Reddio技术概览:从并行EVM到AI的叙事综述
金色财经_
ETH-4.49%
作者:雾月,极客web3
在区块链技术迭代越来越快的今天,针对性能的优化已然成为了一个关键议题,以太坊路线图已经非常明确以Rollup为中心,而EVM串行处理交易的特性是一种桎梏,无法满足未来的高并发计算场景。
在之前的文章——《从Reddio看并行EVM的优化之路》中,我们曾对Reddio的并行EVM设计思路进行了简要概述,而在今天的文章中,我们将对其技术方案,以及其和AI的结合场景进行更深入的解读。
由于Reddio的技术方案采用了CuEVM,这是一个利用GPU提升EVM执行效率的项目,我们将先从CuEVM开始说起。
CUDA概览
CuEVM是一个用GPU对EVM进行加速的项目,它将以太坊EVM的操作码转换为CUDA Kernels,以在NVIDIA GPU上并行执行。通过GPU的并行计算能力,来提高EVM指令的执行效率。可能N卡用户会常听到CUDA这个词——
**Compute Unified Device Architecture,这其实是NVIDIA开发的一种并行计算平台和编程模型。它允许开发者利用GPU的并行计算能力进行通用计算(例如Crypto中的挖矿、ZK运算等),**而不仅限于图形处理。
作为一个开放的并行计算框架,CUDA本质是C/C++语言的扩展,任何熟悉C/C++的底层程序员都可以快速上手。而在CUDA中一个很重要的概念是Kernel(核函数),它也是一种C++函数。

但与常规C++函数只执行一次不同,这些核函数在被启动语法<<<…>>>调用时会由N个不同的CUDA线程并行执行N次。
CUDA的每个线程都被分配了独立的thread ID,并且采用线程层次结构,将线程分配为块(block)和网格(grid),以便于管理大量的并行线程。通过NVIDIA的nvcc编译器,我们就可以将CUDA代码编译为可在GPU上运行的程序。

CuEVM的基础工作流程
在理解了CUDA的一系列基础概念后,就可以看下CuEVM的工作流了。
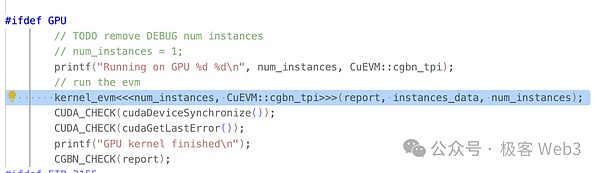
CuEVM的主入口为run_interpreter,从这里以json文件的形式,输入要并行处理的交易。从项目用例中可以看出,输入的都是标准的EVM内容,无需开发者另行处理、翻译等。

在run_interpreter()中可以看到,它使用CUDA定义的<<…>>语法调用了kernel_evm()核函数。我们上文提到过,核函数是会在GPU中并行调用。
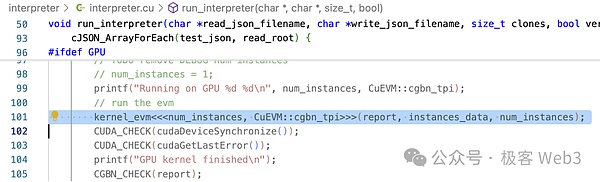
在kernel_evm()方法中会调用到evm->run(),我们可以看到这里面有大量的分支判断来将EVM操作码转换为CUDA操作。
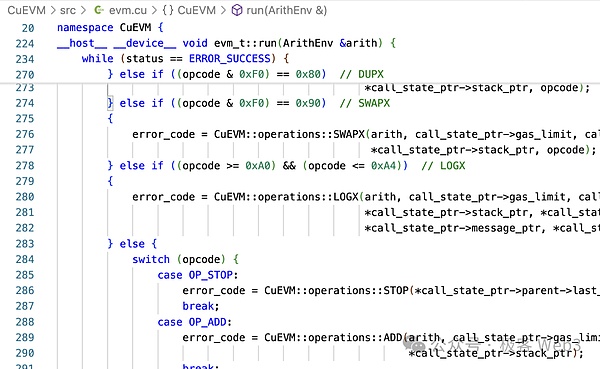
以EVM中的加法操作码OP_ADD为例,可以看到它将ADD转化为了cgbn_add。而CGBN(Cooperative Groups Big Numbers)就是CUDA高性能的多精度整数算术运算库。

这两步将EVM操作码转化为了CUDA操作。可以说,CuEVM也是对所有EVM操作在CUDA上的实现。最后,run_interpreter()方法返回运算结果,也即世界状态及其他信息即可。
至此CuEVM的基本运行逻辑已经介绍完毕。
**CuEVM是有并行处理交易的能力,但CuEVM立项的目的(或者说主要展示的用例)是用来做Fuzzing测试的:**Fuzzing是一种自动化的软件测试技术,它通过向程序输入大量无效、意外或随机的数据,以观察程序的响应,从而识别潜在的错误和安全问题。
我们可以看出Fuzzing非常适合并行处理。而CuEVM并不处理交易冲突等问题,那并不是它所关心的问题。如果想要集成CuEVM,那么还需对冲突交易进行处理。
我们在之前的文章《从Reddio看并行EVM的优化之路》中已经介绍过Reddio使用的冲突处理机制,这里不再赘述。Reddio在将交易用冲突处理机制排序完后,再发送进入CuEVM即可。换言之,Reddio L2的交易排序机制可以分为冲突处理+CuEVM并行执行两部分。
Layer2,并行EVM,AI的三岔路口
前文说并行EVM和L2仅仅是Reddio的起点,而其未来的路线图中将明确和AI叙事相结合。使用GPU进行高速并行交易的Reddio,在诸多特性上天生适合AI运算:
- GPU 的并行处理能力强,适合执行深度学习中的卷积运算,这些运算本质上是大规模的矩阵乘法,而 GPU 专为这类任务优化。
- GPU 的线程分级结构能够与 AI 计算中的不同数据结构对应关系相匹配,通过线程超配和 Warp 执行单元来提高计算效率并掩盖内存延迟。
- 计算强度是衡量 AI 计算性能的关键指标,GPU 通过优化计算强度,如引入 Tensor Core,来提升 AI 计算中矩阵乘法的性能,实现计算与数据传输之间的有效平衡。
那么AI与L2到底如何结合呢?
我们知道在Rollup的架构设计中,整个网络中其实并不仅仅是排序器,也会有一些类似监督者、转发者的角色,来验证或搜集交易,他们本质上都使用了与排序器同样的客户端,只是承担的职能不一样。在传统的Rollup中这些次要角色的职能和权限非常有限,如Arbitrum中的watcher这种角色,基本是被动性和防御性与公益性的,其盈利模式也值得怀疑。
Reddio会采用去中心化排序器的架构,矿工提供GPU作为节点。整个Reddio网络可以从单纯的L2演进为L2+AI的综合网络,它可以很好地实现一些AI+区块链用例:
AI Agent的交互基础网络
随着区块链技术的不断演进,AI Agent在区块链网络中的应用潜力巨大。我们以执行金融交易的AI Agent为例,这些智能代理可以自主进行复杂的决策和执行交易操作,甚至能在高频条件下快速反应。然而,L1在处理此类密集操作时,基本不可能承载巨大交易负载。

而Reddio作为L2项目,通过GPU加速可以大幅提高交易并行处理能力。相比L1,支持并行执行交易的L2具备更高的吞吐量,可以高效处理大量AI Agent的高频交易请求,确保网络的流畅运行。
在高频交易中,AI Agents对于交易速度和响应时间的要求极其苛刻。L2减少交易的验证和执行时间,从而显著降低延迟。这对于需要在毫秒级响应的AI Agent至关重要。通过将大量交易迁移至L2,也有效缓解了主网的拥堵问题。使得AI Agents的操作更加经济高效。
随着Reddio等L2项目的成熟,AI Agent将在区块链上发挥更重要的作用,推动DeFi和其他区块链应用场景与AI结合的创新。
去中心化算力市场
Reddio未来会采用去中心化排序器的架构,矿工以GPU算力来决定排序权利,整体网络参与者的GPU的性能会随着竞争逐渐提升,甚至能够达到用来作为AI训练的水平。
构建去中心化的GPU算力市场,为AI训练和推理提供更低成本的算力资源。算力从小到大,从个人计算机到机房集群,各种等级的GPU算力都可以加入该市场贡献自己的闲置算力并赚取收益,这种模式可以降低AI计算成本,让更多人参与AI模型开发和应用。
在去中心化算力市场用例中,排序器可能并不主要负责AI的直接的运算,其主要职能一是处理交易,二是在整个网络中协调AI算力。而关于算力和任务分配,这里面有两种模式:
- 自上而下的中心化分配。由于有排序器,排序器可以将受到的算力请求分配给符合需求且名望较好的节点。这种分配方式虽然理论上存在中心化和不公平的问题,但实际上其带来的效率优势远大于其弊端,并且长远来看排序器必须满足整个网络的正和性才能长远发展,也即有隐性但直接的制约确保排序器不会有太严重的偏向。
- 自下而上的自发任务选择。用户也可以将AI运算请求提交给第三方节点,在特定的AI应用领域这显然比直接提交给排序器更有效率,也能防止排序器的审查和偏向。在运算完毕后该节点再将运算结果同步给排序器并上链。
我们可以看出在L2 + AI的架构中,算力市场有极高的灵活性,可以从两个方向集结算力,最大程度上提升资源的利用率。
链上AI推理
目前,开源模型的成熟度已经足以满足多样化的需求。随着AI推理服务的标准化,**探索如何将算力上链以实现自动化定价成为可能。**然而这需要克服多项技术挑战:
- 高效请求分发与记录: 大模型推理对延迟要求高,高效请求分发机制非常关键。尽管请求和响应的数据量庞大且具私密性,不宜在区块链上公开,但也必须找到记录和验证的平衡点——例如,通过存储hash实现。
- 算力节点输出的验证: 节点是否真正地完成了所制定的运算任务?如,节点虚报用小模型运算结果代替大模型。
- 智能合约推理:将AI模型结合智能合约进行运算在很多场景下是必须的。由于AI推理具有不确定性,并不可能用于链上的方方面面,所以未来的AI dApp的逻辑很可能一部分位于链下而另一部分位于链上合约,链上合约对链下提供的输入的有效性和数值合法性进行限定。而在以太坊生态中,与智能合约结合就必须面对EVM的低效率的串行性。
但在Reddio的架构中,这些都相对容易解决:
- 排序器对请求的分发是远比L1高效的,可以认为等同于Web2的效率。而对于数据的记录位置和保留方式,可以由各种价格便宜的DA方案来解决。
- AI的运算结果可以最终由ZKP来验证其正确性和善意性。而ZKP的特点是验证非常快,但生成证明较慢。而ZKP的生成也恰好可以使用GPU或者TEE加速。
- Solidty → CUDA → GPU这一条EVM并行主线本就是Reddio的基础。所以表面上看这个对Reddio而言是最简单的问题。目前Reddio正与AiI6z的eliza合作,将其模块引入Reddio,这是一个非常值得探索的方向。
总结
整体来看,Layer2解决方案、并行EVM以及AI技术这几个领域看似互不相关,但Reddio通过充分利用GPU的运算特性,巧妙地将这几大创新领域有机地结合在了一起。
通过利用GPU的并行计算特性,Reddio在Layer2上提升了交易速度和效率,使得以太坊二层的性能得以增强。将AI技术融入区块链更是一个新颖且前景广阔的尝试。AI的引入可以为链上操作提供智能化的分析和决策支持,从而实现更为智能和动态的区块链应用。这种跨领域的整合,无疑为整个行业的发展开辟了新的道路和机遇。
然而,需要注意的是,这一领域仍处于早期阶段,仍需大量的研究和探索。技术的不断迭代和优化,以及市场先行者的想象力和行动,将是推动这项创新走向成熟的关键驱动力。Reddio已经在这个交汇点上迈出了重要且大胆的一步,我们期待未来在这一整合领域中,能看到更多的突破与惊喜。
免责声明:本页面信息可能来自第三方,不代表 Gate 的观点或意见。页面显示的内容仅供参考,不构成任何财务、投资或法律建议。Gate 对信息的准确性、完整性不作保证,对因使用本信息而产生的任何损失不承担责任。虚拟资产投资属高风险行为,价格波动剧烈,您可能损失全部投资本金。请充分了解相关风险,并根据自身财务状况和风险承受能力谨慎决策。具体内容详见声明。
评论
0/400
暂无评论