Original source: New Zhiyuan
 Image source: Generated by Unbounded AI
Image source: Generated by Unbounded AI
Some time ago, Google DeepMind proposed a new “Step-Backing” method, which directly made the technology brain-opening.
To put it simply, it is to let the large language model abstract the problem by itself, obtain a higher-dimensional concept or principle, and then use the abstract knowledge as a tool to reason and derive the answer to the problem.
 Address:
Address:
The results were also very good, as they experimented with the PaLM-2L model and proved that this new technique performed very well in handling certain tasks and problems.
For example, MMLU has a 7% improvement in physical and chemical performance, a 27% improvement in TimeQA, and a 7% improvement in MuSiQue.
Among them, MMLU is a large-scale multi-task language understanding test dataset, TimeOA is a time-sensitive question test dataset, and MusiQue is a multi-hop Q&A dataset containing 25,000 2-to-4-hop questions.
Among them, a multi-hop problem refers to a question that can only be answered by using a multi-hop inference path formed by multiple triples.
Below, let’s take a look at how this technology is implemented.
Back off!
After reading the introduction at the beginning, readers may not understand it too much. What does it mean for LLMs to abstract the problem themselves and get a higher-dimensional concept or principle?
Let’s take a specific example.
For example, if the user wants to ask a question related to “force” in physics, then the LLM can step back to the level of the basic definition and principle of force when answering such a question, which can be used as a basis for further reasoning about the answer.
Based on this idea, when the user first enters, it is roughly like this:
You are now an expert in world knowledge, adept at thinking carefully and answering questions step by step with a backward questioning strategy.
Stepping back is a thinking strategy to understand and analyze a particular problem or situation from a more macro, fundamental perspective. Thus better answering the original question.
Of course, the physics example given above illustrates only one case. In some cases, the back-down strategy may allow the LLM to try to identify the scope and context of the problem. Some problems retreat a little more, and some fall less.
Thesis
First, the researchers point out that the field of natural language processing (NLP) has ushered in a breakthrough revolution with Transformer-based LLMs.
The expansion of model size and the increase of pre-trained corpus have brought significant improvements in model capabilities and sampling efficiency, as well as emerging capabilities such as multi-step inference and instruction following.
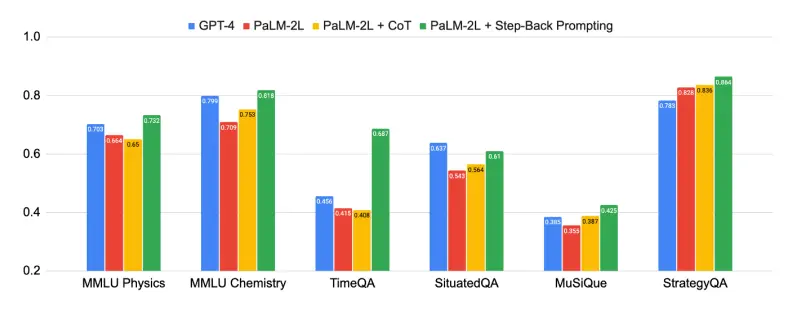 The figure above shows the power of backward reasoning, and the “abstract-reasoning” method proposed in this paper has made significant improvements in a variety of difficult tasks that require complex reasoning, such as science, technology, engineering and mathematics, and multi-hop reasoning.
The figure above shows the power of backward reasoning, and the “abstract-reasoning” method proposed in this paper has made significant improvements in a variety of difficult tasks that require complex reasoning, such as science, technology, engineering and mathematics, and multi-hop reasoning.
Some tasks were very challenging, and at first, PaLM-2L and GPT-4 were only 40% accurate on TimeQA and MuSiQue. After applying backward reasoning, the performance of PaLM-2L has improved across the board. It improved by 7% and 11% in MMLU physics and chemistry, 27% in TimeQA, and 7% in MuSiQue.
Not only that, but the researchers also conducted error analysis, and they found that most of the errors that occur when applying backward reasoning are due to the inherent limitations of LLMs’ inference ability, and are not related to new technologies.
Abstraction is easier for LLMs to learn, so it points the way to the further development of backward reasoning.
While progress has been made, complex multi-step reasoning can be challenging. This is true even for the most advanced LLMs.
This paper shows that process supervision with step-by-step verification function is an effective remedy to improve the correctness of intermediate reasoning steps.
They introduced techniques such as Chain-of-Thought prompts to generate a coherent series of intermediate inference steps, increasing the success rate of following the correct decoding path.
When talking about the origin of this PROMP technology, the researchers pointed out that when faced with challenging tasks, human beings tend to take a step back and abstract, so as to derive high-level concepts and principles to guide the reasoning process.
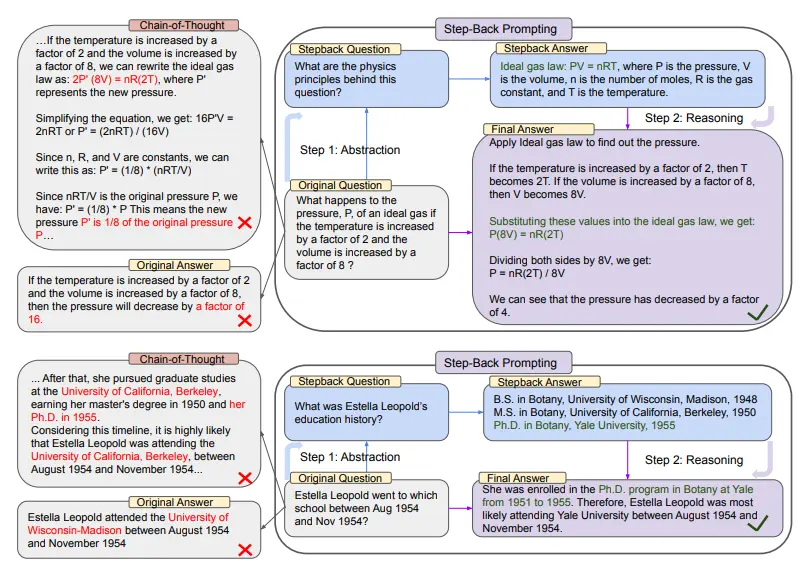 In the upper part of the figure above, taking MMLU’s high school physics as an example, through backward abstraction, LLM obtains the first principle of the ideal gas law.
In the upper part of the figure above, taking MMLU’s high school physics as an example, through backward abstraction, LLM obtains the first principle of the ideal gas law.
In the second half, there is an example from TimeQA, where the high-level concept of the history of education is the result of LLM abstraction based on this strategy.
From the left side of the entire diagram we can see that PaLM-2L was unsuccessful in answering the original question. The chain of thought indicates that in the middle of the reasoning step, the LLM made an error (highlighted in red).
And on the right, the PaLM-2L, with the application of the backward technology, successfully answered the question.
Among the many cognitive skills, abstract thinking is ubiquitous for the human ability to process large amounts of information and derive general rules and principles.
To name a few, Kepler distilled thousands of measurements into Kepler’s Three Laws of Planetary Motion, which accurately describe the orbits of planets around the sun.
Or, in critical decision-making, humans also find abstraction helpful because it provides a broader view of the environment.
The focus of this paper is how LLMs can handle complex tasks involving many low-level details through a two-step approach of abstraction and reasoning.
The first step is to teach LLMs to take a step back and derive high-level, abstract concepts from concrete examples, such as foundational concepts and first principles within a domain.
The second step is to use reasoning skills to base the solution on high-level concepts and first principles.
The researchers used a small number of examples on LLMs to perform backward inference. They experimented in a series of tasks involving domain-specific reasoning, knowledge-intensive problem-solving, multi-hop common-sense reasoning that required factual knowledge.
The results show that the performance of PaLM-2L is significantly improved (up to 27%), which proves that backward inference is very effective in dealing with complex tasks.
During the experiments, the researchers experimented with the following different kinds of tasks:
(1)STEM
(2) Knowledge QA
(3) Multi-hop reasoning
The researchers evaluated the application in STEM tasks to measure the effectiveness of the new approach in reasoning in highly specialized fields. (This article will only cover such questions)
Obviously, the problem in the MMLU benchmark requires deeper reasoning on the part of the LLM. In addition, they require the understanding and application of formulas, which are often physical and chemical principles and concepts.
In this case, the researcher first teaches the model to be abstracted in the form of concepts and first principles, such as Newton’s first law of motion, the Doppler effect, and Gibbs free energy. The step-back question implicit here is, “What are the physical or chemical principles and concepts involved in solving this task?”
The team provided demonstrations that taught the model to memorize the principles of task-solving from their own knowledge.
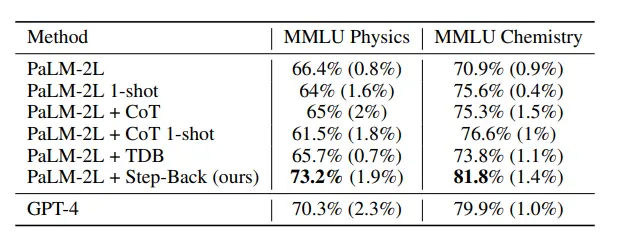 The above table shows the performance of the model using the backward inference technique, and the LLM with the new technology performed well in STEM tasks, reaching the most advanced level beyond GPT-4.
The above table shows the performance of the model using the backward inference technique, and the LLM with the new technology performed well in STEM tasks, reaching the most advanced level beyond GPT-4.
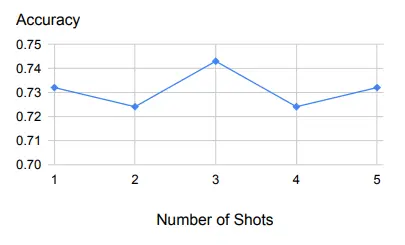 The table above is an example of a small number of samples and demonstrates robust performance with varying sample sizes.
The table above is an example of a small number of samples and demonstrates robust performance with varying sample sizes.
First, as we can see from the graph above, backward inference is very robust to a small number of examples used as demonstrations.
In addition to one example, the same will be true for adding more examples.
This suggests that the task of retrieving relevant principles and concepts is relatively easy to learn, and a demonstration example is sufficient.
Of course, in the course of the experiment, there will still be some problems.
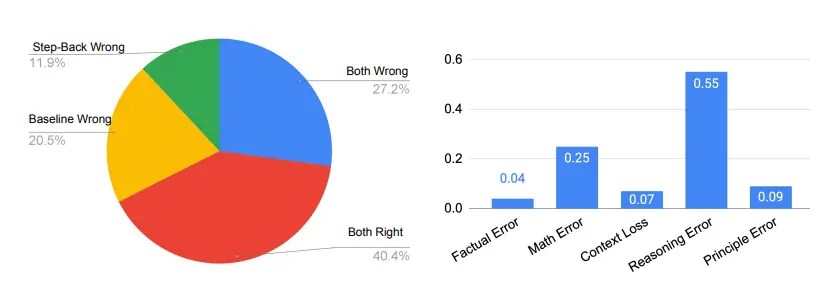
The five types of errors that occur in all papers, except for principle errors, occur in the reasoning step of the LLM, while principle errors indicate the failure of the abstraction step.
As you can see on the right side of the figure below, principle errors actually account for only a small fraction of model errors, with more than 90% of errors occurring in the inference step. Of the four types of errors in the reasoning process, reasoning errors and mathematical errors are the main places where mistakes are located.
This is in line with the findings in ablation studies that only a few examples are needed to teach LLMs how to abstract. The inference step is still a bottleneck for backward inference to complete tasks that require complex inference, such as MMLU.
This is especially true for MMLU Physics, where reasoning and math skills are key to successful problem-solving. This means that even if the LLM retrieves the first principles correctly, it still has to go through a typical multi-step reasoning process to arrive at the correct final answer, which requires the LLM to have deep reasoning and mathematical skills.
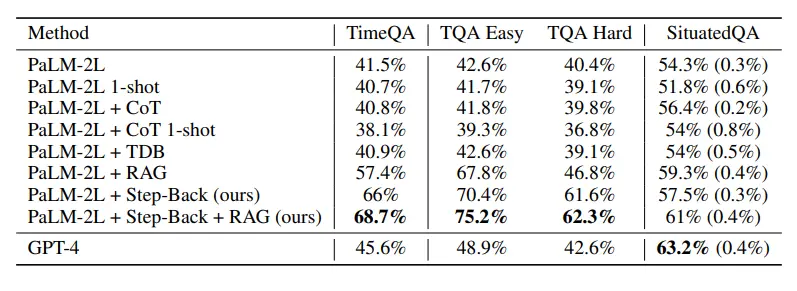
 The researchers then evaluated the model on TimeQA’s test set.
The researchers then evaluated the model on TimeQA’s test set.
As shown in the figure below, the baseline models of GPT-4 and PaLM-2L reached 45.6% and 41.5%, respectively, highlighting the difficulty of the task.
CoT or TDB was applied zero times (and once) on the baseline model without any improvement.
In contrast, the accuracy of the baseline model enhanced by regular retrieval augmentation (RAG) increased to 57.4%, highlighting the fact-intensive nature of the task.
The results of Step-Back + RAG show that the LLM back to the advanced concepts step is very effective in backward inference, which makes the LLM retrieval link more reliable, and we can see that TimeQA has an astonishing 68.7% accuracy.
Next, the researchers divided TimeQA into two difficulty levels: easy and difficult provided in the original dataset.
Not surprisingly, LLMs all perform poorly at the difficult level. While RAG was able to increase accuracy from 42.6% to 67.8% at the easy level, the improvement was much smaller for the hard level, with data showing only an increase from 40.4% to 46.8%.
And this is where the technique of backward reasoning comes in, as it retrieves facts about higher-level concepts and lays the foundation for final reasoning.
Backward reasoning plus RAG further improved the accuracy to 62.3%, surpassing GPT-4’s 42.6%.
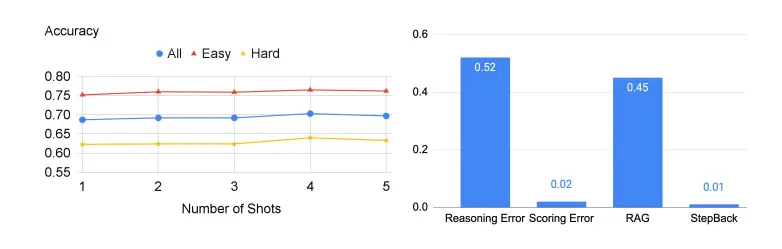
 Of course, there are still some problems with this technology when it comes to TimeQA.
Of course, there are still some problems with this technology when it comes to TimeQA.
The figure below shows the accuracy of the LLM in this part of the experiment, and the probability of error occurring on the right.
 Resources:
Resources: