Nguồn gốc: New Zhiyuan
 Nguồn hình ảnh: Được tạo bởi Unbounded AI
Nguồn hình ảnh: Được tạo bởi Unbounded AI
Cách đây một thời gian, Google DeepMind đã đề xuất một phương pháp “Step-Backing” mới, trực tiếp làm cho công nghệ mở não.
Nói một cách đơn giản, đó là để cho mô hình ngôn ngữ lớn tự trừu tượng hóa vấn đề, có được một khái niệm hoặc nguyên tắc chiều cao hơn, và sau đó sử dụng kiến thức trừu tượng như một công cụ để suy luận và rút ra câu trả lời cho vấn đề.
 Địa chỉ:
Địa chỉ:
Kết quả cũng rất tốt, khi họ thử nghiệm với mô hình PaLM-2L và chứng minh rằng kỹ thuật mới này hoạt động rất tốt trong việc xử lý một số nhiệm vụ và vấn đề nhất định.
Ví dụ, MMLU có sự cải thiện 7% về hiệu suất vật lý và hóa học, cải thiện 27% trong TimeQA và cải thiện 7% trong MuSiQue.
Trong số đó, MMLU là một bộ dữ liệu kiểm tra hiểu ngôn ngữ đa nhiệm quy mô lớn, TimeOA là bộ dữ liệu kiểm tra câu hỏi nhạy cảm với thời gian và MusiQue là bộ dữ liệu Hỏi & Đáp đa bước chứa 25.000 câu hỏi từ 2 đến 4 bước.
Trong số đó, một bài toán multi-hop đề cập đến một câu hỏi chỉ có thể được trả lời bằng cách sử dụng một đường dẫn suy luận đa hop được hình thành bởi nhiều bộ ba.
Dưới đây, chúng ta hãy xem cách công nghệ này được triển khai.
Lùi lại!
Sau khi đọc phần giới thiệu ở phần đầu, độc giả có thể không hiểu quá nhiều. Điều đó có ý nghĩa gì đối với LLM khi tự trừu tượng hóa vấn đề và có được một khái niệm hoặc nguyên tắc chiều cao hơn?
Hãy lấy một ví dụ cụ thể.
Ví dụ: nếu người dùng muốn đặt câu hỏi liên quan đến “lực” trong vật lý, thì LLM có thể quay trở lại mức độ định nghĩa cơ bản và nguyên tắc lực khi trả lời câu hỏi đó, có thể được sử dụng làm cơ sở để lý luận thêm về câu trả lời.
Dựa trên ý tưởng này, khi người dùng lần đầu tiên vào, nó đại khái như thế này:
Bây giờ bạn là một chuyên gia về kiến thức thế giới, thành thạo trong việc suy nghĩ cẩn thận và trả lời các câu hỏi từng bước với một chiến lược đặt câu hỏi ngược.
Lùi lại là một chiến lược tư duy để hiểu và phân tích một vấn đề hoặc tình huống cụ thể từ góc độ vĩ mô, cơ bản hơn. Do đó, trả lời tốt hơn câu hỏi ban đầu.
Tất nhiên, ví dụ vật lý được đưa ra ở trên chỉ minh họa một trường hợp. Trong một số trường hợp, chiến lược lùi lại có thể cho phép LLM cố gắng xác định phạm vi và bối cảnh của vấn đề. Một số vấn đề rút lui nhiều hơn một chút, và một số rơi ít hơn.
Luận đề
Đầu tiên, các nhà nghiên cứu chỉ ra rằng lĩnh vực xử lý ngôn ngữ tự nhiên (NLP) đã mở ra một cuộc cách mạng đột phá với các LLM dựa trên Transformer.
Việc mở rộng kích thước mô hình và tăng kho dữ liệu được đào tạo trước đã mang lại những cải tiến đáng kể về khả năng mô hình và hiệu quả lấy mẫu, cũng như các khả năng mới nổi như suy luận nhiều bước và hướng dẫn sau.
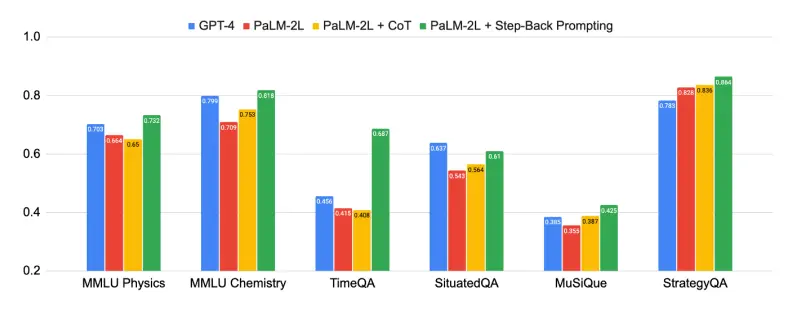 Hình trên cho thấy sức mạnh của lý luận ngược, và phương pháp “lý luận trừu tượng” được đề xuất trong bài báo này đã có những cải tiến đáng kể trong một loạt các nhiệm vụ khó khăn đòi hỏi lý luận phức tạp, chẳng hạn như khoa học, công nghệ, kỹ thuật và toán học, và lý luận đa bước.
Hình trên cho thấy sức mạnh của lý luận ngược, và phương pháp “lý luận trừu tượng” được đề xuất trong bài báo này đã có những cải tiến đáng kể trong một loạt các nhiệm vụ khó khăn đòi hỏi lý luận phức tạp, chẳng hạn như khoa học, công nghệ, kỹ thuật và toán học, và lý luận đa bước.
Một số nhiệm vụ rất khó khăn, và lúc đầu, PaLM-2L và GPT-4 chỉ chính xác 40% trên TimeQA và MuSiQue. Sau khi áp dụng lý luận ngược, hiệu suất của PaLM-2L đã được cải thiện trên diện rộng. Nó đã cải thiện 7% và 11% trong vật lý và hóa học MMLU, 27% trong TimeQA và 7% trong MuSiQue.
Không chỉ vậy, các nhà nghiên cứu còn tiến hành phân tích lỗi và họ phát hiện ra rằng hầu hết các lỗi xảy ra khi áp dụng lý luận ngược là do những hạn chế vốn có về khả năng suy luận của LLM và không liên quan đến các công nghệ mới.
Trừu tượng hóa dễ học hơn cho LLM, vì vậy nó chỉ ra con đường cho sự phát triển hơn nữa của lý luận ngược.
Trong khi tiến bộ đã được thực hiện, lý luận nhiều bước phức tạp có thể là thách thức. Điều này đúng ngay cả đối với các LLM tiên tiến nhất.
Bài viết này cho thấy rằng giám sát quá trình với chức năng xác minh từng bước là một biện pháp khắc phục hiệu quả để cải thiện tính đúng đắn của các bước lý luận trung gian.
Họ đã giới thiệu các kỹ thuật như lời nhắc Chuỗi suy nghĩ để tạo ra một loạt các bước suy luận trung gian mạch lạc, tăng tỷ lệ thành công khi đi theo con đường giải mã chính xác.
Khi nói về nguồn gốc của công nghệ PROMP này, các nhà nghiên cứu chỉ ra rằng khi phải đối mặt với các nhiệm vụ đầy thách thức, con người có xu hướng lùi lại một bước và trừu tượng, để rút ra các khái niệm và nguyên tắc cấp cao để hướng dẫn quá trình lý luận.
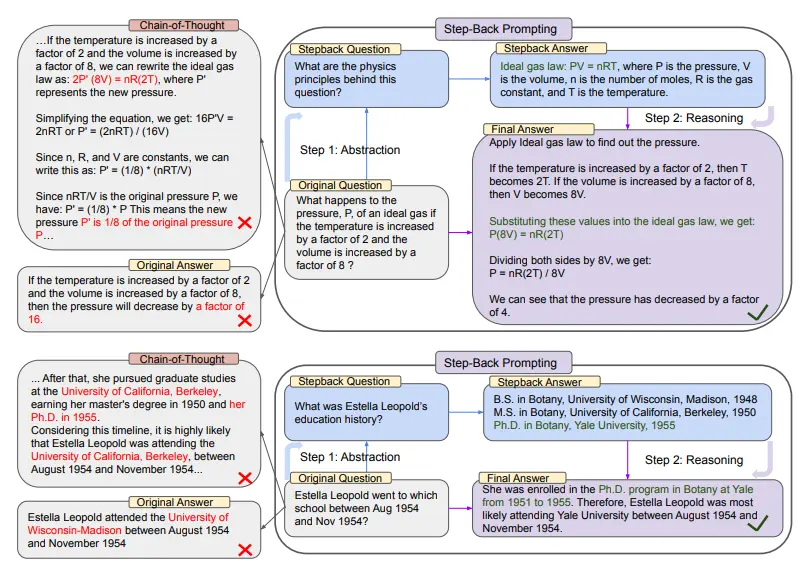 Ở phần trên của hình trên, lấy vật lý trung học của MMLU làm ví dụ, thông qua trừu tượng ngược, LLM có được nguyên tắc đầu tiên của định luật khí lý tưởng.
Ở phần trên của hình trên, lấy vật lý trung học của MMLU làm ví dụ, thông qua trừu tượng ngược, LLM có được nguyên tắc đầu tiên của định luật khí lý tưởng.
Trong nửa sau, có một ví dụ từ TimeQA, trong đó khái niệm cấp cao về lịch sử giáo dục là kết quả của sự trừu tượng LLM dựa trên chiến lược này.
Từ phía bên trái của toàn bộ sơ đồ, chúng ta có thể thấy rằng PaLM-2L đã không thành công trong việc trả lời câu hỏi ban đầu. Chuỗi suy nghĩ chỉ ra rằng ở giữa bước lý luận, LLM đã mắc lỗi (được tô sáng màu đỏ).
Và bên phải, PaLM-2L, với ứng dụng công nghệ lạc hậu, đã trả lời thành công câu hỏi.
Trong số nhiều kỹ năng nhận thức, tư duy trừu tượng có mặt khắp nơi cho khả năng xử lý lượng lớn thông tin của con người và rút ra các quy tắc và nguyên tắc chung.
Để kể tên một số, Kepler đã chắt lọc hàng ngàn phép đo vào Ba định luật chuyển động hành tinh của Kepler, mô tả chính xác quỹ đạo của các hành tinh xung quanh mặt trời.
Hoặc, trong việc ra quyết định quan trọng, con người cũng thấy trừu tượng hữu ích vì nó cung cấp một cái nhìn rộng hơn về môi trường.
Trọng tâm của bài viết này là làm thế nào LLM có thể xử lý các nhiệm vụ phức tạp liên quan đến nhiều chi tiết cấp thấp thông qua cách tiếp cận hai bước trừu tượng và lý luận.
Bước đầu tiên là dạy LLM lùi lại một bước và rút ra các khái niệm trừu tượng, cấp cao từ các ví dụ cụ thể, chẳng hạn như các khái niệm nền tảng và các nguyên tắc đầu tiên trong một miền.
Bước thứ hai là sử dụng các kỹ năng lý luận để dựa trên giải pháp dựa trên các khái niệm cấp cao và các nguyên tắc đầu tiên.
Các nhà nghiên cứu đã sử dụng một số lượng nhỏ các ví dụ về LLM để thực hiện suy luận ngược. Họ đã thử nghiệm một loạt các nhiệm vụ liên quan đến lý luận theo lĩnh vực cụ thể, giải quyết vấn đề chuyên sâu về kiến thức, lý luận thông thường đa hop đòi hỏi kiến thức thực tế.
Kết quả cho thấy hiệu suất của PaLM-2L được cải thiện đáng kể (lên tới 27%), điều này chứng tỏ suy luận ngược rất hiệu quả trong việc xử lý các nhiệm vụ phức tạp.
Trong các thí nghiệm, các nhà nghiên cứu đã thử nghiệm các loại nhiệm vụ khác nhau sau đây:
(1)THÂN CÂY
(2) QA kiến thức
(3) Lý luận đa bước nhảy
Các nhà nghiên cứu đã đánh giá ứng dụng trong các nhiệm vụ STEM để đo lường hiệu quả của phương pháp mới trong lý luận trong các lĩnh vực chuyên môn cao. (Bài viết này sẽ chỉ bao gồm những câu hỏi như vậy)
Rõ ràng, vấn đề trong điểm chuẩn MMLU đòi hỏi lý luận sâu sắc hơn về phía LLM. Ngoài ra, chúng đòi hỏi sự hiểu biết và áp dụng các công thức, thường là các nguyên tắc và khái niệm vật lý và hóa học.
Trong trường hợp này, trước tiên nhà nghiên cứu dạy mô hình được trừu tượng hóa dưới dạng các khái niệm và nguyên tắc đầu tiên, chẳng hạn như định luật chuyển động đầu tiên của Newton, hiệu ứng Doppler và năng lượng tự do Gibbs. Câu hỏi lùi lại tiềm ẩn ở đây là, “Các nguyên tắc và khái niệm vật lý hoặc hóa học liên quan đến việc giải quyết nhiệm vụ này là gì?”
Nhóm nghiên cứu đã cung cấp các cuộc trình diễn dạy mô hình ghi nhớ các nguyên tắc giải quyết nhiệm vụ từ kiến thức của chính họ.
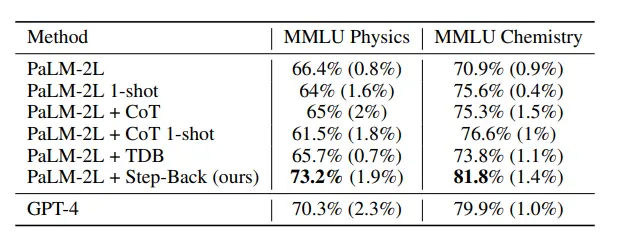 Bảng trên cho thấy hiệu suất của mô hình sử dụng kỹ thuật suy luận ngược và LLM với công nghệ mới được thực hiện tốt trong các nhiệm vụ STEM, đạt đến mức tiên tiến nhất ngoài GPT-4.
Bảng trên cho thấy hiệu suất của mô hình sử dụng kỹ thuật suy luận ngược và LLM với công nghệ mới được thực hiện tốt trong các nhiệm vụ STEM, đạt đến mức tiên tiến nhất ngoài GPT-4.
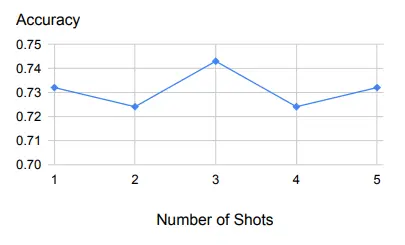 Bảng trên là một ví dụ về một số lượng nhỏ các mẫu và thể hiện hiệu suất mạnh mẽ với các kích thước mẫu khác nhau.
Bảng trên là một ví dụ về một số lượng nhỏ các mẫu và thể hiện hiệu suất mạnh mẽ với các kích thước mẫu khác nhau.
Đầu tiên, như chúng ta có thể thấy từ biểu đồ trên, suy luận ngược rất mạnh mẽ đối với một số ít ví dụ được sử dụng làm minh chứng.
Ngoài một ví dụ, điều tương tự cũng sẽ đúng khi thêm nhiều ví dụ hơn.
Điều này cho thấy rằng nhiệm vụ truy xuất các nguyên tắc và khái niệm có liên quan là tương đối dễ học, và một ví dụ minh họa là đủ.
Tất nhiên, trong quá trình thử nghiệm, vẫn sẽ có một số vấn đề.
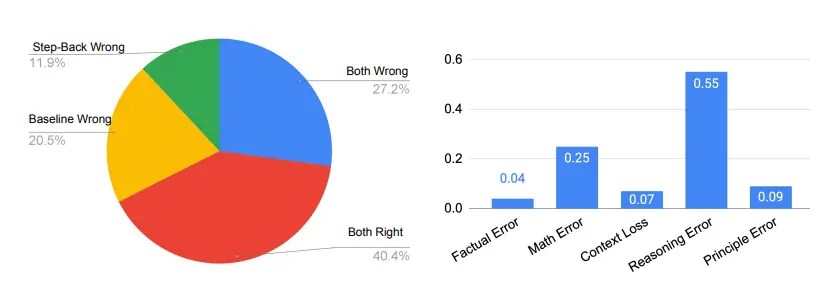
Năm loại lỗi xảy ra trong tất cả các bài báo, ngoại trừ lỗi nguyên tắc, xảy ra trong bước lý luận của LLM, trong khi lỗi nguyên tắc cho thấy sự thất bại của bước trừu tượng.
Như bạn có thể thấy ở phía bên phải của hình bên dưới, lỗi nguyên tắc thực sự chỉ chiếm một phần nhỏ trong số các lỗi mô hình, với hơn 90% lỗi xảy ra trong bước suy luận. Trong bốn loại lỗi trong quá trình suy luận, lỗi suy luận và lỗi toán học là những nơi chính có lỗi.
Điều này phù hợp với những phát hiện trong các nghiên cứu cắt bỏ rằng chỉ cần một vài ví dụ để dạy LLM cách trừu tượng. Bước suy luận vẫn là một nút cổ chai cho suy luận ngược để hoàn thành các nhiệm vụ đòi hỏi suy luận phức tạp, chẳng hạn như MMLU.
Điều này đặc biệt đúng đối với Vật lý MMLU, nơi các kỹ năng lý luận và toán học là chìa khóa để giải quyết vấn đề thành công. Điều này có nghĩa là ngay cả khi LLM truy xuất các nguyên tắc đầu tiên một cách chính xác, nó vẫn phải trải qua một quá trình suy luận nhiều bước điển hình để đi đến câu trả lời cuối cùng chính xác, đòi hỏi LLM phải có kỹ năng lý luận và toán học sâu sắc.
 Sau đó, các nhà nghiên cứu đã đánh giá mô hình trên bộ thử nghiệm của TimeQA.
Sau đó, các nhà nghiên cứu đã đánh giá mô hình trên bộ thử nghiệm của TimeQA.
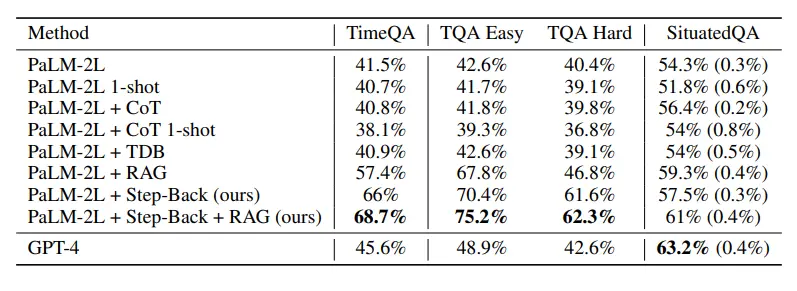
Như thể hiện trong hình dưới đây, các mô hình cơ sở của GPT-4 và PaLM-2L lần lượt đạt 45,6% và 41,5%, làm nổi bật độ khó của nhiệm vụ.
CoT hoặc TDB đã được áp dụng 0 lần (và một lần) trên mô hình cơ sở mà không có bất kỳ cải tiến nào.
Ngược lại, độ chính xác của mô hình cơ sở được tăng cường bởi tăng cường truy xuất thường xuyên (RAG) tăng lên 57,4%, làm nổi bật tính chất thực tế chuyên sâu của nhiệm vụ.
Kết quả của Step-Back + RAG cho thấy LLM quay lại bước khái niệm nâng cao rất hiệu quả trong suy luận ngược, điều này làm cho liên kết truy xuất LLM đáng tin cậy hơn và chúng ta có thể thấy rằng TimeQA có độ chính xác đáng kinh ngạc 68.7%.
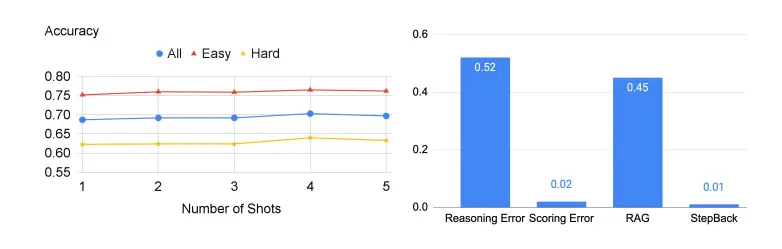
Tiếp theo, các nhà nghiên cứu chia TimeQA thành hai mức độ khó: dễ và khó được cung cấp trong tập dữ liệu gốc.
Không có gì đáng ngạc nhiên, tất cả các LLM đều hoạt động kém ở mức độ khó. Trong khi RAG có thể tăng độ chính xác từ 42,6% lên 67,8% ở mức dễ dàng, sự cải thiện nhỏ hơn nhiều đối với mức độ cứng, với dữ liệu chỉ cho thấy mức tăng từ 40,4% lên 46,8%.
Và đây là lúc kỹ thuật lý luận lạc hậu xuất hiện, vì nó lấy ra sự thật về các khái niệm cấp cao hơn và đặt nền tảng cho lý luận cuối cùng.
Lý luận ngược cộng với RAG tiếp tục cải thiện độ chính xác lên 62,3%, vượt qua 42,6% của GPT-4.
 Tất nhiên, vẫn còn một số vấn đề với công nghệ này khi nói đến TimeQA.
Tất nhiên, vẫn còn một số vấn đề với công nghệ này khi nói đến TimeQA.
Hình dưới đây cho thấy độ chính xác của LLM trong phần này của thí nghiệm và xác suất xảy ra lỗi ở bên phải.
 Tài nguyên:
Tài nguyên: