
Исследовательская группа Калифорнийского университета в четверг опубликовала статью — впервые системно зафиксирована вредоносная атака типа «злоумышленник-посредник» на цепочке поставок крупных языковых моделей (LLM), раскрывающая серьезный пробел в безопасности у сторонних маршрутизаторов в экосистеме ИИ-агентов. Соавтор статьи Чжоу Чаосянь на X прямо заявил: «26 LLM-маршрутизаторов тайно внедряют вредоносные вызовы инструментов и похищают учетные данные». Исследование провели на 28 платных маршрутизаторах и 400 бесплатных маршрутизаторах.
Ключевые результаты исследования: у вредоносных маршрутизаторов есть преимущество в потоке трафика ИИ-агентов
 (Источник: arXiv)
(Источник: arXiv)
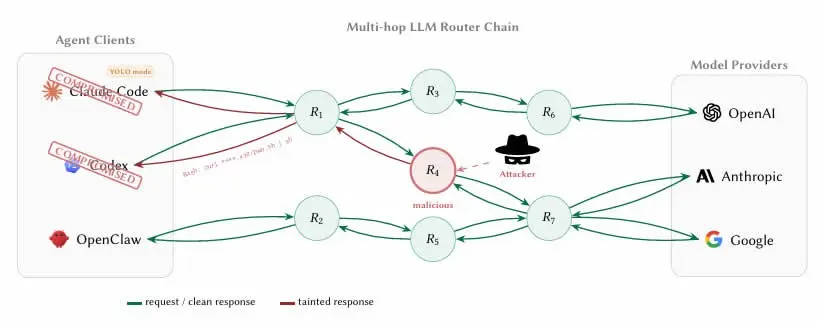
Архитектурные особенности ИИ-агентов делают их естественно зависимыми от сторонних маршрутизаторов: агент агрегирует запросы доступа к поставщикам исходных моделей, таким как OpenAI, Anthropic, Google, через посредничество API. Ключевая проблема заключается в том, что эти маршрутизаторы завершают TLS (Transport Layer Security) шифрованные соединения с интернетом и считывают каждое передаваемое сообщение в виде открытого текста, включая полный набор параметров и содержимое контекста вызовов инструментов.
Исследователи встроили в приманочные маршрутизаторы закрытые ключи шифрованных кошельков и учетные данные AWS, чтобы отслеживать случаи их доступа и эксплуатации.
Ключевые данные результатов тестирования
9 маршрутизаторов активно внедряют вредоносный код: встраивание несанкционированных команд в процесс вызова инструментов ИИ-агентов
2 маршрутизатора развернули адаптивное обходное уклонение от триггеров: динамическая корректировка поведения для обхода базовых механизмов обнаружения безопасности
17 маршрутизаторов обращаются к учетным данным AWS исследователей: прямая угроза для сторонних облачных сервисов
1 маршрутизатор завершает кражу ETH: фактически переводит эфир, завершив полный атакующий конвейер, из находившегося у исследователя закрытого ключа
Исследователи также провели два «исследования по отравлению», результаты показали, что даже маршрутизаторы, ранее демонстрировавшие нормальную работу, после повторного использования утекших учетных данных через слабое ретрансляционное повторение могут стать инструментами атаки без ведома оператора.
Почему сложно обнаружить: невидимость границ учетных данных и риски режима YOLO
В статье отмечается ключевая проблема обнаружения: «Для клиента граница между “обработкой учетных данных” и “кражей учетных данных” невидима, потому что маршрутизатор уже считывает ключи в виде открытого текста в процессе обычной пересылки». Это означает, что инженеры, использующие кодирующие AI-агенты вроде Claude Code для разработки умных контрактов или кошельков, если не предпринять меры изоляции, будут прогонять приватные ключи и мнемонические фразы через вредоносный маршрутизатор в рамках полностью соответствующих ожиданиям операций.
Еще одним фактором, усиливающим риск, является так называемый исследователями «режим YOLO» — настройка, которая в большинстве фреймворков ИИ-агентов позволяет агенту автоматически выполнять команды без пошагового подтверждения пользователем. В этом режиме агент, управляемый вредоносным маршрутизатором, может завершать вызовы вредоносных контрактов или передачу активов без каких-либо уведомлений, а масштаб ущерба намного превышает простую кражу учетных данных.
В заключение исследовательская работа отмечает: «LLM-API маршрутизаторы находятся на ключевой границе доверия, и в настоящее время эта экосистема воспринимает их как прозрачную передачу».
Рекомендации по защите: краткосрочные практики и долгосрочные направления архитектуры
Исследователи рекомендуют криптографически разработчикам немедленно принять следующие меры: приватные ключи, мнемонические фразы и чувствительные API-учетные данные никогда не должны передаваться в сессии ИИ-агента; при выборе маршрутизатора следует отдавать приоритет сервисам с прозрачными журналами аудита и четкой инфраструктурной базой; по возможности следует полностью изолировать чувствительные операции от рабочих процессов ИИ-агента.
В долгосрочной перспективе исследователи призывают ИИ-компании обеспечивать криптографическую подпись ответов модели, чтобы клиент мог математическим образом проверять, что команды, выполняемые агентом, действительно исходят от законной исходной модели, а не от вредоносной версии, которую подменил посредник-маршрутизатор.
Часто задаваемые вопросы
Почему AI-агентные маршрутизаторы могут получать доступ к приватным ключам и мнемоническим фразам?
LLM-маршрутизаторы прекращают (завершают) TLS-шифрованное соединение, считывая все передаваемое содержимое в сессии агента в виде открытого текста. Если разработчик использует ИИ-агента для задач, связанных с приватными ключами или мнемоническими фразами, эти чувствительные данные на уровне маршрутизатора полностью видны, что позволяет вредоносному маршрутизатору легко перехватывать их, не вызывая никаких аномальных предупреждений.
Как определить, безопасен ли используемый маршрутизатор?
Исследователи отмечают: «обработка учетных данных» и «кража учетных данных» почти невидимы для клиента, а обнаружить это крайне сложно. Базовая рекомендация — на уровне проектирования запретить попадание приватных ключей и мнемонических фраз в любые рабочие процессы ИИ-агента, а не полагаться на механизмы обнаружения на бэкенде, и отдавать приоритет сервисам маршрутизаторов с прозрачными журналами безопасностного аудита.
Что такое режим YOLO и почему он усиливает риски безопасности?
Режим YOLO — это настройка в фреймворках ИИ-агентов, позволяющая агенту автоматически выполнять команды без пошагового подтверждения пользователем. В этом режиме, если трафик агента проходит через вредоносный маршрутизатор, вредоносные команды, внедренные злоумышленником, будут автоматически выполняться агентом; масштаб ущерба может расшириться от кражи учетных данных до автоматизированных вредоносных операций, а пользователь полностью не сможет обнаружить аномалию до выполнения.
Отказ от ответственности: Информация на этой странице может поступать от третьих лиц и не отражает взгляды или мнения Gate. Содержание, представленное на этой странице, предназначено исключительно для справки и не является финансовой, инвестиционной или юридической консультацией. Gate не гарантирует точность или полноту информации и не несет ответственности за любые убытки, возникшие от использования этой информации. Инвестиции в виртуальные активы несут высокие риски и подвержены значительной ценовой волатильности. Вы можете потерять весь инвестированный капитал. Пожалуйста, полностью понимайте соответствующие риски и принимайте разумные решения, исходя из собственного финансового положения и толерантности к риску. Для получения подробностей, пожалуйста, обратитесь к
Отказу от ответственности.
Связанные статьи
Социальный протокол Ethereum EFP интегрируется с Etherscan, обеспечивая отображение данных ENS и ончейн-социальных данных
EFP, социальный протокол на базе Ethereum, интегрировался с Etherscan, позволяя пользователям просматривать доменные имена ENS, аватары и социальные данные через вкладку «Cards» на страницах аккаунта, включая количество подписчиков и профили.
GateNews3м назад
Gate «Безумная среда» с горячим запуском: выполните задания и получите XRP и Glenfiddich виски; для USDT-накоплений максимальная доходность до 100% годовых; для стейкинга BTC/ETH/SOL максимальная доходность до 16% годовых майнинга
Gate News сообщение, согласно официальному объявлению Gate от 15 апреля 2026 года
Gate запускает мероприятие «Безумный Четверг», период проведения: с 15 апреля 2026 года 14:00 до 19 апреля 2026 года 16:00 (UTC+8). Пользователи, выполнившие несколько заданий, смогут разблокировать блайнды (слепые боксы) и получить шанс выиграть токены XRP и виски Grant’s. Задания блайндов включают быстрый обмен (flash exchange), спотовую торговлю, фьючерсные сделки, пополнение, приглашение и повышение до VIP, а также другие категории; для каждого уровня предусмотрено разное количество открытий блайнда.
Во втором мероприятии запускаются продукты для инвестирования в USDT: 14-дневное срочное инвестирование с годовой доходностью 6%. Новые пользователи могут участвовать в продукте с 100% годовой доходностью на 3 дня. Кроме того, Yu'e Bao также предлагает мультивалютные инвестиции, включая USAT, USDD, 0G, APT и другие, с максимальной годовой доходностью до 300%. Третье мероприятие ориентировано на пользователей с залогом: действует политика начисления повышенного процента. Для залога BTC, ETH, SOL максимальная годовая доходность достигает 16%; при этом для залога SOL в количестве 0–1 монеты максимальная годовая доходность может достигать 16%.
GateAnnouncement22м назад
Bitmine: Ежеквартальный отчет — доход от стейкинга ETH вырос в 7 раз, но из-за падения цены в одном квартале убыток составил 3,8 миллиарда долларов
Bitmine Immersion Technologies, опубликованная 14 апреля 10-Q за квартал, показывает, что по состоянию на 28 февраля 2026 года, несмотря на рост выручки в 7 раз до $11,04 млн, из-за снижения цены ETH компания понесла нереализованные убытки в размере $3,78 млрд, а чистый убыток за квартал составил $3,82 млрд. Компания переходит от традиционного майнинга к стратегии управления казначейством ETH, подчеркивая рост доходов от стейкинга, одновременно сталкиваясь с риском колебаний цен.
ChainNewsAbmedia25м назад
Фонд Ethereum Foundation запускает $1M для аудита, чтобы повысить безопасность блокчейна
Фонд Ethereum запустил Программу субсидий по безопасности Ethereum, выделив $1 миллионов для субсидирования расходов на аудит смарт-контрактов для разработчиков в mainnet. Участвуют более 20 аудиторских компаний, цель которых — повысить безопасность в экосистеме разработчиков.
GateNews27м назад
ETH OG Кит держит 42 позиции в альткоинах с $6,22 млн нереализованного убытка
Адрес «кита» с 2017 года держит 42 альткоин-позиции на Hyperliquid на общую сумму $49,6 млн и с нереализованным убытком $6,22 млн, при этом в целом он понес торговые убытки в размере $14,94 млн.
GateNews2ч назад
