
Група дослідників Каліфорнійського університету опублікувала в четвер роботу, що вперше системно описує атаки з боку зловмисників типу “man-in-the-middle” у ланцюжку постачання для великих мовних моделей (LLM), розкриваючи суттєву прогалину в безпеці третіхсторонніх роутерів в екосистемі AI-агентів. Співавтор роботи Шоу Чаофань (壽超凡) прямо заявив у X: «26 LLM-роутерів таємно впроваджують зловмисні виклики інструментів і викрадають облікові дані». Дослідження провели тестування 28 платних роутерів і 400 безкоштовних роутерів.
Ключові результати дослідження: перевага зловорожних роутерів у трафіку AI-агентів
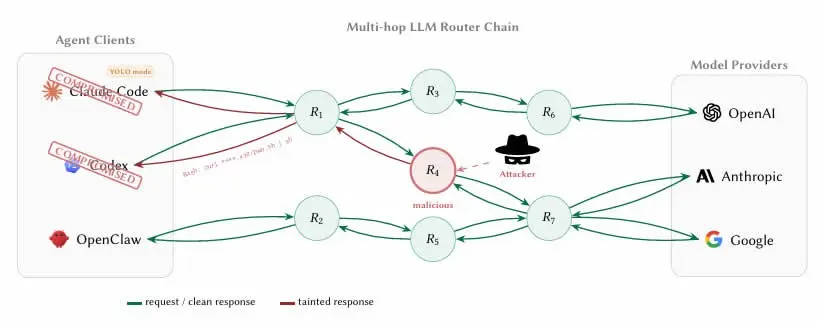 (Джерело: arXiv)
(Джерело: arXiv)
Особливості архітектури AI-агентів роблять їх природно залежними від роутерів сторонніх осіб: агент через API-інтерфейс посередницьки агрегує запити на доступ до постачальників верхнього рівня моделей, таких як OpenAI, Anthropic, Google тощо. Ключова проблема в тому, що ці роутери завершують TLS (Transport Layer Security) шифровані з’єднання з інтернетом і зчитують кожне повідомлення передавання у вигляді відкритого тексту, включно з повними параметрами викликів інструментів та вмістом контексту.
Дослідники вбудували в приманкові роутери шифровані приватні ключі гаманця та сертифікати AWS, відстежуючи випадки їх доступу й використання.
Ключові дані результатів тестування
9 роутерів активно впроваджують зловмисний код: вбудовування несанкціонованих інструкцій у процес викликів інструментів AI-агентів
2 роутери розгортають адаптивне обходження тригерів: динамічне коригування поведінки для обходу базових механізмів виявлення безпеки
17 роутерів отримують доступ до AWS-облікових даних дослідників: прямий ризик для сторонніх хмарних сервісів
1 роутер завершує ETH-викрадення: фактично переказує Ethereum із приватного ключа, який мав у своєму розпорядженні дослідник, завершуючи повний ланцюжок атаки
Дослідники паралельно провели два «дослідження отруєння» (пойзонінгу), і результати показали, що навіть роутери, які раніше демонстрували нормальну роботу, після повторного використання витікаючих облікових даних, що стали доступними через слабкі посередницькі (relay) повтори, можуть без відома провайдера стати інструментами для атак.
Чому це важко виявити: невидимість межі облікових даних і ризик режиму YOLO
У роботі зазначено ключову складність виявлення: «для клієнта межа між “обробкою облікових даних” та “викраденням облікових даних” є невидимою, оскільки роутер під час звичайного пересилання вже зчитує ключі у вигляді відкритого тексту». Це означає, що інженери, які розробляють смартконтракти або гаманці за допомогою AI-кодувальних агентів на кшталт Claude Code, якщо не вжити ізоляційних заходів, матимуть приватні ключі та seed-фрази в потоці через зловмисний роутер у рамках абсолютно очікуваних операційних процесів.
Ще один фактор, що додатково посилює ризик, — це описаний дослідниками «режим YOLO», який у більшості фреймворків AI-агентів дозволяє агенту автоматично виконувати інструкції без покрокового підтвердження з боку користувача. У цьому режимі агент, яким керує зловмисний роутер, може без будь-яких підказок завершити виклик зловмисного смартконтракту або переказ активів; масштаб шкоди виходить далеко за межі простого викрадення облікових даних.
У підсумку стаття формулює так: «LLM API-роутер розташований на ключовій межі довіри, а в цій екосистемі його нині розглядають як прозору передачу».
Рекомендації щодо захисту: короткострокові практики та довгостроковий напрям архітектури
Дослідники радять негайно криптографічним способом для розробників вжити такі заходи: приватні ключі, seed-фрази та чутливі API-облікові дані ніколи не повинні передаватися в сесіях AI-агентів; обираючи роутер, надавати пріоритет сервісам із прозорими аудит-логами та чіткою інфраструктурною базою; якщо можливо, повністю ізолювати чутливі операції від робочого процесу AI-агентів.
У довшу перспективу дослідники закликають компанії, що створюють моделі, підписувати криптографічно відповіді моделей, щоб клієнти могли математично перевірити, що інструкції, які виконав агент, справді походять із законних верхньорівневих моделей, а не з підроблених зловорожних версій, змінених проміжними роутерами.
Поширені запитання
Чому роутери для AI-агентів можуть отримувати доступ до приватних ключів і seed-фраз?
LLM-роутери припиняють (terminate) TLS-шифроване з’єднання та зчитують усі передаванні в сесії агента у вигляді відкритого тексту. Якщо розробники використовують AI-агента для задач, що стосуються приватних ключів або seed-фраз, ці чутливі дані на рівні роутера є повністю видимими, що дозволяє зловорожному роутеру легко перехоплювати їх і не викликати жодних аномальних сповіщень.
Як визначити, чи безпечний роутер, який використовується?
Дослідники вказують, що «обробка облікових даних» і «викрадення облікових даних» для клієнта майже невидимі, тож виявлення є вкрай складним. Базова рекомендація — на рівні проєктування заборонити приватним ключам і seed-фразам потрапляти в будь-які робочі процеси AI-агентів, а не покладатися на механізми виявлення на бекенді, і надавати пріоритет роутерам/сервісам із прозорими аудит-логами безпеки.
Що таке режим YOLO і чому він підвищує ризики безпеки?
Режим YOLO — це налаштування у фреймворках AI-агентів, яке дозволяє агенту автоматично виконувати інструкції без покрокового підтвердження з боку користувача. У цьому режимі, якщо трафік агента проходить через зловмисний роутер, зловмисні інструкції, які ввів атакувальник, виконуватимуться агентом автоматично, а шкода може розширитися від викрадення облікових даних до автоматизованих зловмисних дій. Користувач повністю не може помітити аномалії перед виконанням.
Застереження: Інформація на цій сторінці може походити від третіх осіб і не відображає погляди або думки Gate. Вміст, що відображається на цій сторінці, є лише довідковим і не є фінансовою, інвестиційною або юридичною порадою. Gate не гарантує точність або повноту інформації і не несе відповідальності за будь-які збитки, що виникли в результаті використання цієї інформації. Інвестиції у віртуальні активи пов'язані з високим ризиком і піддаються значній ціновій волатильності. Ви можете втратити весь вкладений капітал. Будь ласка, повністю усвідомлюйте відповідні ризики та приймайте обережні рішення, виходячи з вашого фінансового становища та толерантності до ризику. Для отримання детальної інформації, будь ласка, зверніться до
Застереження.

