Tổng quan về Công nghệ Reddio: Từ EVM song song đến trình bày về trí tuệ nhân tạo
Tác giả: Mây tháng, Geek web3
Trong thời đại của việc cập nhật công nghệ Blockchain ngày càng nhanh hơn, tối ưu hóa hiệu suất đã trở thành một vấn đề quan trọng, con đường phát triển của Ethereum đã rõ ràng với Rollup là trung tâm, trong khi tính chất xử lý giao dịch tuần tự của EVM là một trở ngại, không thể đáp ứng được các tình huống tính toán đa nhiệm cao trong tương lai.
Trong bài viết trước - “Chặng đường tối ưu hóa EVM song song từ Reddio”, chúng ta đã tóm tắt ngắn gọn về phương pháp thiết kế EVM song song của Reddio. Trong bài viết hôm nay, chúng ta sẽ giải thích sâu hơn về kế hoạch kỹ thuật của nó và các tình huống kết hợp với trí tuệ nhân tạo.
Vì giải pháp công nghệ của Reddio sử dụng CuEVM, đây là một dự án tận dụng GPU để tăng cường hiệu suất thực thi của EVM, chúng tôi sẽ bắt đầu từ CuEVM.
Tổng quan về CUDA
CuEVM là một dự án tăng tốc EVM bằng GPU, nó chuyển đổi mã hoạt động của ETH EVM thành CUDA Kernels để thực thi song song trên GPU NVIDIA. Bằng khả năng tính toán song song của GPU, nó cải thiện hiệu suất thực thi lệnh EVM. Người dùng card đồ họa NVIDIA có thể thường nghe thấy từ CUDA này.
**Compute Unified Device Architecture, thực chất là một nền tảng tính toán song song và mô hình lập trình được phát triển bởi NVIDIA. Nó cho phép các nhà phát triển sử dụng khả năng tính toán song song của GPU để thực hiện tính toán chung (ví dụ: Khai thác trong Crypto, phép toán ZK), **thay vì chỉ giới hạn trong xử lý đồ họa.
Là một framework tính toán song song mở, CUDA thực chất là một phần mở rộng của ngôn ngữ C/C++, bất kỳ lập trình viên nền tảng nào quen thuộc với C/C++ cũng có thể nhanh chóng làm quen. Một khái niệm quan trọng trong CUDA là Kernel (hàm nhân), nó cũng là một loại hàm C++.

Tuy nhiên, khác với hàm C++ thông thường chỉ thực thi một lần, các hàm nhân lõi này được thực thi song song bởi N luồng CUDA khác nhau trong khi được gọi bởi cú pháp kích hoạt <<…>> N lần.
Mỗi luồng của CUDA đều được gán một ID luồng độc lập và sử dụng cấu trúc cấp độ luồng để phân chia luồng thành các khối (block) và lưới (grid) để quản lý các luồng song song lớn. Bằng trình biên dịch nvcc của NVIDIA, chúng ta có thể biên dịch mã CUDA thành chương trình có thể chạy trên GPU.

Quy trình làm việc cơ bản của CuEVM
Sau khi hiểu các khái niệm cơ bản của CUDA, bạn có thể xem quy trình làm việc của CuEVM.
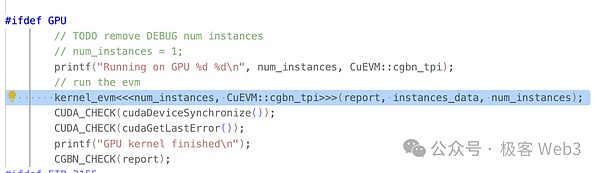
Cổng chính của CuEVM là run_interpreter, nơi mà giao dịch cần xử lý song song được nhập dưới dạng tệp json. Như đã thấy trong trường hợp sử dụng dự án, các thông tin được nhập đều là nội dung chuẩn của EVM, không cần phải xử lý hoặc dịch bởi các nhà phát triển.

Trong hàm run_interpreter(), chúng ta có thể thấy nó sử dụng cú pháp CUDA đã được định nghĩa <<…>> để gọi hàm kernel_evm(). Như đã đề cập ở trên, hàm nhân (kernel) sẽ được gọi song song trên GPU.
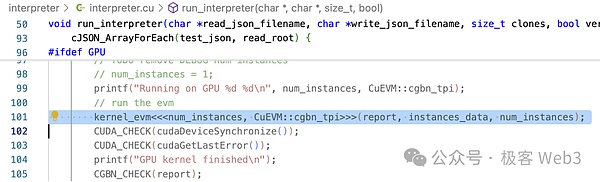
Trong phương thức kernel_evm(), evm->run() được gọi và chúng ta có thể thấy rằng có rất nhiều phán đoán nhánh để chuyển đổi opcode EVM thành các hoạt động CUDA.
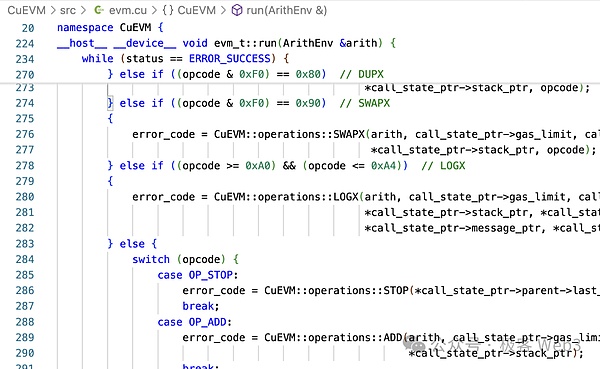
Ví dụ về mã hoạt động cộng trong EVM, chúng ta có thể thấy nó chuyển đổi ADD thành cgbn_add. Và CGBN (Cooperative Groups Big Numbers) là một thư viện tính toán số nguyên đa precison hiệu suất cao trên CUDA.

Hai bước này chuyển đổi mã hoạt động EVM thành mã hoạt động CUDA. Có thể nói, CuEVM cũng là việc thực hiện tất cả các hoạt động EVM trên CUDA. Cuối cùng, phương thức run_interpreter() trả về kết quả tính toán, tức là trạng thái thế giới và các thông tin khác.
Cơ bản về logic hoạt động của CuEVM đã được giới thiệu xong tại đây.
CuEVM có khả năng xử lý giao dịch song song, nhưng mục đích (hoặc trường hợp sử dụng chính) của CuEVM là để thực hiện kiểm thử Fuzzing: Fuzzing là một kỹ thuật kiểm thử phần mềm tự động, nó sử dụng dữ liệu không hợp lệ, không mong đợi hoặc ngẫu nhiên để đưa vào chương trình, từ đó quan sát phản hồi của chương trình để nhận biết các lỗi tiềm ẩn và vấn đề về bảo mật.
Chúng ta có thể thấy rằng Fuzzing rất thích hợp cho xử lý đồng thời. Tuy nhiên, CuEVM không xử lý vấn đề xung đột giao dịch, đó không phải là điều mà nó quan tâm. Nếu muốn tích hợp CuEVM, thì vẫn cần xử lý các giao dịch xung đột.
Trong bài viết trước đó “Hành trình tối ưu hóa EVM song song từ Reddio” chúng tôi đã giới thiệu cơ chế xử lý xung đột được sử dụng bởi Reddio, ở đây không cần phải nói thêm. Sau khi Reddio sắp xếp các giao dịch bằng cơ chế xử lý xung đột, chúng sẽ được gửi vào CuEVM. Nói cách khác, cơ chế sắp xếp giao dịch L2 của Reddio có thể chia thành hai phần: xử lý xung đột + thực hiện song song CuEVM.
Layer2, Parallel EVM, Three Crossroads of AI
Như đã đề cập trước đó, việc sử dụng EVM song song và L2 chỉ là bước đầu của Reddio, trong tương lai, nó sẽ kết hợp rõ ràng với truyền thông AI. Reddio, sử dụng GPU để thực hiện giao dịch song song nhanh chóng, tự nhiên phù hợp với tính năng AI nhiều cách:
- Khả năng xử lý song song của GPU mạnh mẽ, phù hợp để thực hiện các phép tính tích chập trong học sâu, những phép tính này về bản chất là phép nhân ma trận quy mô lớn và GPU được tối ưu hóa đặc biệt cho loại nhiệm vụ này.
- Cấu trúc phân cấp luồng GPU có thể tương ứng với các cấu trúc dữ liệu khác nhau trong tính toán trí tuệ nhân tạo, tăng hiệu suất tính toán thông qua việc siêu cấp luồng và đơn vị thực thi Warp và che giấu Trễ bộ nhớ.
- Cường độ tính toán là chỉ số chính để đánh giá hiệu suất tính toán AI, GPU tối ưu hóa cường độ tính toán, như việc áp dụng Tensor Core, để nâng cao hiệu suất nhân ma trận trong tính toán AI, thực hiện sự cân bằng hiệu quả giữa tính toán và truyền dữ liệu.
Vậy là AI và L2 cuối cùng được kết hợp như thế nào?
Chúng tôi hiểu rằng trong thiết kế cấu trúc Rollup, không chỉ có trình sắp xếp trong toàn bộ mạng, mà còn có một số vai trò tương tự như người giám sát và truyền tải để xác minh hoặc thu thập giao dịch, họ về bản chất cũng sử dụng cùng một loại máy khách như trình sắp xếp, chỉ khác về chức năng mà thôi. Trong Rollup truyền thống, vai trò phụ này có rất ít chức năng và quyền hạn, như vai trò như người giám sát trong Arbitrum, nó chủ yếu là tính chất thụ động và phòng thủ cũng như lợi ích cộng đồng, mô hình lợi nhuận của họ cũng đáng ngờ.
Reddio sẽ sử dụng kiến trúc Phi tập trung sắp xếp bởi các Người khai thác cung cấp GPU làm Nút. Toàn bộ mạng lưới Reddio có thể tiến hóa từ một mạng lưới L2 đơn giản đến một mạng lưới tổng hợp L2+AI, nó có thể hiệu quả thực hiện một số trường hợp sử dụng AI+Khối chuỗi:
Mạng cơ sở tương tác của AI Agent
Với sự phát triển không ngừng của công nghệ Blockchain, tiềm năng ứng dụng của AI Agent trong mạng Blockchain là rất lớn. Chúng ta có thể lấy ví dụ về AI Agent thực hiện giao dịch tài chính, những đại lý thông minh này có thể tự quyết định và thực hiện các giao dịch phức tạp, thậm chí có thể phản ứng nhanh chóng trong điều kiện giao dịch tần suất cao. Tuy nhiên, L1 khi xử lý các hoạt động mật độ lớn như vậy, cơ bản là không thể chịu được gánh nặng giao dịch lớn.

Với Reddio như một dự án L2, việc tăng tốc GPU có thể cải thiện đáng kể khả năng xử lý giao dịch song song. So với L1, L2 hỗ trợ thực hiện giao dịch song song với khả năng xử lý thông qua cao hơn, có thể xử lý hiệu quả yêu cầu giao dịch tần suất cao từ nhiều AI Agent, đảm bảo mạng hoạt động mượt mà.
Trong giao dịch tần suất cao, yêu cầu về tốc độ giao dịch và thời gian phản hồi của AI Agents rất khắt khe. L2 giảm thời gian xác minh và thực hiện giao dịch, từ đó làm giảm đáng kể Trễ. Điều này rất quan trọng đối với AI Agent cần phản ứng trong vài mili giây. Bằng cách chuyển đổi một lượng lớn giao dịch sang L2, cũng giúp giảm bớt vấn đề tắc nghẽn trên Mạng chính. Tạo điều kiện cho hoạt động của AI Agents trở nên hiệu quả kinh tế hơn.
Với sự chín muồi của các dự án L2 như Reddio, AI Agent sẽ đóng vai trò quan trọng hơn trên chuỗi Khối, thúc đẩy sự kết hợp sáng tạo của Tài chính phi tập trung và các kịch bản ứng dụng AI khác trên chuỗi Khối.
Phi tập trungKhả năng tính toán市场
Reddio未来会采用Phi tập trung排序器的架构,Người khai thác以GPUKhả năng tính toán来决定排序权利,整体网络参与者的GPU的性能会随着竞争逐渐提升,甚至能够达到用来作为AI训练的水平。
Xây dựng thị trường Khả năng tính toán GPU Phi tập trung, cung cấp tài nguyên Khả năng tính toán với chi phí thấp hơn cho đào tạo và suy luận trí tuệ nhân tạo. Khả năng tính toán từ nhỏ đến lớn, từ máy tính cá nhân đến cụm phòng máy, các cấp độ Khả năng tính toán GPU khác nhau đều có thể tham gia thị trường này để đóng góp Khả năng tính toán dư thừa của chính mình và kiếm lợi nhuận, mô hình này có thể giảm chi phí tính toán AI và cho phép nhiều người tham gia vào phát triển và ứng dụng mô hình AI.
Trong trường hợp sử dụng thị trường Phi tập trung Khả năng tính toán thị trường, trình tự có thể không chịu trách nhiệm chính cho việc tính toán trực tiếp AI, nhưng chức năng chính của nó là xử lý các giao dịch và điều phối AIKhả năng tính toán trên mạng. Đối với Khả năng tính toán và phân công nhiệm vụ, có hai chế độ:
- Phân phối tập trung từ trên xuống. Vì có bộ sắp xếp, bộ sắp xếp có thể phân phối yêu cầu tính toán nhận được cho Nút uy tín và phù hợp. Phương pháp phân phối này mặc dù lý thuyết có vấn đề tập trung và không công bằng, nhưng thực tế lợi ích hiệu quả mà nó mang lại vượt xa nhược điểm, và trong tương lai, bộ sắp xếp phải đáp ứng tính chất tích cực của toàn bộ mạng lưới để phát triển lâu dài, tức là có ràng buộc ngầm nhưng trực tiếp để đảm bảo bộ sắp xếp không có sự thiên vị nghiêm trọng.
- Lựa chọn nhiệm vụ tự phát từ dưới lên. Người dùng cũng có thể gửi yêu cầu tính toán AI cho Nút bên thứ ba, điều này rõ ràng hiệu quả hơn việc gửi trực tiếp cho Bộ sắp xếp và ngăn chặn kiểm duyệt và thiên vị của Bộ sắp xếp. Sau khi tính toán hoàn tất, Nút đó sẽ đồng bộ kết quả tính toán với Bộ sắp xếp và lưu trữ trên chuỗi.
Chúng ta có thể thấy trong kiến trúc L2 + AI, thị trường Khả năng tính toán có tính linh hoạt cao, có thể tập hợp Khả năng tính toán từ hai hướng, tối đa hóa hiệu suất sử dụng tài nguyên.
on-chainAI推理
Hiện tại, độ trưởng thành của mô hình Mã nguồn mở đã đủ để đáp ứng nhiều nhu cầu đa dạng. Với sự tiêu chuẩn hóa dịch vụ suy luận AI, việc khám phá cách đưa Khả năng tính toán lên chuỗi để thực hiện việc định giá tự động trở thành khả thi. Tuy nhiên, điều này đòi hỏi vượt qua nhiều thách thức kỹ thuật:
- Phân phối và ghi nhận yêu cầu hiệu quả: Đối với việc suy luận mô hình lớn, việc Trễ phải được đáp ứng cao, cơ chế phân phối yêu cầu hiệu quả rất quan trọng. Mặc dù lượng dữ liệu yêu cầu và phản hồi lớn và có tính riêng tư, không thể được công khai trên on-chain, nhưng cần phải tìm được sự cân bằng giữa ghi nhận và xác minh - ví dụ, bằng cách lưu trữ băm.
- Xác minh đầu ra của Nút về khả năng tính toán: Nút có thực sự hoàn thành nhiệm vụ tính toán được quy định không? Ví dụ, Nút báo cáo giả về kết quả tính toán của mô hình nhỏ thay cho mô hình lớn.
- Reasoning hợp đồng thông minh:Kết hợp mô hình AI với hợp đồng thông minh để tiến行 tính toán trong nhiều tình huống là bắt buộc. Bởi vì quyết định của AI có tính không chắc chắn và không thể áp dụng cho mọi mặt on-chain, nên logic của ứng dụng AI dApp trong tương lai rất có thể một phần nằm ở off-chain và một phần nằm ở hợp đồng on-chain, hợp đồng on-chain giới hạn tính hợp lệ và tính hợp lệ của đầu vào mà off-chain cung cấp. Trong hệ sinh thái ETH, việc kết hợp với hợp đồng thông minh đôi khi phải đối mặt với tính tuần tự và hiệu suất thấp của EVM.
Tuy nhiên trong kiến trúc của Reddio, những vấn đề này đều được giải quyết một cách tương đối dễ dàng:
- Bộ sắp xếp phân phối yêu cầu hiệu quả hơn rất nhiều so với L1, có thể coi như hiệu suất của Web2. Còn vị trí ghi chú và phương thức lưu trữ dữ liệu có thể được giải quyết bằng các giải pháp DA giá rẻ.
- Kết quả tính toán AI có thể được ZKP xác minh về tính chính xác và thiện chí. ZKP, mặt khác, được đặc trưng bởi xác minh rất nhanh nhưng chậm tạo ra bằng chứng. Việc tạo ra ZKP cũng có thể được tăng tốc bằng GPU hoặc TEE.
- Solidty → CUDA → GPU là một dòng chính song song EVM cơ bản của Reddio. Vì vậy, dường như đây là vấn đề đơn giản nhất đối với Reddio. Hiện tại, Reddio đang hợp tác với eliza của AiI6z để đưa mô-đun của nó vào Reddio, đây là một hướng rất đáng khám phá.
Tổng kết
Nhìn chung, các giải pháp Layer2, EVM song song và công nghệ AI dường như không liên quan nhau, nhưng Reddio thông qua việc tận dụng tối đa tính năng tính toán của GPU, đã khéo léo kết hợp những lĩnh vực đổi mới lớn này một cách hữu ích.
Reddio has improved transaction speed and efficiency on Layer2 by leveraging the parallel computing capabilities of GPUs, enhancing the performance of the ETH blockchain’s second layer. Integrating AI technology into blockchain is an innovative and promising attempt. The introduction of AI can provide intelligent analysis and decision support for on-chain operations, enabling more intelligent and dynamic blockchain applications. This cross-disciplinary integration undoubtedly opens up new paths and opportunities for the entire industry.
Tuy nhiên, điều cần lưu ý là lĩnh vực này vẫn đang ở giai đoạn sơ khai và đòi hỏi nhiều nghiên cứu và khám phá. Sự tiến hóa và tối ưu hóa liên tục của công nghệ, cùng với sự tưởng tượng và hành động của các phe tiên phong trên thị trường, sẽ là động lực quan trọng để thúc đẩy sự phát triển của sáng tạo này. Reddio đã đi một bước quan trọng và táo bạo tại điểm giao nhau này, và chúng tôi mong chờ thêm nhiều bước đột phá và bất ngờ trong tương lai trong lĩnh vực hợp nhất này.