DeepSeek ได้ปล่อยเวอร์ชันพรีวิวของ DeepSeek-V4-Pro และ DeepSeek-V4-Flash เมื่อวันที่ 24 เมษายน 2026 โดยทั้งสองเป็นโมเดลแบบน้ำหนักเปิด (open-weight) ที่มีหน้าต่างคอนเท็กซ์ต์ 1 ล้านโทเค็น และมีราคาต่ำกว่าทางเลือกจากฝั่งตะวันตกที่เทียบเคียงได้อย่างมีนัยสำคัญ โมเดล V4-Pro มีค่าใช้จ่าย $1.74 ต่ออินพุตโทเค็น 1 ล้านโทเค็น และ $3.48 ต่อเอาต์พุตโทเค็น 1 ล้านโทเค็น—ประมาณ 1/20 ของราคา Claude Opus 4.7 และน้อยลง 98% เมื่อเทียบกับ GPT-5.5 Pro ตามสเปกอย่างเป็นทางการของบริษัท
สถาปัตยกรรมโมเดลและขนาด
DeepSeek-V4-Pro มีพารามิเตอร์รวม 1.6 ล้านล้านพารามิเตอร์ ทำให้เป็นโมเดลโอเพนซอร์สที่ใหญ่ที่สุดในตลาด LLM ณ ปัจจุบัน อย่างไรก็ตาม เฉพาะ 49 พันล้านพารามิเตอร์จะถูกเปิดใช้งานต่อการประมวลผลหนึ่งครั้ง (inference pass) โดยใช้แนวทางที่ DeepSeek เรียกว่า Mixture-of-Experts ซึ่งพัฒนาปรับปรุงมาตั้งแต่ V3 การออกแบบนี้ทำให้โมเดลทั้งชุดสามารถ “อยู่เฉยๆ” ได้ในขณะที่เปิดใช้งานเฉพาะส่วนที่เกี่ยวข้องสำหรับคำขอแต่ละรายการ ช่วยลดต้นทุนการคำนวณในขณะที่ยังคงความสามารถด้านความรู้ไว้
DeepSeek-V4-Flash ทำงานที่ขนาดเล็กกว่าด้วยพารามิเตอร์รวม 284 พันล้าน และพารามิเตอร์ที่เปิดใช้งาน 13 พันล้าน ตามรายงานการทดสอบ (benchmarks) ของ DeepSeek มัน “ทำผลงานด้านการให้เหตุผลเทียบเคียงกับเวอร์ชัน Pro เมื่อให้งบประมาณการคิด (thinking budget) ที่มากขึ้น”
ทั้งสองโมเดลรองรับคอนเท็กซ์ต์ได้ 1 ล้านโทเค็นเป็นคุณลักษณะมาตรฐาน—ประมาณ 750,000 คำ หรือเทียบเท่ากับไตรภาค “The Lord of the Rings” ทั้งเล่มบวกข้อความเพิ่มเติม
นวัตกรรมด้านเทคนิค: กลไก Attention ในระดับขนาดใหญ่
DeepSeek แก้ปัญหาการขยายขนาดด้านการคำนวณที่มีอยู่ในงานประมวลผลคอนเท็กซ์ต์แบบยาว โดยการคิดค้น attention สองประเภทใหม่ ดังที่ระบุไว้ในเอกสารทางเทคนิคของบริษัท ซึ่งมีให้ใช้งานบน GitHub
กลไกการ attention ของ AI ทั่วไปเผชิญปัญหาการขยายขนาดที่โหดมาก: ทุกครั้งที่ความยาวคอนเท็กซ์ต์เพิ่มเป็นสองเท่า ต้นทุนการคำนวณจะเพิ่มขึ้นประมาณสี่เท่า DeepSeek แก้ปัญหาด้วยแนวทางที่เติมเต็มกันสองแบบ:
Compressed Sparse Attention ทำงานเป็นสองขั้นตอน ขั้นแรก มันจะบีบอัดกลุ่มของโทเค็น—เช่น ทุก 4 โทเค็น—ให้กลายเป็นรายการเดียว จากนั้น แทนที่จะ attend ไปยังรายการที่ถูกบีบอัดทั้งหมด มันใช้ “Lightning Indexer” เพื่อเลือกผลลัพธ์ที่เกี่ยวข้องที่สุดสำหรับคำถามใดคำถามหนึ่ง ซึ่งจะลดขอบเขต attention จากหนึ่งล้านโทเค็นให้เหลือชุดที่เล็กกว่ามากซึ่งประกอบด้วยชิ้นส่วน (chunks) ที่สำคัญ
Heavily Compressed Attention ใช้แนวทางที่ก้าวร้าวกว่า โดยยุบทุก 128 โทเค็นให้เป็นรายการเดียว โดยไม่ต้องใช้การเลือกแบบ sparse แม้สิ่งนี้จะทำให้สูญเสียรายละเอียดแบบละเอียด แต่กลับให้มุมมองภาพรวมทั่วโลกที่มีราคาถูกมาก attention ทั้งสองประเภทจะรันในเลเยอร์สลับกัน ทำให้โมเดลสามารถรักษาทั้งความละเอียดและภาพรวมไว้ได้
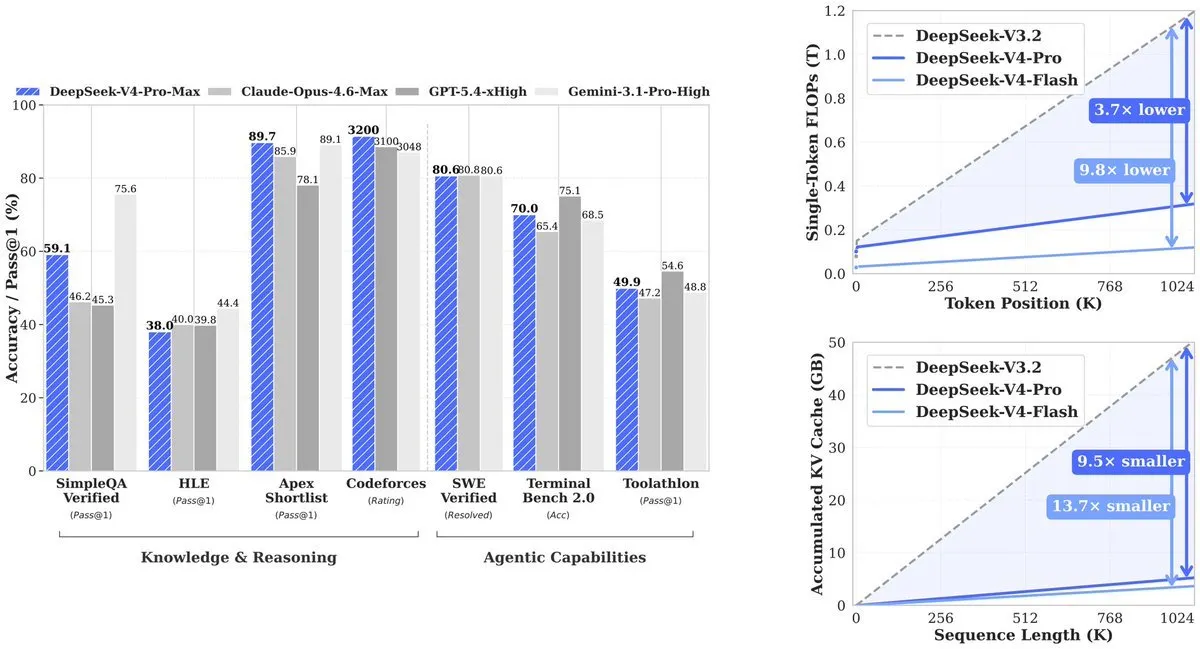
ผลลัพธ์คือ: V4-Pro ใช้การคำนวณเพียง 27% ของที่รุ่นก่อน (V3.2) ต้องใช้ KV cache—หน่วยความจำที่จำเป็นต่อการติดตามคอนเท็กซ์ต์—ลดลงเหลือ 10% ของ V3.2 V4-Flash ผลักดันประสิทธิภาพให้ยิ่งไปอีก: ใช้การคำนวณ 10% และหน่วยความจำ 7% เมื่อเทียบกับ V3.2
ผลการทดสอบ Benchmark และสถานะการแข่งขัน
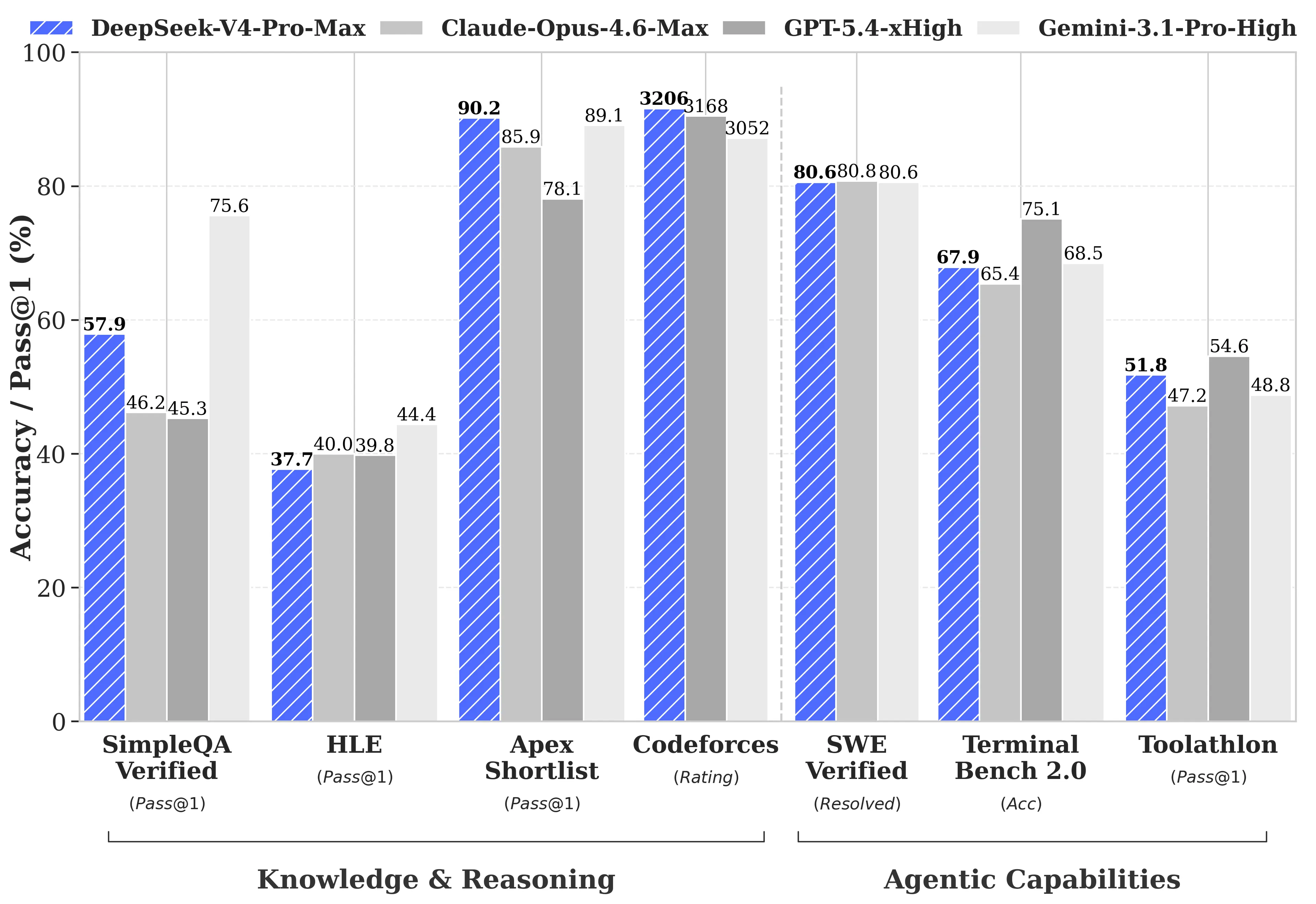
DeepSeek เผยแพร่การเปรียบเทียบ benchmark แบบครอบคลุมกับ GPT-5.4 และ Gemini-3.1-Pro รวมถึงส่วนที่ V4-Pro ตามหลังคู่แข่ง ในงานด้านการให้เหตุผล (reasoning) V4-Pro ตามหลัง GPT-5.4 และ Gemini-3.1-Pro ประมาณสามถึงหกเดือน ตามรายงานทางเทคนิคของ DeepSeek
จุดที่ V4-Pro ทำได้ดีกว่า:
- Codeforces (การแข่งขันเขียนโค้ดแบบแข่งขัน): V4-Pro ได้คะแนน 3,206 ทำให้อยู่ราวอันดับที่ 23 จากผู้เข้าร่วมการแข่งขันที่เป็นมนุษย์จริงๆ
- Apex Shortlist (คัดสรรโจทย์คณิตศาสตร์และ STEM): อัตราผ่าน 90.2% เทียบกับ Opus 4.6 ที่ 85.9% และ GPT-5.4 ที่ 78.1%
- SWE-Verified (การแก้ไขปัญหา GitHub): 80.6% เทียบเท่า Claude Opus 4.6
จุดที่ V4-Pro ตามหลัง:
- MMLU-Pro (การทำงานหลายอย่างพร้อมกัน): Gemini-3.1-Pro ที่ 91.0% เทียบกับ V4-Pro ที่ 87.5%
- GPQA Diamond (ความรู้เชิงผู้เชี่ยวชาญ): Gemini ที่ 94.3 เทียบกับ V4-Pro ที่ 90.1
- Humanity’s Last Exam (ระดับบัณฑิตศึกษา): Gemini-3.1-Pro ที่ 44.4% เทียบกับ V4-Pro ที่ 37.7%
ในงานคอนเท็กซ์ต์แบบยาว V4-Pro นำหน้าโมเดลโอเพนซอร์ส และเอาชนะ Gemini-3.1-Pro ใน CorpusQA (การจำลองการวิเคราะห์เอกสารจริงที่คอนเท็กซ์ต์ 1 ล้านโทเค็น) แต่กลับแพ้ Claude Opus 4.6 ใน MRCR ซึ่งวัดการดึงข้อมูลเฉพาะที่ถูกฝังลึกในข้อความความยาวมาก
ความสามารถด้าน Agentic และการเขียนโค้ด
V4-Pro สามารถรันใน Claude Code, OpenCode และเครื่องมือช่วยเขียนโค้ด AI อื่นๆ ได้ ตามแบบสำรวจภายในของ DeepSeek ที่ทำกับนักพัฒนา 85 คนซึ่งใช้ V4-Pro เป็นเอเจนต์เขียนโค้ดหลักของพวกเขา 52% กล่าวว่ามันพร้อมที่จะเป็นโมเดลเริ่มต้นของพวกเขา 39% เอนเอียงไปทาง “ใช่” และน้อยกว่า 9% บอกว่า “ไม่” การทดสอบภายในของ DeepSeek ระบุว่า V4-Pro มีประสิทธิภาพเหนือกว่า Claude Sonnet และเข้าใกล้ Claude Opus 4.5 ในงานเขียนโค้ดแบบ agentic
Artificial Analysis จัดอันดับ V4-Pro เป็นอันดับหนึ่งในบรรดาโมเดลแบบน้ำหนักเปิดทั้งหมดใน GDPval-AA ซึ่งเป็น benchmark สำหรับทดสอบงานความรู้ที่มีคุณค่าทางเศรษฐกิจในด้านการเงิน กฎหมาย และงานวิจัย V4-Pro-Max ได้ 1,554 Elo นำหน้า GLM-5.1 (1,535) และ MiniMax’s M2.7 (1,514) Claude Opus 4.6 ได้ 1,619 ใน benchmark เดียวกัน
V4 แนะนำ “interleaved thinking” ซึ่งคง chain of thought ทั้งหมดไว้ตลอดการเรียกใช้เครื่องมือ (tool calls) ในโมเดลก่อนหน้า เมื่อเอเจนต์ทำการเรียกใช้เครื่องมือหลายครั้ง—เช่น ค้นหาเว็บ รันโค้ด แล้วค่อยค้นหาอีกครั้ง—บริบทด้านการให้เหตุผลของโมเดลจะถูกล้างระหว่างรอบ V4 คงความต่อเนื่องของเหตุผลข้ามขั้นตอน ป้องกันการสูญเสียคอนเท็กซ์ต์ในเวิร์กโฟลว์อัตโนมัติที่ซับซ้อน
ภูมิทัศน์การแข่งขันและบริบทด้านราคา
การเปิดตัว V4 เกิดขึ้นท่ามกลางกิจกรรมที่สำคัญในแวดวง AI Anthropic ส่ง Claude Opus 4.7 เมื่อวันที่ 16 เมษายน 2026 OpenAI เปิดตัว GPT-5.5 เมื่อวันที่ 23 เมษายน 2026 โดย GPT-5.5 Pro มีราคาที่ $30 ต่ออินพุตโทเค็นหนึ่งล้าน$180 และ (ต่อเอาต์พุตโทเค็นหนึ่งล้าน) GPT-5.5 เอาชนะ V4-Pro ใน Terminal Bench 2.0 (82.7% เทียบกับ 70.0%) ซึ่งทดสอบเวิร์กโฟลว์ของเอเจนต์แบบ command-line ที่ซับซ้อน
Xiaomi เปิดตัว MiMo V2.5 Pro เมื่อวันที่ 22 เมษายน 2026 โดยมอบความสามารถมัลติโหมดแบบเต็มรูปแบบ $1 image, audio, video$3 ที่ (input และ )output ต่อหนึ่งล้านโทเค็น Tencent เปิดตัว Hy3 ในวันเดียวกับ GPT-5.5
สำหรับมุมมองด้านราคา: Saoud Rizwan ซีอีโอของ Cline ระบุว่า หาก Uber ใช้ DeepSeek แทน Claude งบประมาณ AI ในปี 2026—ตามรายงานว่าเพียงพอต่อการใช้งานสี่เดือน—จะสามารถใช้ได้นานถึงเจ็ดปี
![Pricing comparison and Uber budget analysis]https://img-cdn.gateio.im/social/moments-0ee5a4bf95-cbc5686e31-8b7abd-badf29
การใช้งานจริงและความพร้อมใช้งาน
ทั้ง V4-Pro และ V4-Flash ได้รับอนุญาตแบบ MIT และพร้อมใช้งานบน Hugging Face โมเดลทั้งสองเป็นแบบข้อความล้วน (text-only) ในตอนนี้; DeepSeek ระบุว่ากำลังทำงานเพื่อเพิ่มความสามารถแบบมัลติโหมด ทั้งสองโมเดลสามารถรันได้ฟรีบนฮาร์ดแวร์ภายในเครื่อง หรือปรับแต่งตามความต้องการของบริษัท
ปลายทาง (endpoints) deepseek-chat และ deepseek-reasoner ที่มีอยู่ของ DeepSeek ส่งต่อไปยัง V4-Flash แล้วในโหมดไม่คิด (non-thinking) และโหมดคิด (thinking) ตามลำดับ ส่วน endpoints รุ่นเดิมของ deepseek-chat และ deepseek-reasoner จะหมดอายุวันที่ 24 กรกฎาคม 2026
DeepSeek ฝึก V4 บางส่วนบนชิป Huawei Ascend ซึ่งหลบเลี่ยงข้อจำกัดการส่งออกของสหรัฐฯ บริษัทระบุว่าเมื่อมี supernodes ใหม่ 950 แห่งเข้ามาออนไลน์ในช่วงปลายปี 2026 ราคาที่ต่ำอยู่แล้วของโมเดล Pro จะลดลงอีก
นัยเชิงปฏิบัติ
สำหรับองค์กร โครงสร้างราคาที่เปลี่ยนไปอาจส่งผลต่อการคำนวณคุ้มค่าใช้จ่าย (cost-benefit) โมเดลที่นำหน้า benchmark แบบโอเพนซอร์สที่ $1.74 ต่ออินพุตโทเค็นหนึ่งล้าน ทำให้กระบวนการประมวลผลเอกสารขนาดใหญ่ การทบทวนทางกฎหมาย และไปป์ไลน์การสร้างโค้ด ถูกกว่ามากเมื่อเทียบกับหกเดือนก่อน บริบทคอนเท็กซ์ต์หนึ่งล้านโทเค็นทำให้สามารถประมวลผลทั้งฐานโค้ดหรือเอกสารยื่นด้านกฎระเบียบในคำขอเดียว แทนที่จะต้องแบ่งเป็นชิ้นๆ ตามหลายครั้งของการเรียกใช้
สำหรับนักพัฒนาและผู้สร้างเดี่ยว (solo builders) V4-Flash คือข้อพิจารณาหลัก ที่ราคา $0.14 สำหรับอินพุต และ $0.28 สำหรับเอาต์พุตต่อหนึ่งล้านโทเค็น มันถูกกว่าโมเดลที่ถูกมองว่าเป็นตัวเลือกงบประมาณเมื่อหนึ่งปีก่อน ขณะเดียวกันก็จัดการงานส่วนใหญ่ที่เวอร์ชัน Pro ทำได้