助推谷歌冲击4万亿的TPU,如何在区块链领域大显身手?
PANews
作者:Eli5DeFi
编译:Tim,PANews
PANews编者按:11月25日,谷歌总市值创历史新高,达3.96万亿美元,助推股价的因素除了新发布的最强AI Gemini 3,还有其自研芯片TPU。除了AI领域外,TPU在区块链也将大显身手。
现代计算的硬件叙事基本上是由GPU的崛起所定义的。
从游戏到深度学习,英伟达的并行架构已成为业界公认的标准,使得CPU逐渐转向协管角色。
然而,随着AI模型遭遇规模化瓶颈、区块链技术迈向复杂密码学应用,新的竞争者张量处理器(TPU)已然登场。
尽管TPU常被置于谷歌AI战略的框架下讨论,但它的架构却意外契合区块链技术的下一个里程碑后量子密码学的核心需求。
本文通过梳理硬件演进历程、对比架构特性,阐释为何在构建抗量子攻击的去中心化网络时,TPU(而非GPU)更能胜任后量子密码学所需的密集型数学运算。
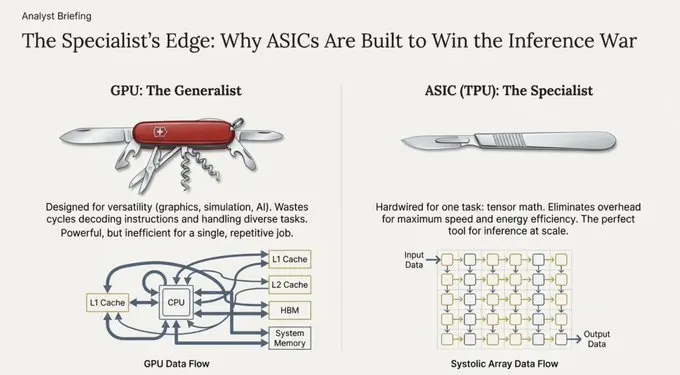
硬件演进:从串行处理到脉动架构
要理解TPU的重要性,就需要先了解它所解决的问题。
- 中央处理器(CPU):作为全能型选手,擅长串行处理与逻辑分支操作,但在需要同时执行海量数学运算时则作用有限。
- 图形处理器(GPU):作为并行处理专家,设计初衷是渲染像素,因而擅长同时执行大量相同任务(SIMD:单指令多数据流)。这一特性使其成为早期人工智能爆发的中流砥柱。
- 张量处理器(TPU):作为专业型芯片,由谷歌专为神经网络计算任务设计。
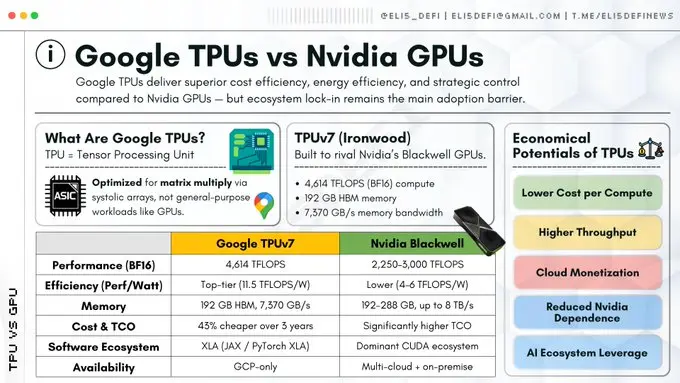
脉动架构优势
GPU与TPU的根本区别在于它们的数据处理方式。
GPU需反复调取内存(寄存器、缓存)进行计算,而TPU采用脉动架构。这种架构如同心脏泵血般,使数据以规律脉动的方式流经大规模计算单元网格。
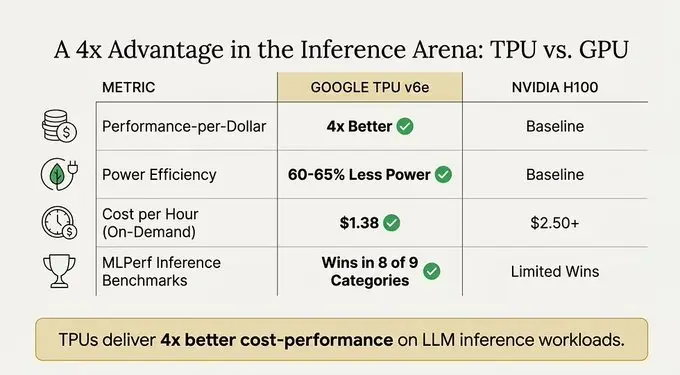
https://www.ainewshub.org/post/ai-inference-costs-tpu-vs-gpu-2025
计算结果直接传递至下一计算单元,无需写回内存。这种设计极大缓解了冯·诺依曼瓶颈,即数据在内存与处理器间反复移动产生的延迟,从而在特定数学运算上实现吞吐量的数量级提升。
后量子密码学的关键:为何区块链需要TPU?
TPU在区块链领域最关键的应用并非挖矿,而是密码学安全。

当前区块链系统依赖的椭圆曲线密码学或RSA加密体系,在应对Shor算法时存在致命弱点。这意味着一旦出现足够强大的量子计算机,攻击者就能从公钥反推出私钥,足以彻底清空比特币或以太坊上的所有加密资产。
解决之道在于后量子密码学。目前主流的PQC标准算法(如Kyber、Dilithium)均基于Lattice密码学构建。
TPU的数学契合性
这正是TPU相较GPU的优势。Lattice密码学严重依赖大型矩阵和向量的密集操作,主要包括:
- 矩阵-向量乘法:As+e(其中 A为矩阵,s和 e为向量)。
- 多项式运算:基于环的代数操作,通常运用数论变换实现。
传统GPU将这些运算视为通用并行任务处理,而TPU则通过硬件层级固化的矩阵计算单元实现专属加速。Lattice密码学的数学结构,与TPU脉动阵列的物理构造几乎形成严丝合缝的拓扑映射。
TPU与GPU的技术博弈
尽管GPU仍是业界通用的万能王者,但在处理特定数学密集型任务时,TPU具有绝对优势。

结论:GPU胜在通用性与生态系统,而TPU则在密集线性代数计算效率上占据优势,而这正是AI与现代先进密码学所依赖的核心数学运算。
TPU拓展叙事:零知识证明与去中心化AI
除后量子密码学外,TPU在Web3另两大关键领域也展现出应用潜力。
零知识证明
ZK-Rollups(如Starknet或zkSync)作为以太坊的扩容方案,其证明生成过程需要完成海量计算,主要包括:
- 快速傅里叶变换:实现数据表示形式的快速转换。
- 多标量乘法:实现椭圆曲线上的点运算组合。
- FRI协议:验证多项式的密码学证明系统
这类运算并非ASIC擅长的哈希计算,而是多项式数学。相较于通用CPU,TPU能显著加速FFT和多项式承诺运算;而由于这类算法具有可预测的数据流特性,TPU通常比GPU能实现更高效率的加速。
随着Bittensor等去中心化AI网络的兴起,网络节点需具备运行AI模型推理的能力。运行通用大语言模型本质上就是在执行海量矩阵乘法运算。
相较于GPU集群,TPU能使去中心化节点以更低能耗处理AI推理请求,从而提升去中心化AI的商业可行性。
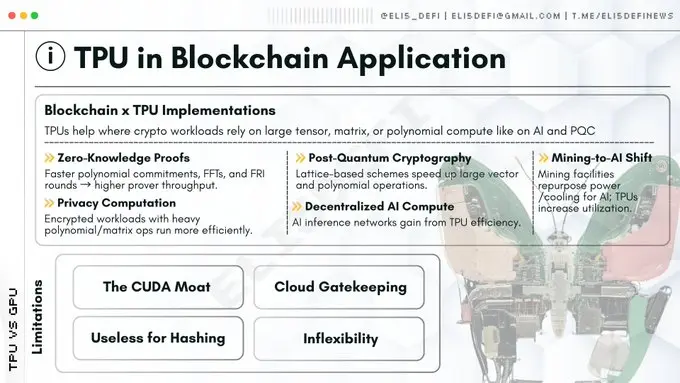
TPU生态版图
尽管当前多数项目因CUDA的普及性仍依赖GPU,但以下领域在TPU集成方面蓄势待发,尤其在后量子密码学与零知识证明的叙事框架下极具发展潜力。
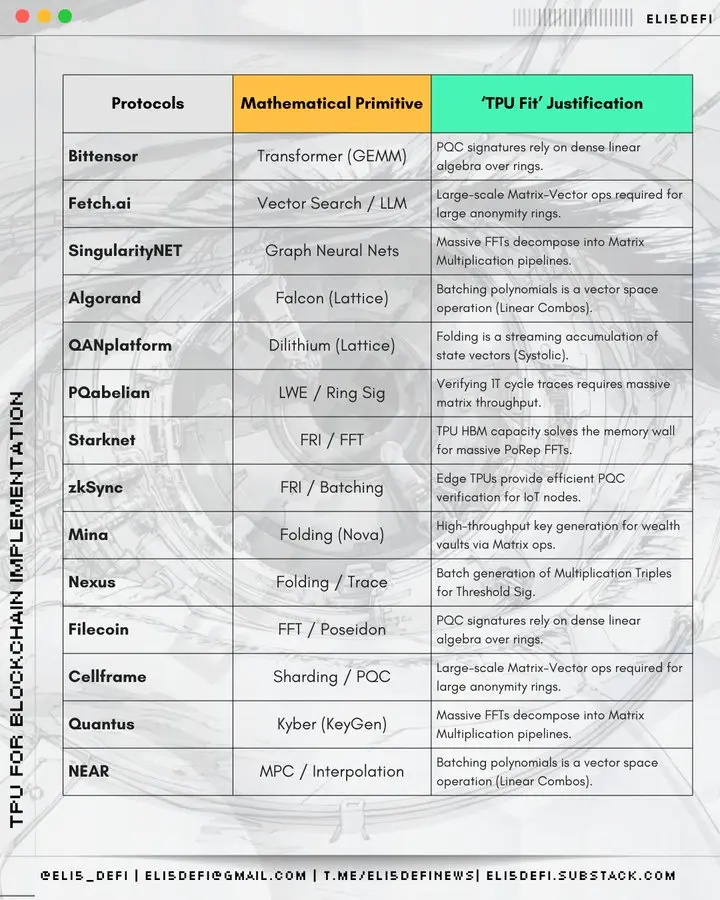
零知识证明与扩容方案
为何选择TPU?因为ZK证明生成需要大规模并行处理多项式运算,而在特定架构配置下,TPU对此类任务的处理效率远超通用GPU。
- Starknet(二层扩容方案):STARK证明严重依赖快速傅里叶变换和快速里德-所罗门交互式预言证明,这些计算密集型操作与TPU的运算逻辑高度契合。
- zksync(二层扩容方案):它的Airbender证明器需处理大规模FFT与多项式运算,这正是TPU能破解的核心瓶颈所在。
- Scroll(二层扩容方案):它采用Halo2与Plonk证明体系,其核心运算KZG承诺验证与多标量乘法能完美匹配TPU的脉动架构。
- Aleo(隐私保护公链):专注于zk-SNARK零知识证明生成,其核心运算依赖的多项式数学特性与TPU的专用计算吞吐量高度契合。
- Mina(轻量级公链):采用递归SNARKs技术,其持续重新生成证明的机制需反复执行多项式运算,这一特性使得TPU的高效计算价值凸显。
- Zcash(隐私币):经典Groth16证明体系依托多项式运算。虽属早期技术,但高吞吐量硬件仍能使其显著获益。
- Filecoin(DePIN、存储):它的复制证明机制通过零知识证明与多项式编码技术,验证存储数据的有效性。
去中心化AI与代理型计算
为何选择TPU?这正是TPU的原生应用场景,专为加速神经网络机器学习任务而设计。
- Bittensor:其核心架构是去中心化AI推理,这与TPU的张量计算能力形成原生的精准契合。
- Fetch(AI代理):自主AI代理依赖持续的神经网络推理进行决策,而TPU能以更低延迟运行这些模型。
- Singularity(AI服务平台):作为人工智能服务交易市场,Singularity通过集成TPU显著提升了底层模型执行的速度与成本效益。
- NEAR(公链、AI战略转型):向链上AI与可信执行环境代理的转型,它所依赖的张量运算正需TPU加速实现。
后量子密码学网络
为何选择TPU?后量子密码学的核心运算常涉及格中最短向量问题,这类需要密集矩阵与向量运算的任务,与AI工作负载在计算架构上具有高度相似性。
- Algorand(公链):采用量子安全哈希与向量运算的方案,与TPU的并行数学运算能力高度契合。
- QAN(抗量子公链):采用Lattice密码学,其底层所依赖的多项式、向量运算,与TPU专精的数学优化领域具有高度同构性。
- Nexus(计算平台、ZkVM):它的抗量子计算准备工作涉及的多项式与格基算法,能高效映射到TPU的架构上。
- Cellframe(抗量子公链):采用的Lattice密码学与哈希加密技术涉及类张量运算,使其成为TPU加速的理想候选方案。
- Abelian(隐私代币):专注后量子密码学Lattice运算。与QAN类似,其技术架构能充分受益于TPU向量处理器的高吞吐量特性。
- Quantus(公链):后量子密码学签名依赖大规模向量运算,而TPU处理此类运算的并行化能力远超标准CPU。
- Pauli(计算平台):量子安全计算涉及大量矩阵运算,而这正是TPU架构的核心优势所在。
发展瓶颈:为何TPU尚未全面普及?
若TPU在后量子密码学与零知识证明领域如此高效,为何行业仍在抢购H100芯片?
- CUDA护城河:英伟达的CUDA软件库已成为行业标准,绝大多数密码学工程师都基于CUDA进行编程。若要将代码移植到TPU所需的JAX或XLA框架,不仅技术门槛高,还需投入大量资源。
- 云平台准入门槛:高端TPU几乎被谷歌云独家垄断。去中心化网络若过度依赖单一中心化云服务商,将面临审查风险与单点故障危机。
- 架构僵化:密码学算法若需微调(如引入分支逻辑),TPU性能会急剧下滑。而GPU处理此类非规则逻辑的能力远胜TPU。
- 哈希运算中的局限性:TPU无法替代比特币矿机。SHA-256算法属于比特级运算而非矩阵运算,TPU在此领域毫无用武之地。
结论:分层架构才是未来
Web3硬件的未来并非一场赢家通吃的竞争,而是正朝着分层架构的方向演进。
GPU将继续承担通用计算、图形渲染及需处理复杂分支逻辑任务的主力角色。
TPU(及同类ASIC化加速器)将逐步成为Web3"数学层"的标准配置,专门用于生成零知识证明与验证后量子密码学签名。
随着区块链向后量子安全标准迁移,交易签名与验证所需的海量矩阵运算将使TPU的脉动架构不再是可选项,而成为构建可扩展的量子安全去中心化网络的必备基础设施。
免责声明:本页面信息可能来自第三方,不代表 Gate 的观点或意见。页面显示的内容仅供参考,不构成任何财务、投资或法律建议。Gate 对信息的准确性、完整性不作保证,对因使用本信息而产生的任何损失不承担责任。虚拟资产投资属高风险行为,价格波动剧烈,您可能损失全部投资本金。请充分了解相关风险,并根据自身财务状况和风险承受能力谨慎决策。具体内容详见声明。
评论
0/400
暂无评论