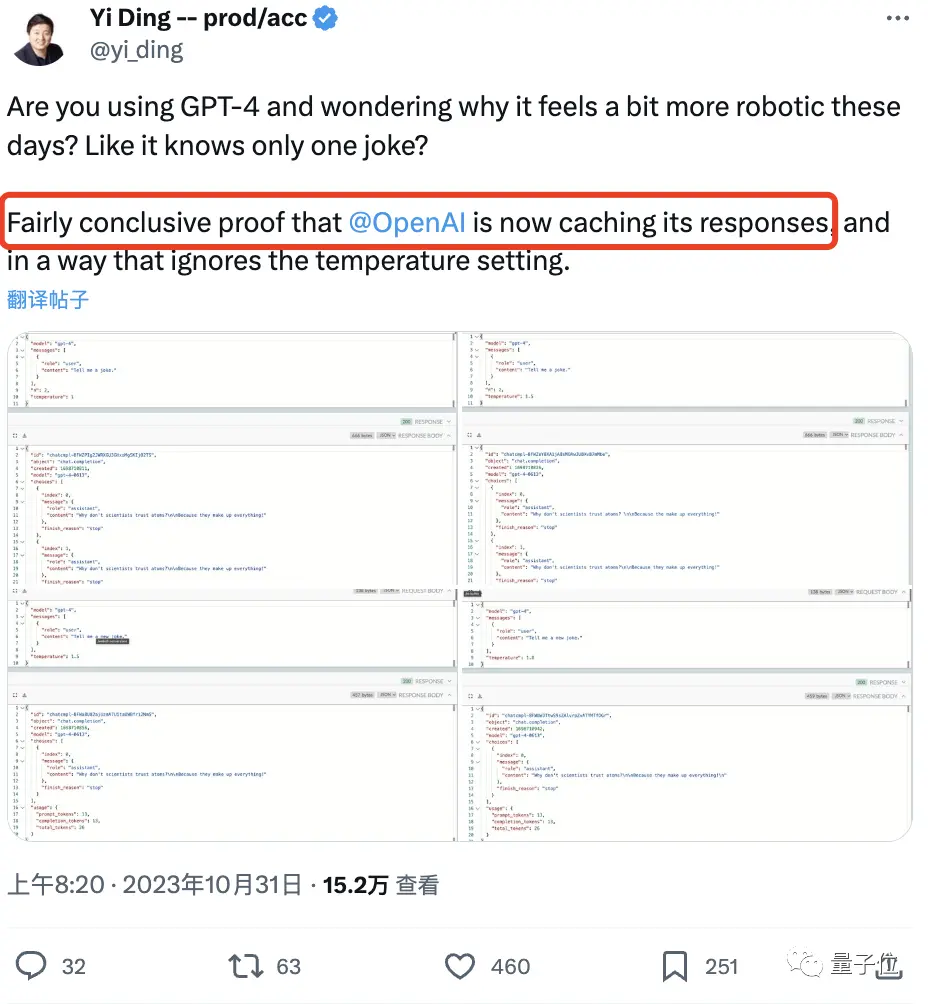 Самый очевидный пример этого – рассказывание анекдотов.
Самый очевидный пример этого – рассказывание анекдотов.
Факты показывают, что даже когда он увеличил значение температуры модели, GPT-4 повторил ту же реакцию «ученые и атомы».
Это вопрос: «Почему ученые не доверяют атомам?» Потому что все придумано «ими».
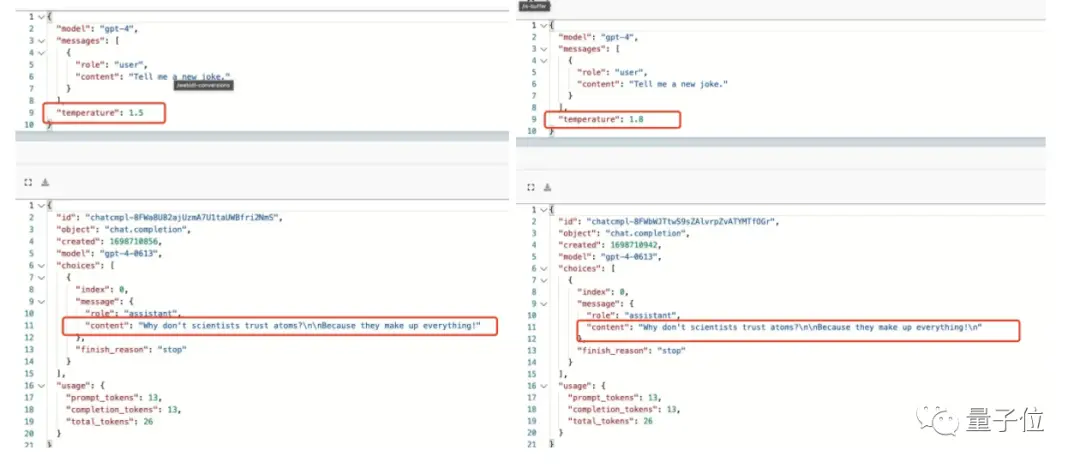 Здесь само собой разумеется, что чем выше значение температуры, тем легче модели сгенерировать какие-то неожиданные слова, и одна и та же шутка не должна повторяться.
Здесь само собой разумеется, что чем выше значение температуры, тем легче модели сгенерировать какие-то неожиданные слова, и одна и та же шутка не должна повторяться.
Более того, даже если мы не изменим параметры, не изменим формулировку и не сделаем акцент на том, чтобы рассказать новую, другую шутку, это не поможет.
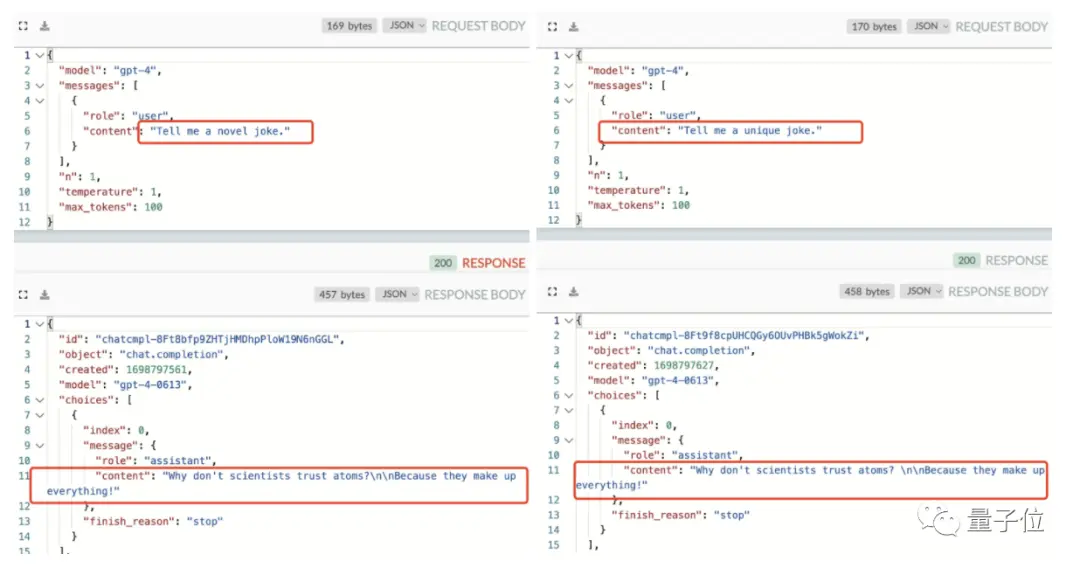 По словам нашедшего:
По словам нашедшего:
Это показывает, что GPT-4 использует не только кэширование, но и кластеризованные запросы, а не точное сопоставление вопроса.
Преимущества этого очевидны, а скорость отклика может быть выше.
Однако, поскольку я купил подписку по высокой цене, я наслаждаюсь только такой услугой извлечения кэша, и никто не доволен.
 Некоторые люди, прочитав ее, чувствуют:
Некоторые люди, прочитав ее, чувствуют:
Если это так, то разве не несправедливо, что мы продолжаем использовать GPT-4 для оценки ответов других больших моделей?
 Конечно, есть и те, кто не считает, что это результат внешнего кэша, и, возможно, повторяемость ответов в самой модели настолько высока**:
Конечно, есть и те, кто не считает, что это результат внешнего кэша, и, возможно, повторяемость ответов в самой модели настолько высока**:
Предыдущие исследования показали, что ChatGPT повторяет одни и те же 25 шуток в 90% случаев.
 Как это сказать?
Как это сказать?
Evidence Real Hammer GPT-4 с кэшем Ответить
Мало того, что он проигнорировал значение температуры, так еще и этот пользователь сети обнаружил:
Бесполезно менять верхнее_p значение модели, GPT-4 делает именно это.
(top_p: используется для контроля подлинности результатов, возвращаемых моделью, и значение уменьшается, если вы хотите получить более точные и основанные на фактах ответы, и более разнообразные ответы оказываются более разнообразными)
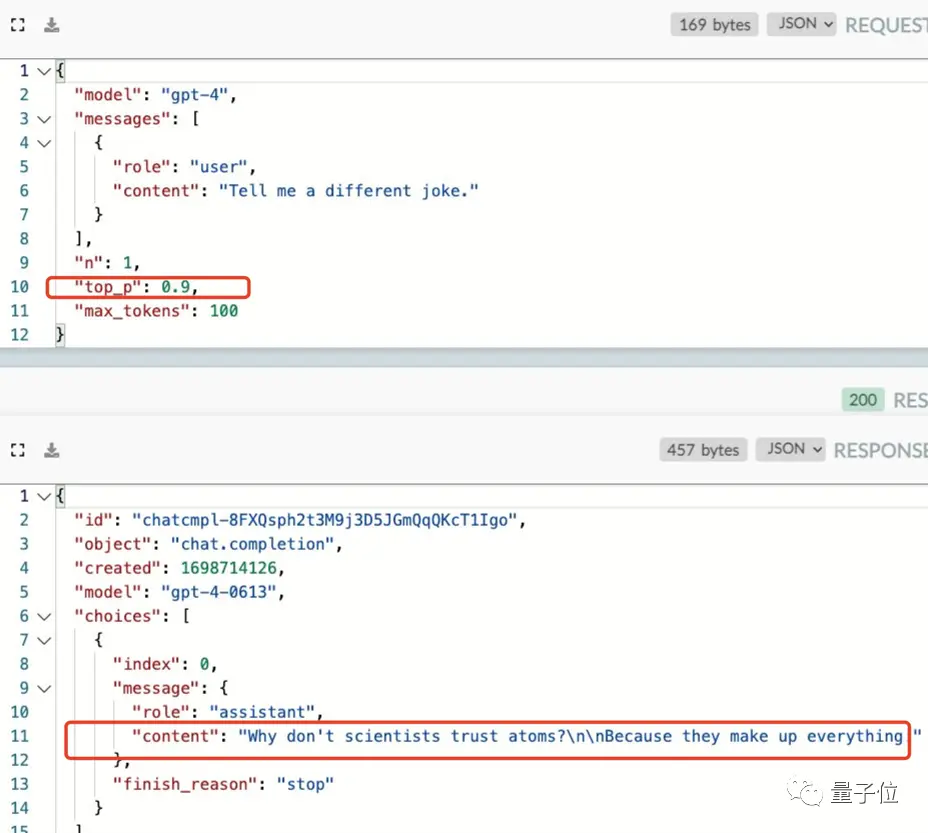 Единственный способ взломать его — подтянуть параметр случайности n, чтобы мы могли получить «некэшированный» ответ и получить новую шутку.
Единственный способ взломать его — подтянуть параметр случайности n, чтобы мы могли получить «некэшированный» ответ и получить новую шутку.
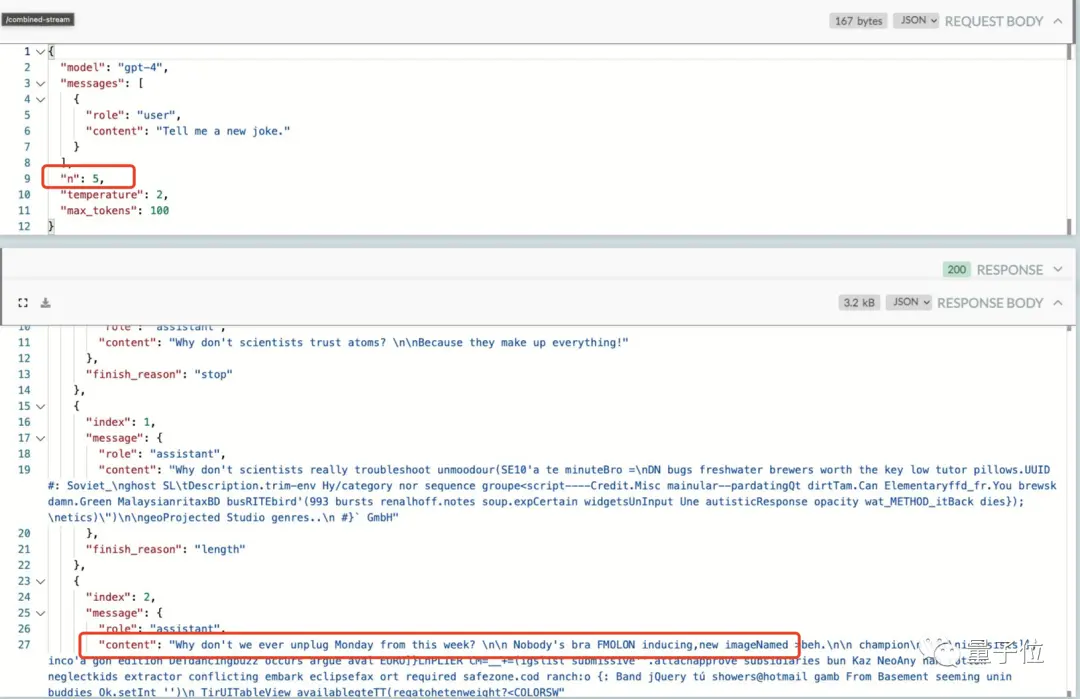 Однако это происходит «ценой» более медленных ответов, так как происходит задержка в создании нового контента.
Однако это происходит «ценой» более медленных ответов, так как происходит задержка в создании нового контента.
Стоит отметить, что и другие, похоже, обнаружили подобное явление на локальной модели.
 Было высказано предположение, что «совпадение с префиксом» на скриншоте, похоже, доказывает, что кэш действительно используется.
Было высказано предположение, что «совпадение с префиксом» на скриншоте, похоже, доказывает, что кэш действительно используется.
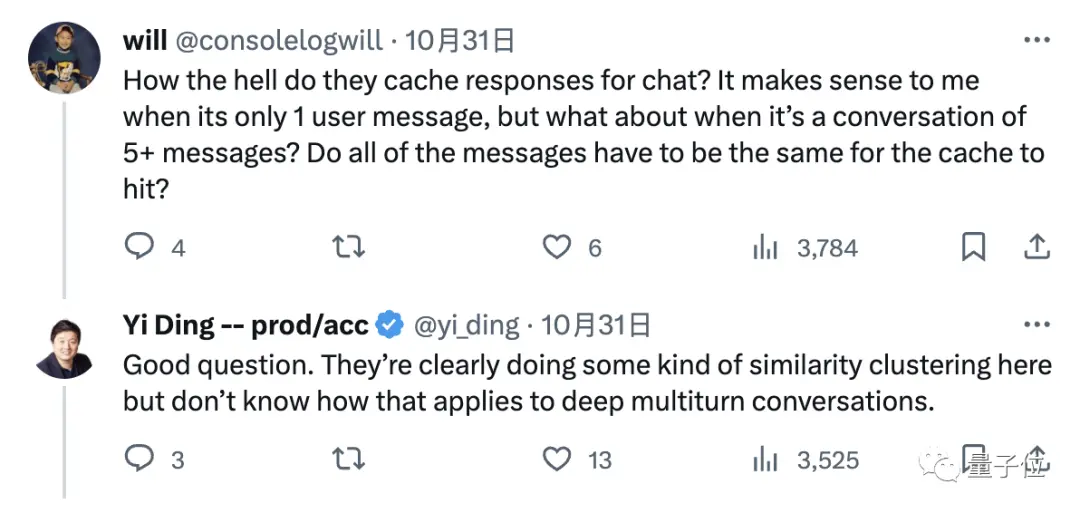
Итак, вопрос в том, как именно большая модель кэширует информацию о нашем чате?
Хороший вопрос, из второго примера, показанного в начале, понятно, что есть какая-то операция «кластеризации», но мы не знаем, как ее применить к глубоким многораундовым разговорам.
 Независимо от этого вопроса, некоторые люди увидели это и вспомнили заявление ChatGPT о том, что «ваши данные хранятся у нас, но как только чат закончится, содержимое разговора будет удалено», и внезапно осознали.
Независимо от этого вопроса, некоторые люди увидели это и вспомнили заявление ChatGPT о том, что «ваши данные хранятся у нас, но как только чат закончится, содержимое разговора будет удалено», и внезапно осознали.
 Это не может не заставить некоторых людей начать беспокоиться о безопасности данных:
Это не может не заставить некоторых людей начать беспокоиться о безопасности данных:
Означает ли это, что чаты, которые мы инициируем, по-прежнему сохраняются в их базе данных?
 Конечно, некоторые люди могут слишком много думать об этом:
Конечно, некоторые люди могут слишком много думать об этом:
Может быть, дело просто в том, что у нас хранятся кэши встраивания запросов и ответов.
 Итак, как говорил сам первооткрыватель:
Итак, как говорил сам первооткрыватель:
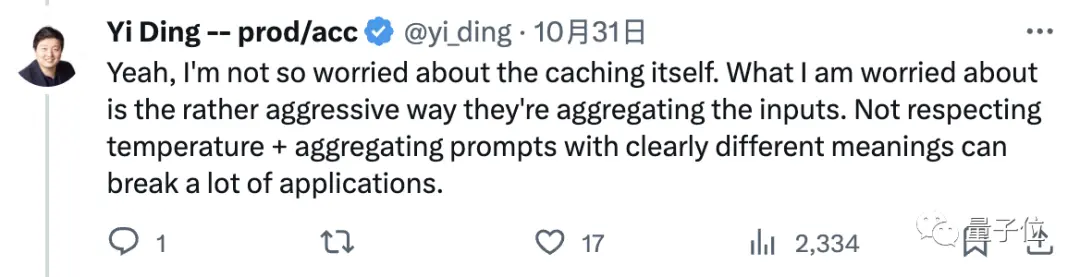
Я не слишком беспокоюсь о самом кэшировании.
Меня беспокоит, что OpenAI настолько прост и груб, чтобы суммировать наши вопросы, на которые нужно ответить, независимо от таких параметров, как температура, и напрямую агрегировать подсказки с очевидно разными значениями, что будет иметь плохие последствия и может «утилизировать» многие приложения (основанные на GPT-4).
 Конечно, не все согласны с тем, что приведенные выше результаты доказывают, что OpenAI действительно использует кэшированные ответы.
Конечно, не все согласны с тем, что приведенные выше результаты доказывают, что OpenAI действительно использует кэшированные ответы.
Их аргументация состоит в том, что случай, принятый автором, оказывается шуткой.
В конце концов, в июне этого года два немецких ученых провели тестирование и обнаружили, что 90% из 1008 результатов ChatGPT, рассказывающих случайную шутку, были вариациями тех же 25 шуток.
 В частности, чаще всего встречается «ученые и атомы» — 119 раз.
В частности, чаще всего встречается «ученые и атомы» — 119 раз.
Таким образом, вы можете понять, почему он выглядит так, как будто предыдущий ответ кэшируется.
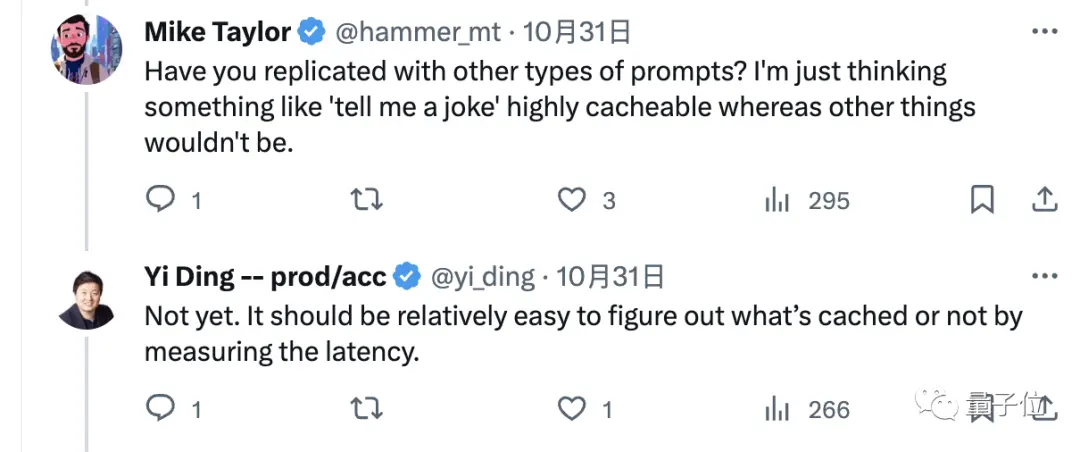
Поэтому некоторые пользователи сети также предложили использовать другие типы вопросов, чтобы проверить, а затем посмотреть.
Тем не менее, авторы настаивают на том, что это не должно быть проблемой, и что легко определить, кэширован ли он, просто измерив задержку.
 Наконец, давайте посмотрим на этот вопрос с «другой стороны»:
Наконец, давайте посмотрим на этот вопрос с «другой стороны»:
Что плохого в том, что GPT-4 все время рассказывает анекдот?
Разве мы не всегда подчеркивали необходимость больших моделей для получения непротиворечивых и надежных ответов? Нет, насколько она послушна (ручная собачья голова).
 Итак, есть ли у GPT-4 кэши или нет, и наблюдали ли вы что-то подобное?
Итак, есть ли у GPT-4 кэши или нет, и наблюдали ли вы что-то подобное?
Ссылки: