GPT-4變笨加劇,被曝緩存歷史回復:一個笑話講八百遍,讓換新的也不聽
巴比特_
原文來源:量子位
 圖片來源:由無界 AI生成
圖片來源:由無界 AI生成
有網友找到了**GPT-4變“笨”**的又一證據。
他質疑:
OpenAI會緩存歷史回復,讓GPT-4直接複述以前生成過的答案。
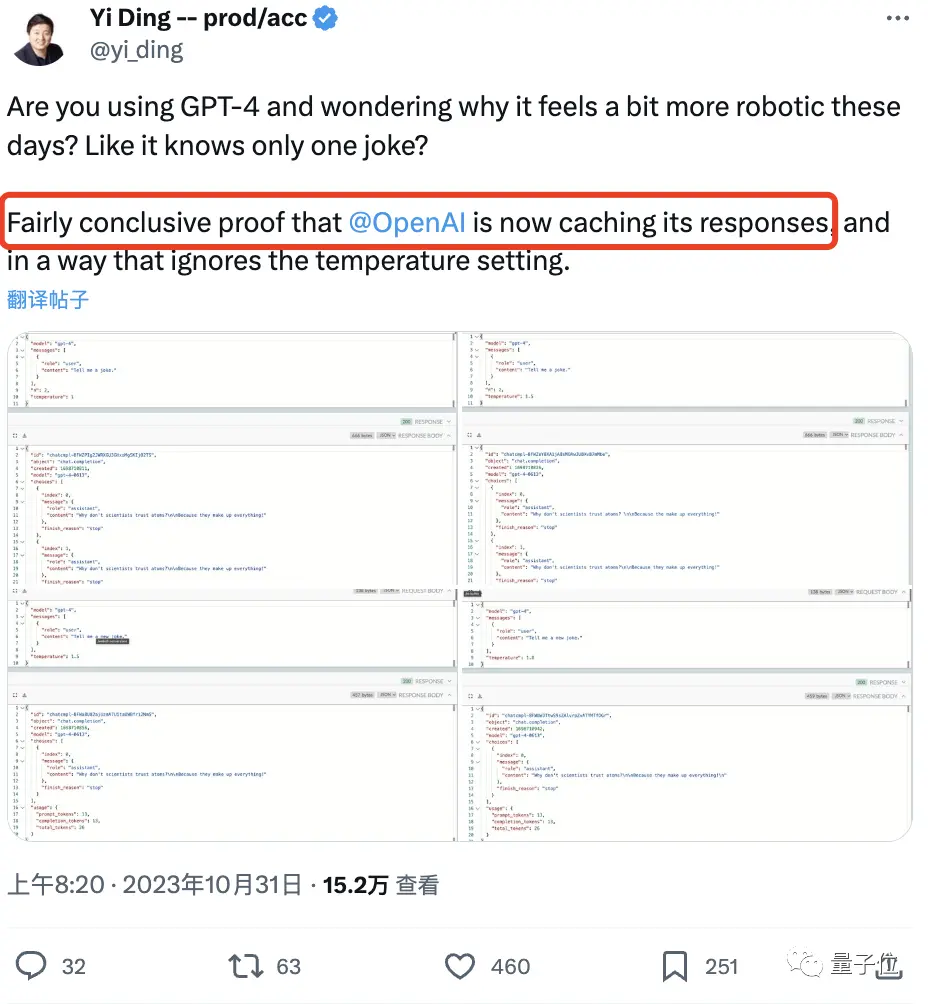 最明顯的例子就是講笑話。
最明顯的例子就是講笑話。
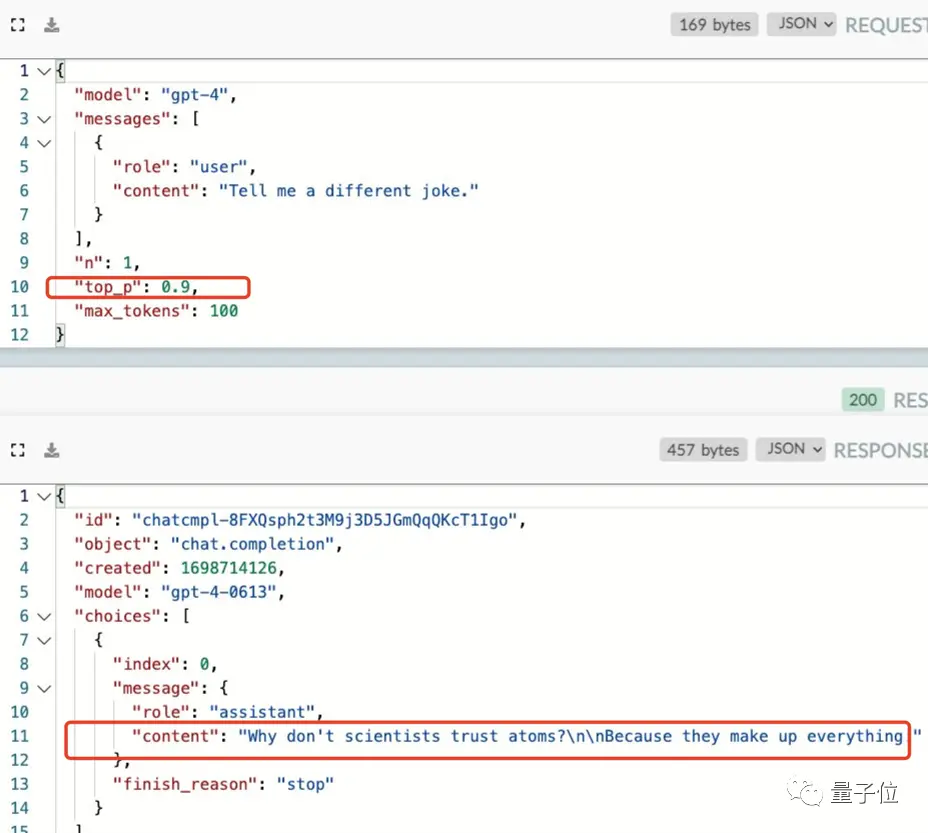
證據顯示,即使他將模型的temperature值調高,GPT-4仍重複同一個**“科學家與原子”**的回答。
就是那個「為什麼科學家不信任原子? 因為萬物都是由它們編造/構造(make up)出來的“的冷笑話。
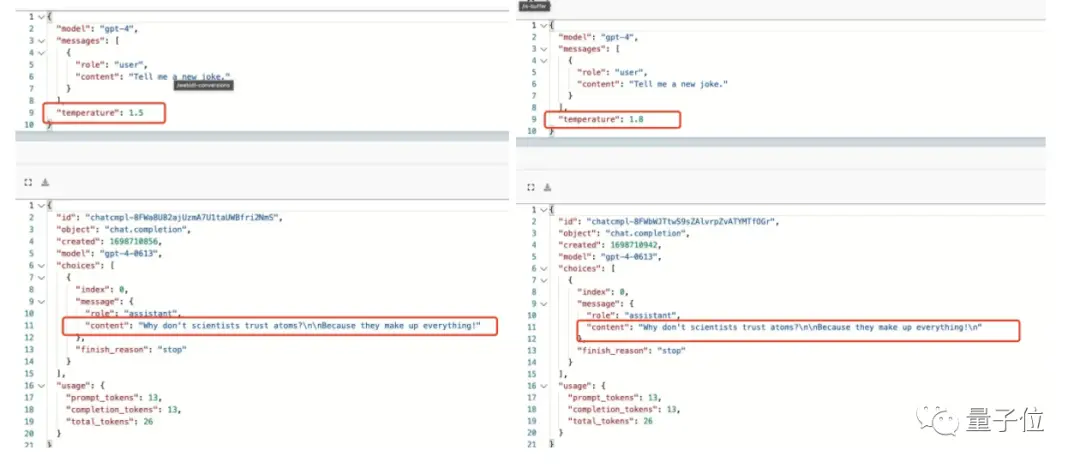 在此,按理說temperature值越大,模型越容易生成一些意想不到的詞,不該重複同一個笑話了。
在此,按理說temperature值越大,模型越容易生成一些意想不到的詞,不該重複同一個笑話了。
不止如此,即使咱們不動參數,換一個措辭,強調讓它講一個新的、不同的笑話,也無濟於事。
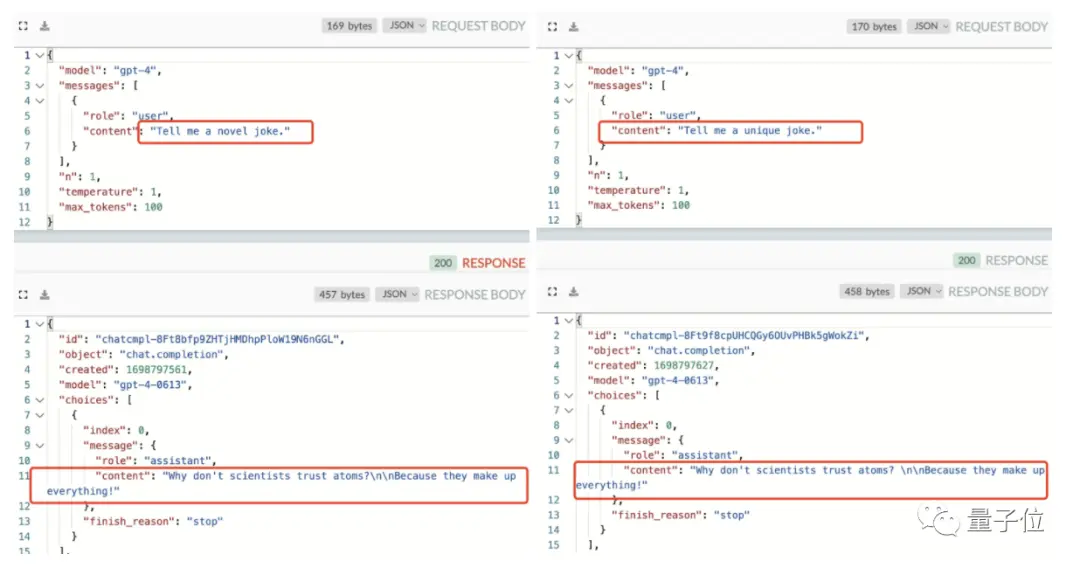 發現者表示:
發現者表示:
這說明GPT-4不僅使用緩存,還是聚類查詢而非精準匹配某個提問。
這樣的好處不言而喻,回復速度可以更快。
不過既然高價買了會員,享受的只是這樣的緩存檢索服務,誰心裡也不爽。
 還有人看完後的心情是:
還有人看完後的心情是:
如果真這樣的話,我們一直用GPT-4來評價其他大模型的回答是不是不太公平?
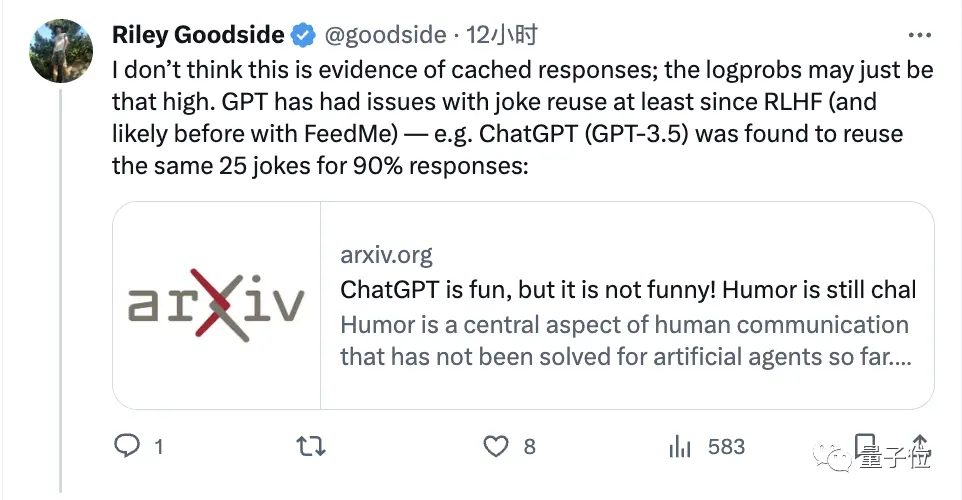
 當然,也有人不認為這是外部緩存的結果,可能模型本身答案的重複性就有這麼高:
當然,也有人不認為這是外部緩存的結果,可能模型本身答案的重複性就有這麼高:
此前已有研究表明ChatGPT在講笑話時,90%的情況下都會重複同樣的25個。
 具體怎麼說?
具體怎麼說?
證據實錘GPT-4用緩存回復
不僅是忽略temperature值,這位網友還發現:
更改模型的top_p值也沒用,GPT-4就跟那一個笑話幹上了。
(top_p:用來控制模型返回結果的真實性,想要更準確和基於事實的答案就把值調低,想要多樣化的答案就調高)
 唯一的破解辦法是把隨機性參數n拉高,這樣我們就可以獲得“非緩存”的答案,得到一個新笑話。
唯一的破解辦法是把隨機性參數n拉高,這樣我們就可以獲得“非緩存”的答案,得到一個新笑話。
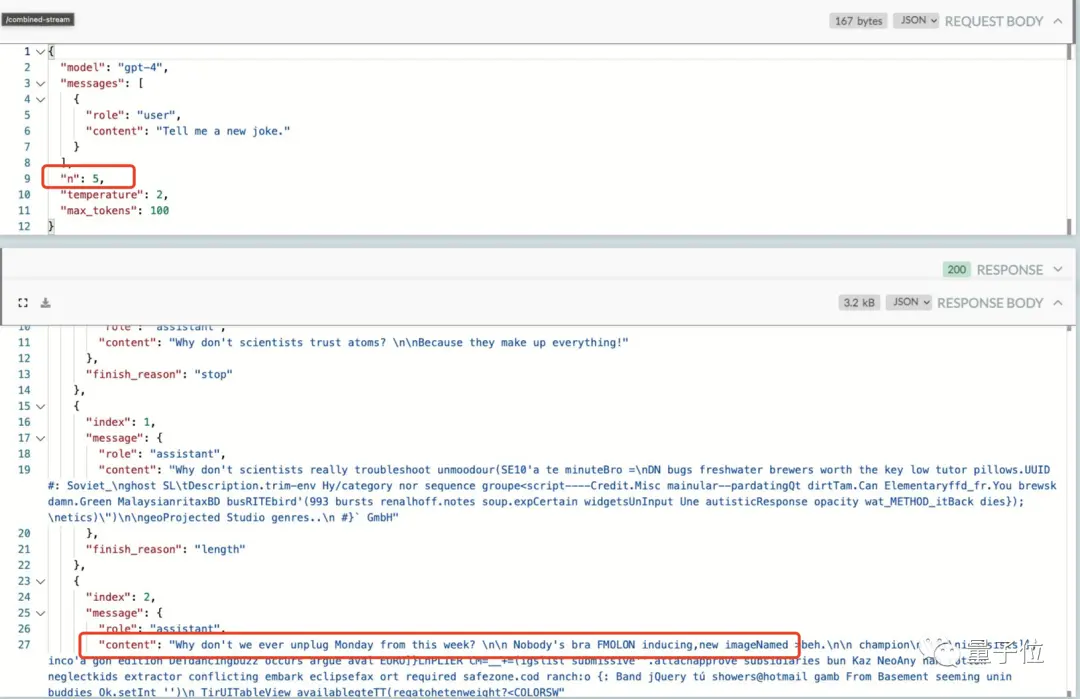 不過,它的“代價”是回復速度變慢,畢竟生成新內容會帶來一定延遲。
不過,它的“代價”是回復速度變慢,畢竟生成新內容會帶來一定延遲。
值得一提的是,還有人似乎在本地模型上也發現了類似現象。

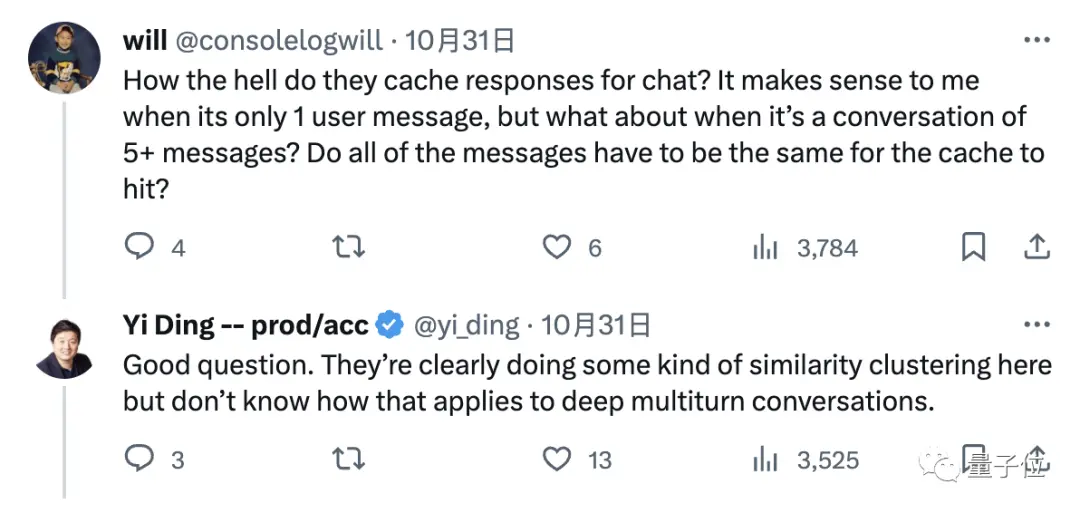
那麼問題就來了,大模型到底是如何緩存我們的聊天資訊的呢?
好問題,從開頭展現的第二個例子來看,顯然是進行了某種“聚類”操作,但具體如何應用於深度多輪對話咱不知道。
 姑且不論這個問題,倒是有人看到這裡,想起來ChatGPT那句“您的數據存在我們這兒,但一旦聊天結束對話內容就會被刪除”的聲明,恍然大悟。
姑且不論這個問題,倒是有人看到這裡,想起來ChatGPT那句“您的數據存在我們這兒,但一旦聊天結束對話內容就會被刪除”的聲明,恍然大悟。
 這不禁讓一些人開始擔憂數據安全問題:
這不禁讓一些人開始擔憂數據安全問題:
這是否意味著我們發起的聊天內容仍然保存在他們的資料庫中?
 當然,有人分析這個擔憂可能過慮了:
當然,有人分析這個擔憂可能過慮了:
也許只是我們的查詢embedding和回答緩存被存下來了。
 因此,就像發現者本人說的:
因此,就像發現者本人說的:
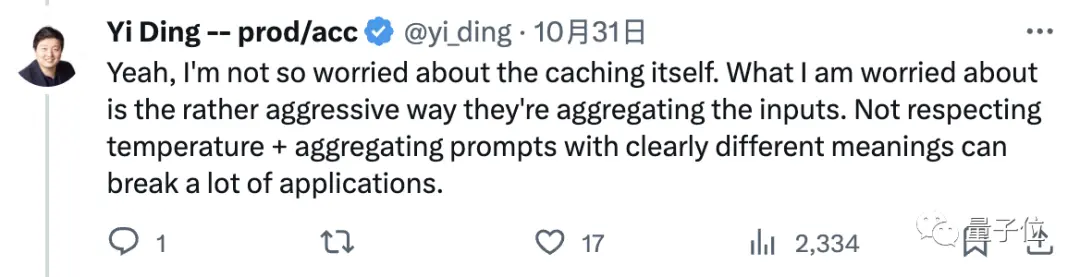
緩存這個操作本身我不太擔心。
我擔心的是OpenAI這樣簡單粗暴地匯總我們的問題進行回答,毫不關心temperature等設置,直接聚合明顯有不同含義的提示,這樣影響很不好,可能“廢掉”許多(基於GPT-4的)應用。
 當然,並不是所有人都同意以上發現能夠證明OpenAI真的就是在用緩存回復。
當然,並不是所有人都同意以上發現能夠證明OpenAI真的就是在用緩存回復。
他們的理由是作者採用的案例恰好是講笑話。
畢竟就在今年6月,兩個德國學者測試發現,讓ChatGPT隨便講個笑話,1008次結果中有90%的情況下都是同樣25個笑話的變體。
 像「科學家和原子」這個更是尤其出現頻率最高,它講了119次。
像「科學家和原子」這個更是尤其出現頻率最高,它講了119次。
因此也就能理解為什麼看起來好像是緩存了之前的回答一樣。
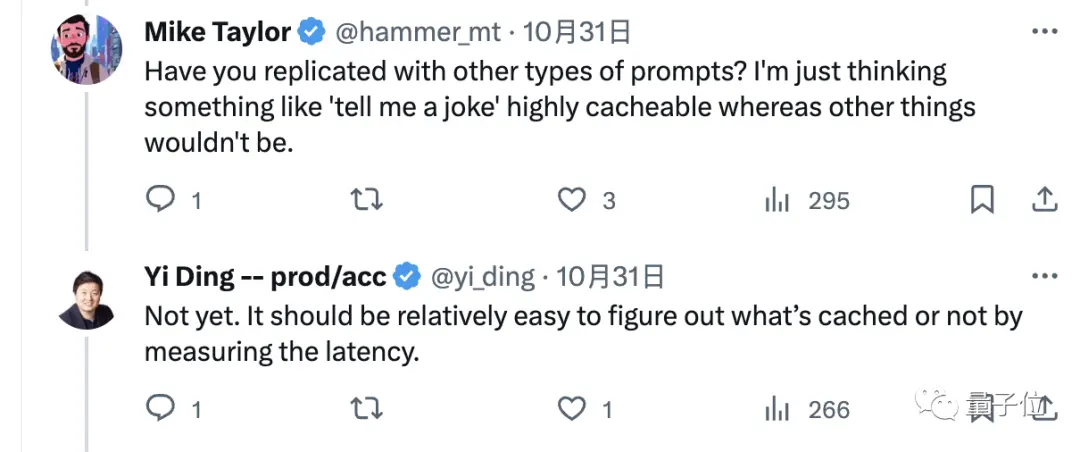
因此,有網友也提議用其他類型的問題測一測再看。
不過作者堅持認為,不一定非得換問題,光通過測量延遲時間就能很容易地分辨出是不是緩存了。
 最後,我們不妨再從「另一個角度」看這個問題:
最後,我們不妨再從「另一個角度」看這個問題:
GPT-4一直講一個笑話怎麼了?
一直以來,咱們不都是強調要讓大模型輸出一致、可靠的回答嗎? 這不,它多聽話啊(手動狗頭)。
 所以,GPT-4究竟有沒有緩存,你有觀察到類似現象嗎?
所以,GPT-4究竟有沒有緩存,你有觀察到類似現象嗎?
參考連結:
免責聲明:本頁面資訊可能來自第三方,不代表 Gate 的觀點或意見。頁面顯示的內容僅供參考,不構成任何財務、投資或法律建議。Gate 對資訊的準確性、完整性不作保證,對因使用本資訊而產生的任何損失不承擔責任。虛擬資產投資屬高風險行為,價格波動劇烈,您可能損失全部投資本金。請充分了解相關風險,並根據自身財務狀況和風險承受能力謹慎決策。具體內容詳見聲明。
留言
0/400
暫無留言