Nguồn gốc: qubits
 Nguồn hình ảnh: Được tạo bởi Unbounded AI
Nguồn hình ảnh: Được tạo bởi Unbounded AI
Một số cư dân mạng đã tìm thấy một bằng chứng khác cho thấy GPT-4 đã trở nên “ngu ngốc”.
Hắn chất vấn:
OpenAI sẽ ** lưu trữ các phản hồi lịch sử **, cho phép GPT-4 trực tiếp kể lại các câu trả lời được tạo trước đó.
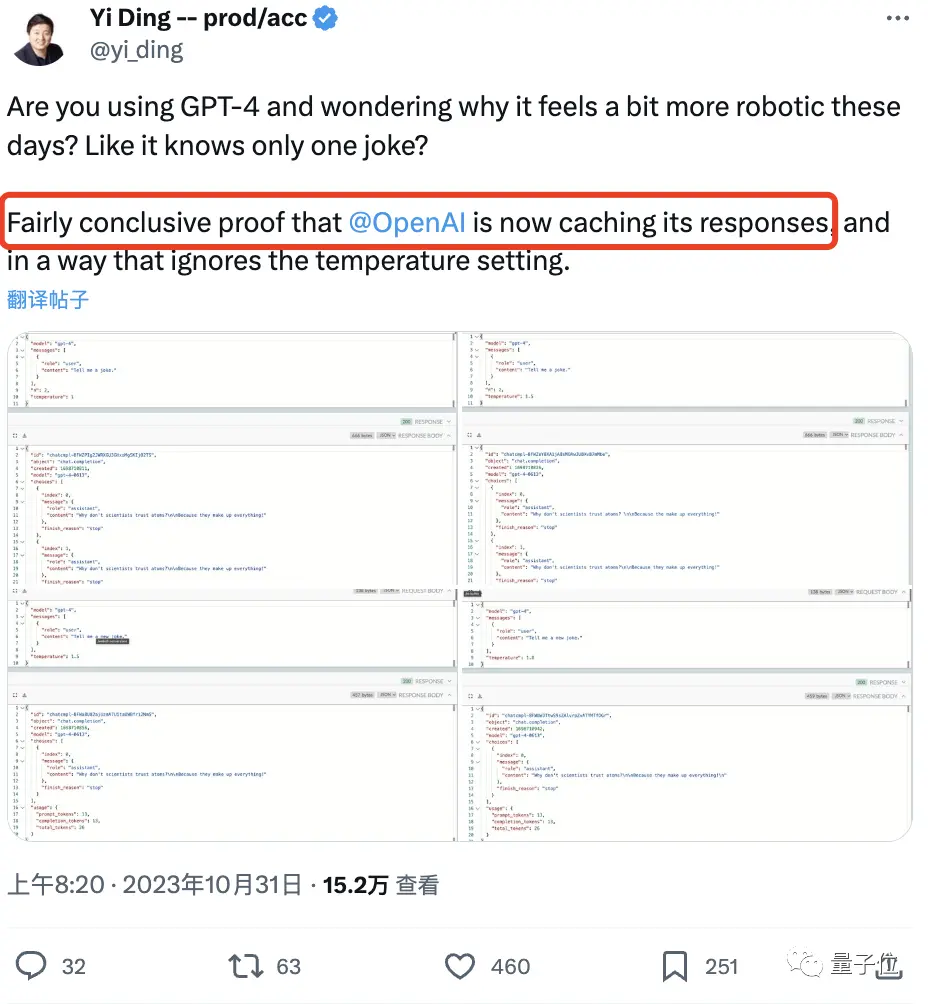 Ví dụ rõ ràng nhất về điều này là kể chuyện cười.
Ví dụ rõ ràng nhất về điều này là kể chuyện cười.
Bằng chứng cho thấy ngay cả khi ông bật giá trị nhiệt độ của mô hình, GPT-4 vẫn lặp lại phản ứng “nhà khoa học và nguyên tử” tương tự.
Đó là câu hỏi “Tại sao các nhà khoa học không tin tưởng các nguyên tử?” Bởi vì mọi thứ đều do họ tạo ra".
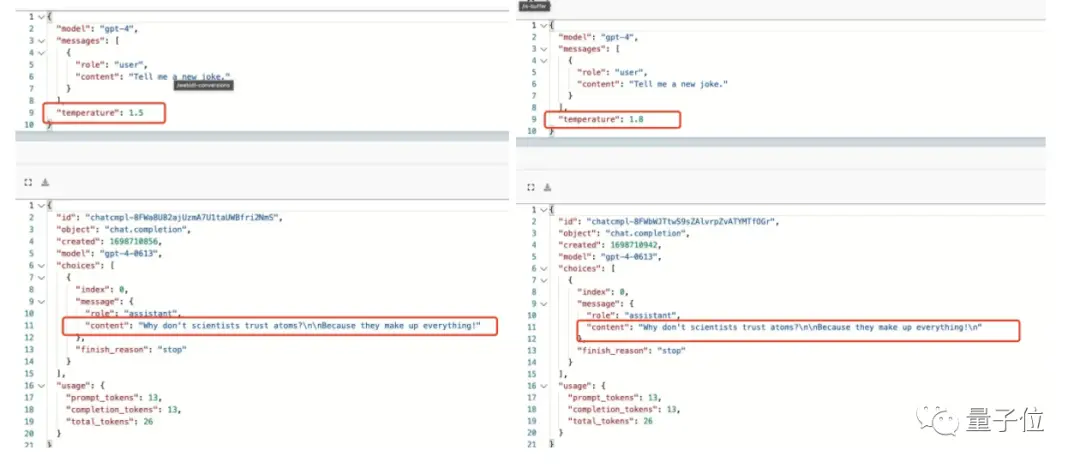 Ở đây, có lý do là giá trị nhiệt độ càng cao, mô hình càng dễ tạo ra một số từ bất ngờ và không nên lặp lại trò đùa tương tự.
Ở đây, có lý do là giá trị nhiệt độ càng cao, mô hình càng dễ tạo ra một số từ bất ngờ và không nên lặp lại trò đùa tương tự.
Không chỉ vậy, ngay cả khi chúng ta không di chuyển các tham số, ** thay đổi từ ngữ ** và nhấn mạnh việc nó kể một trò đùa ** mới, khác biệt **, nó sẽ không giúp ích gì.
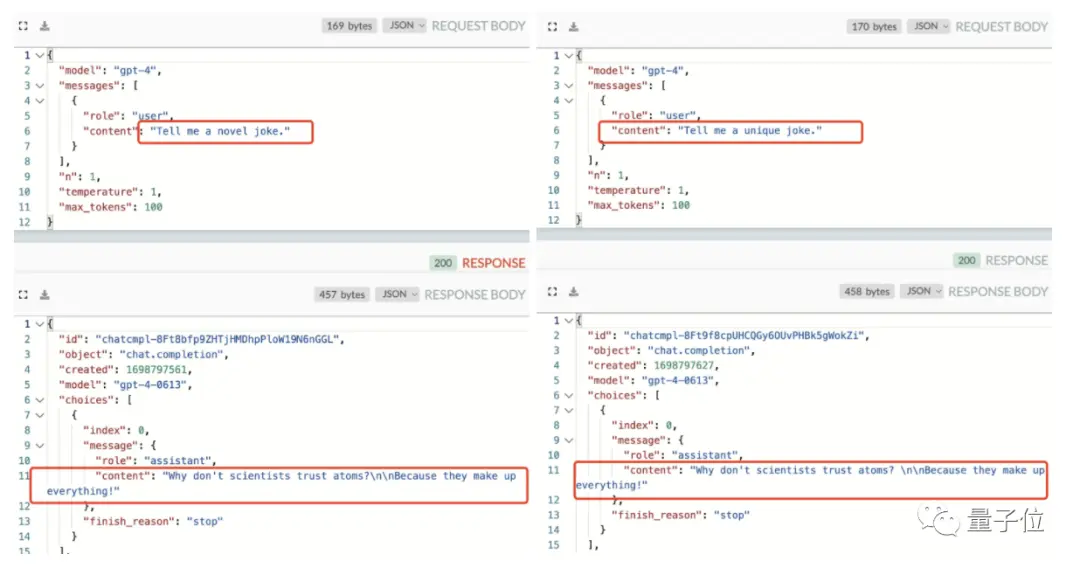 Theo người tìm thấy:
Theo người tìm thấy:
Điều này cho thấy GPT-4 không chỉ sử dụng bộ nhớ đệm mà còn ** truy vấn cụm ** thay vì khớp chính xác một câu hỏi.
Lợi ích của việc này là hiển nhiên và tốc độ phản hồi có thể nhanh hơn.
Tuy nhiên, vì tôi đã mua tư cách thành viên với giá cao nên tôi chỉ được hưởng dịch vụ truy xuất bộ nhớ cache như vậy và không ai hài lòng.
 Một số người cảm thấy sau khi đọc nó:
Một số người cảm thấy sau khi đọc nó:
Nếu đúng như vậy, không phải là không công bằng khi chúng ta tiếp tục sử dụng GPT-4 để đánh giá câu trả lời của các mô hình lớn khác?
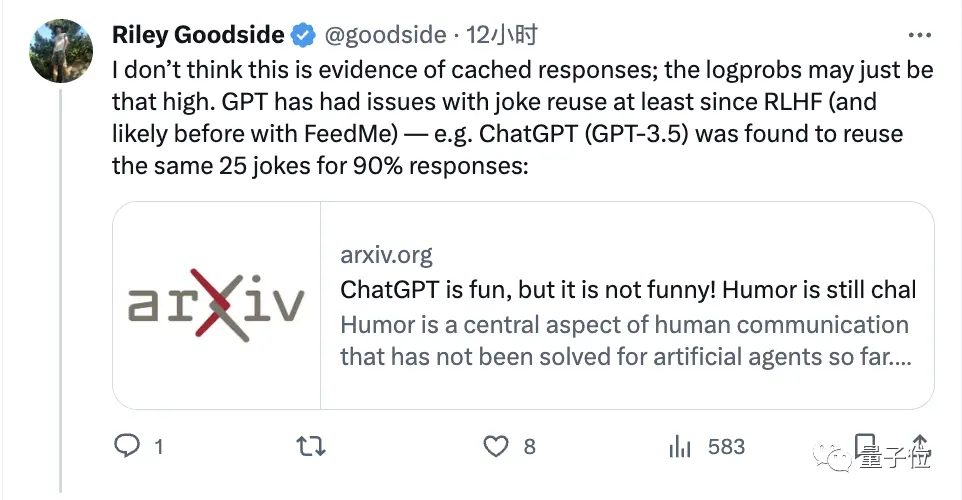
 Tất nhiên, cũng có những người không nghĩ rằng đây là kết quả của bộ nhớ đệm bên ngoài và có lẽ sự lặp đi lặp lại của các câu trả lời trong chính mô hình là rất cao **:
Tất nhiên, cũng có những người không nghĩ rằng đây là kết quả của bộ nhớ đệm bên ngoài và có lẽ sự lặp đi lặp lại của các câu trả lời trong chính mô hình là rất cao **:
Các nghiên cứu trước đây đã chỉ ra rằng ChatGPT lặp lại 25 trò đùa giống nhau 90% thời gian.
 Bạn nói thế nào?
Bạn nói thế nào?
** Bằng chứng Real Hammer GPT-4 với bộ nhớ cache Trả lời **
Không chỉ bỏ qua giá trị nhiệt độ, cư dân mạng này còn nhận thấy:
Thật vô ích khi thay đổi giá trị hàng đầu \ _p của mô hình, GPT-4 chỉ làm điều đó.
(top_p: Nó được sử dụng để kiểm soát tính xác thực của kết quả được trả về bởi mô hình và giá trị được hạ xuống nếu bạn muốn câu trả lời chính xác và dựa trên thực tế hơn, và các câu trả lời đa dạng hơn sẽ được bật lên)
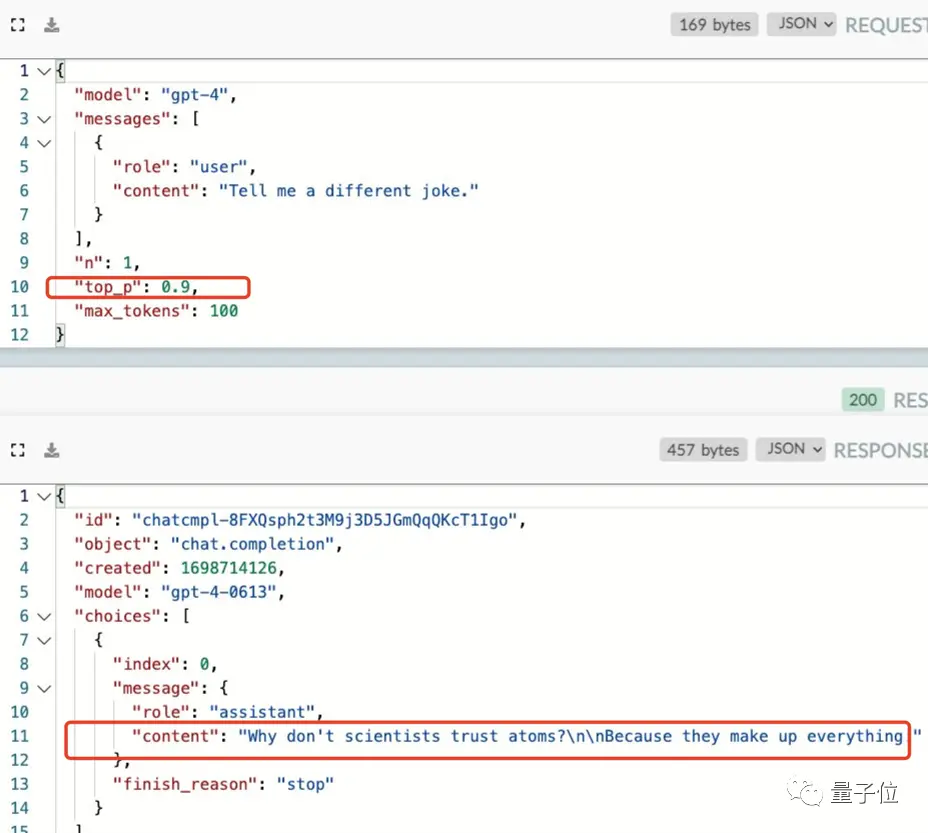 Cách duy nhất để bẻ khóa nó là kéo tham số ngẫu nhiên n lên để chúng ta có thể nhận được câu trả lời “không được lưu trong bộ nhớ cache” và có được một trò đùa mới.
Cách duy nhất để bẻ khóa nó là kéo tham số ngẫu nhiên n lên để chúng ta có thể nhận được câu trả lời “không được lưu trong bộ nhớ cache” và có được một trò đùa mới.
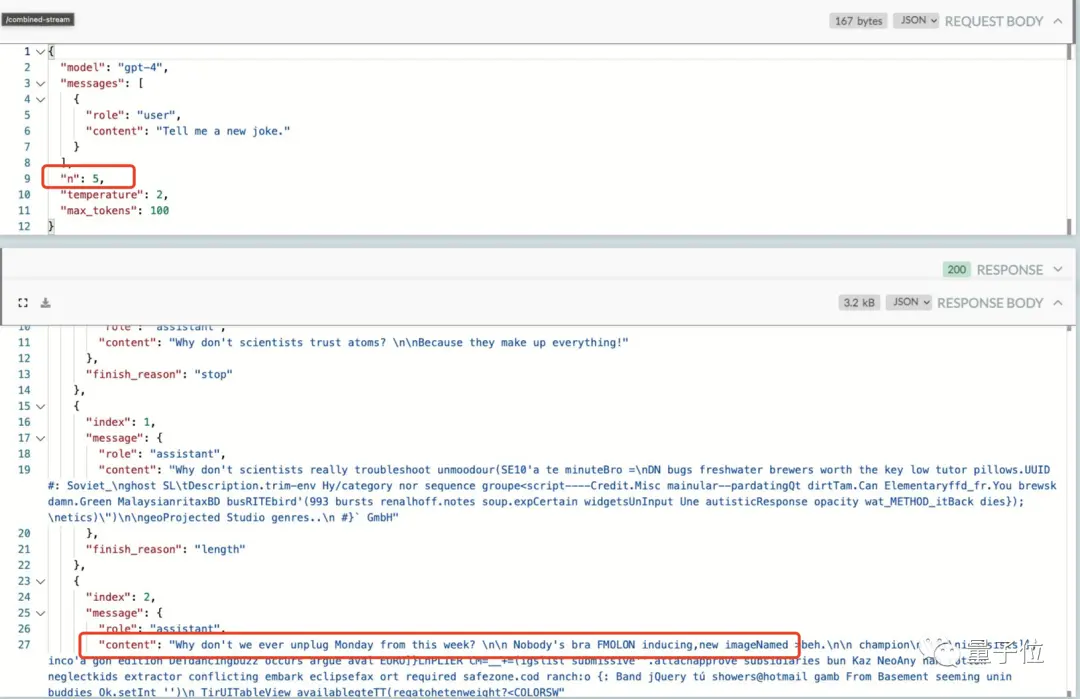 Tuy nhiên, nó đi kèm với “chi phí” của các phản hồi chậm hơn, vì có sự chậm trễ trong việc tạo nội dung mới.
Tuy nhiên, nó đi kèm với “chi phí” của các phản hồi chậm hơn, vì có sự chậm trễ trong việc tạo nội dung mới.
Điều đáng nói là những người khác dường như đã tìm thấy một hiện tượng tương tự trên mô hình địa phương.
 Có ý kiến cho rằng “tiền tố-match hit” trong ảnh chụp màn hình dường như chứng minh rằng bộ nhớ cache thực sự được sử dụng.
Có ý kiến cho rằng “tiền tố-match hit” trong ảnh chụp màn hình dường như chứng minh rằng bộ nhớ cache thực sự được sử dụng.
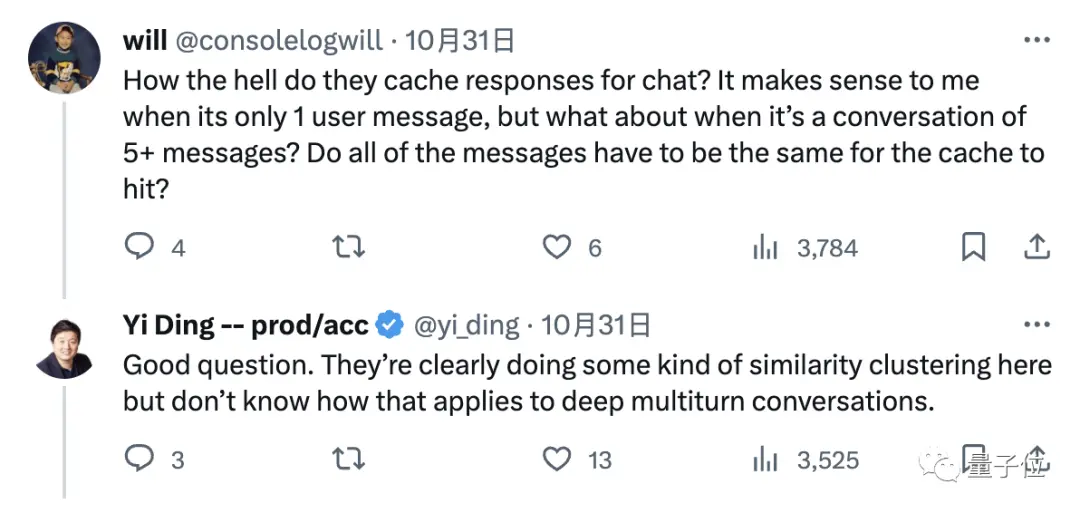
Vì vậy, câu hỏi là, làm thế nào chính xác để mô hình lớn lưu trữ thông tin trò chuyện của chúng tôi?
Câu hỏi hay, từ ví dụ thứ hai được hiển thị ở phần đầu, rõ ràng là có một số loại hoạt động “phân cụm”, nhưng chúng ta không biết cách áp dụng nó vào các cuộc trò chuyện nhiều vòng sâu sắc.
 Bất chấp câu hỏi này, một số người đã nhìn thấy điều này và nhớ đến tuyên bố của ChatGPT rằng “dữ liệu của bạn được lưu trữ với chúng tôi, nhưng một khi cuộc trò chuyện kết thúc, nội dung cuộc trò chuyện sẽ bị xóa”, và đột nhiên nhận ra.
Bất chấp câu hỏi này, một số người đã nhìn thấy điều này và nhớ đến tuyên bố của ChatGPT rằng “dữ liệu của bạn được lưu trữ với chúng tôi, nhưng một khi cuộc trò chuyện kết thúc, nội dung cuộc trò chuyện sẽ bị xóa”, và đột nhiên nhận ra.
 Điều này không thể không khiến một số người bắt đầu lo lắng về bảo mật dữ liệu:
Điều này không thể không khiến một số người bắt đầu lo lắng về bảo mật dữ liệu:
Điều này có nghĩa là các cuộc trò chuyện chúng tôi bắt đầu vẫn được lưu trong cơ sở dữ liệu của họ?
 Tất nhiên, một số người có thể suy nghĩ quá nhiều về mối quan tâm này:
Tất nhiên, một số người có thể suy nghĩ quá nhiều về mối quan tâm này:
Có lẽ đó chỉ là bộ nhớ cache câu trả lời và nhúng truy vấn của chúng tôi được lưu trữ.
 Vì vậy, như chính người khám phá đã nói:
Vì vậy, như chính người khám phá đã nói:
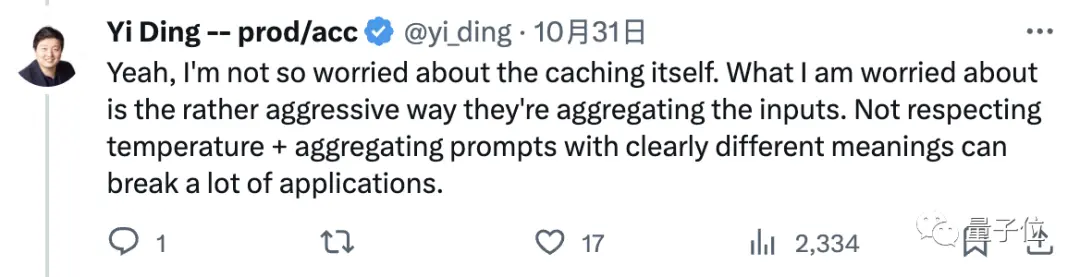
Tôi không quá lo lắng về bộ nhớ đệm.
Tôi lo lắng rằng OpenAI quá đơn giản và thô lỗ để tóm tắt các câu hỏi của chúng tôi để trả lời, bất kể cài đặt như nhiệt độ và trực tiếp tổng hợp lời nhắc với ý nghĩa rõ ràng khác nhau, điều này sẽ có tác động xấu và có thể “loại bỏ” nhiều ứng dụng (dựa trên GPT-4).
 Tất nhiên, không phải ai cũng đồng ý rằng những phát hiện trên chứng minh rằng OpenAI thực sự đang sử dụng các câu trả lời được lưu trong bộ nhớ cache.
Tất nhiên, không phải ai cũng đồng ý rằng những phát hiện trên chứng minh rằng OpenAI thực sự đang sử dụng các câu trả lời được lưu trong bộ nhớ cache.
Lý do của họ là trường hợp được tác giả thông qua tình cờ là một trò đùa.
Rốt cuộc, vào tháng 6 năm nay, hai học giả người Đức đã thử nghiệm và phát hiện ra rằng 90% trong số 1.008 kết quả của ChatGPT kể một trò đùa ngẫu nhiên là các biến thể của cùng 25 câu chuyện cười.
 Đặc biệt, “các nhà khoa học và nguyên tử” xuất hiện thường xuyên nhất, với 119 lần.
Đặc biệt, “các nhà khoa học và nguyên tử” xuất hiện thường xuyên nhất, với 119 lần.
Vì vậy, bạn có thể hiểu tại sao nó trông như thể câu trả lời trước đó được lưu trữ.
Do đó, một số cư dân mạng cũng đề xuất sử dụng các dạng câu hỏi khác để kiểm tra rồi xem.
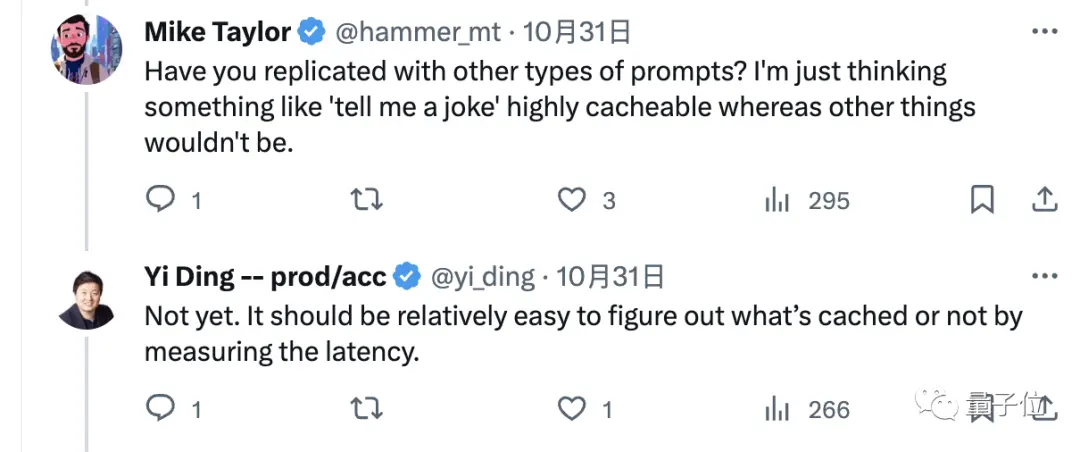
Tuy nhiên, các tác giả nhấn mạnh rằng nó không phải là một vấn đề và thật dễ dàng để biết liệu nó có được lưu trong bộ nhớ cache hay không chỉ bằng cách đo độ trễ.
 Cuối cùng, chúng ta hãy xem xét câu hỏi này từ một “quan điểm khác”:
Cuối cùng, chúng ta hãy xem xét câu hỏi này từ một “quan điểm khác”:
Có gì sai với GPT-4 kể một trò đùa mọi lúc?
Không phải chúng ta luôn nhấn mạnh sự cần thiết của các mô hình lớn để đưa ra câu trả lời nhất quán và đáng tin cậy? Không, nó ngoan ngoãn như thế nào (đầu chó thủ công).
 Vì vậy, GPT-4 có bộ nhớ cache hay không, và bạn đã quan sát thấy bất cứ điều gì tương tự?
Vì vậy, GPT-4 có bộ nhớ cache hay không, và bạn đã quan sát thấy bất cứ điều gì tương tự?
Liên kết tham khảo: