
ระบบ AI สำหรับความทรงจำ MemPalace ที่มีส่วนร่วมในการพัฒนาโดย Milla Jovovich อ้างว่าทดสอบได้คะแนนเต็มและได้รับความนิยมอย่างรวดเร็ว แต่กลับถูกชุมชนวิพากษ์ว่าเกี่ยวข้องกับการโกงในการทดสอบและการทำให้ข้อมูลเข้าใจผิด จากการทดสอบจริงพบว่าผลลัพธ์ถูกยกให้เกินจริงและมีข้อผิดพลาดจำนวนมาก ทีมงานยอมรับข้อบกพร่องแล้วและกำลังดำเนินการแก้ไขอยู่
Milla Jovovich สร้าง AI Memory Palace สร้างความสนใจจากภายนอก
เมื่อวานนี้ (4/7) ในวงการ AI มีข่าวใหญ่ นั่นคือ นักแสดงหญิงฮอลลีวูด Milla·Jovovich ผู้โด่งดังจาก Resident Evil และ The Fifth Element และผู้พัฒนา Ben Sigman ใช้ Claude Code เพื่อช่วยในการพัฒนา “MemPalace” ระบบ AI สำหรับความทรงจำแบบโอเพนซอร์ส
อยู่ๆ ก็มีการแพร่หลายไปทั่วกับคำกล่าวที่ว่า “ไอดอลระดับซูเปอร์สตาร์ของฮอลลีวูดข้ามสายมาสร้างโปรเจกต์ที่ได้คะแนนเต็ม” จนถึงปัจจุบัน MemPalace บน GitHub ก็ได้รับมากกว่า 20,000 ดาวแล้ว แต่ไม่นานก็เกิดการตั้งข้อสงสัยจากชุมชนผู้พัฒนา: เป็นของจริงหรือเป็นการปั้นกระแส?
ก่อนอื่นมาดูกันว่าแรงจูงใจที่ทำให้ MemPalace ถือกำเนิดคืออะไร เอกสารทางการระบุว่าต้องการแก้ปัญหาที่ในระบบ AI ปัจจุบัน เนื้อหาการสนทนากับผู้ใช้งาน กระบวนการตัดสินใจ และการอภิปรายเกี่ยวกับสถาปัตยกรรม มักจะหายไปหลังจบช่วงการทำงาน ส่งผลให้ความพยายามหลายเดือนต้อง ลดลงถึงศูนย์
เพื่อแก้ปัญหานี้ MemPalace ใช้โครงสร้างเชิงพื้นที่เพื่อเก็บความทรงจำ โดยจัดข้อมูลอย่างชัดเจนเป็น “ปีก” ที่เป็นตัวแทนของบุคลากรหรือโปรเจกต์ และจัดอยู่ในโครงสร้างระดับต่างๆ เช่น ทางเดิน ห้อง และลิ้นชัก เพื่อเก็บต้นฉบับของบทสนทนาไว้สำหรับการค้นหาเชิงความหมายในภายหลัง
ทีมพัฒนากล่าวอ้างว่า MemPalace ได้คะแนนสมบูรณ์ 100% ในเกณฑ์ประเมินความทรงจำระยะยาว LongMemEval และทำได้อัตราความแม่นยำ 96.6% โดยไม่เรียกใช้ API ภายนอกใดๆ อีกทั้งสามารถทำงานได้อย่างครบถ้วนบนเครื่องท้องถิ่น ไม่จำเป็นต้องสมัครบริการคลาวด์ และมาพร้อมระบบภาษาถิ่น AAAK ที่อ้างว่าสามารถบีบอัดแบบไม่สูญเสียได้ถึง 30 เท่า
ที่มาของภาพ: GitHub ดาราภาพยนตร์ชาวอเมริกัน Milla Jovovich สร้าง AI Memory Palace สร้างความสนใจจากภายนอก
เพื่อนร่วมวงการและชุมชนต่างตั้งข้อสงสัย การทดสอบวิธีการและการโฆษณาที่มีข้อบกพร่อง
อย่างไรก็ตาม ผลการทดสอบที่กล่าวอ้างว่า LongMemEval ได้คะแนนเต็ม ก็ไม่นานก็เรียกเสียงวิจารณ์จากเพื่อนร่วมวงการ
PenfieldLabs ซึ่งเป็นบริษัทที่ผลิตระบบความทรงจำ AI เช่นกัน ชี้ว่า MemPalace อ้างว่าได้คะแนนเต็มในชุดข้อมูล LoCoMo ซึ่งเป็นไปไม่ได้ทางคณิตศาสตร์ เพราะคำตอบมาตรฐานของชุดข้อมูลนั้นเองมีข้อผิดพลาดถึง 99 ข้อ
จากการวิเคราะห์ PenfieldLabs พบว่า คะแนน 100% ของ MemPalace มาจากการตั้งค่าจำนวนการค้นหาไว้ 50 ครั้ง แต่จำนวนขั้นสูงสุดของช่วงการสนทนาในชุดข้อมูลทดสอบมีเพียง 32 ครั้ง ซึ่ง แปลว่าระบบข้ามขั้นการค้นหาโดยตรง และส่งข้อมูลทั้งหมดให้โมเดล AI อ่าน
สำหรับผลการได้คะแนน 100% ใน LongMemEval ได้มีการพบว่าทีมพัฒนากำหนดเป้าต้องแก้ไขเป็น “ปัญหาเฉพาะ 3 ข้อ” ที่ทำผิดในการพัฒนาเป็นหลัก เขียนโค้ดสำหรับแก้ไขโดยเฉพาะ ซึ่งมีข้อสงสัยว่าเป็นการโกงสำหรับชุดทดสอบ

ที่มาของภาพ: Reddit เพื่อนร่วมวงการ PenfieldLabs ชี้ว่า MemPalace อ้างว่าได้คะแนนเต็มในชุดข้อมูล LoCoMo ซึ่งเป็นไปไม่ได้ทางคณิตศาสตร์
การทดสอบจริงบน GitHub: ชุดการทดสอบมีส่วนที่ทำให้เข้าใจผิด
ผู้ใช้ GitHub hugooconnor ได้แสดงความคิดเห็นหลังทำการทดสอบจริงว่า เมื่อ MemPalace อ้างว่ามีอัตราความแม่นยำในการค้นหาได้สูงถึง 96.6% แต่ในความเป็นจริงไม่ได้ใช้โครงสร้าง AI Memory Palace ที่ MemPalace โฆษณาเลย hugooconnor ระบุว่าการทดสอบของพวกเขาเพียงเรียกใช้ฟังก์ชันเริ่มต้นของฐานข้อมูลระดับล่าง ChromaDB เท่านั้น และไม่มีส่วนเกี่ยวข้องกับตรรกะการจัดหมวดหมู่ที่โปรเจกต์ย้ำ เช่น ปีก ห้อง หรือ ลิ้นชัก
หลังทดสอบ hugooconnor พบว่าเมื่อระบบเปิดใช้งานตรรกะการจัดหมวดหมู่เฉพาะของ Memory Palace อย่างแท้จริง ผลการค้นหากลับแย่ลง ยกตัวอย่างในโหมดห้อง ความแม่นยำลดลงถึง 89.4% และเมื่อเปิดเทคนิคการบีบอัด AAAK ความแม่นยำยิ่งลดลงถึง 84.2% ทั้งสองค่าต่ำกว่าประสิทธิภาพของฐานข้อมูลค่าเริ่มต้น
hugooconnor ยังวิจารณ์วิธีการทดสอบว่า สภาพแวดล้อมการทดสอบของ MemPalace ตั้งใจจำกัดช่วงการค้นหาของแต่ละคำถามให้แคบลงเหลือประมาณ 50 ขั้นตอนของบทสนทนา การหาคำตอบในคลังข้อมูลตัวอย่างที่เล็กมากเช่นนี้ง่ายเกินไป
หากขยายช่วงให้ครอบคลุมมากกว่า 19,000 ขั้นตอนของบทสนทนาในสถานการณ์จริง อัตราความแม่นยำของการค้นหาด้วยคำหลักแบบดั้งเดิมจะดิ่งลงเหลือ 30% ซึ่งแสดงว่า วิธีการทดสอบปัจจุบันของ MemPalace ปิดบังปัญหาความยากในการค้นหาที่แท้จริง
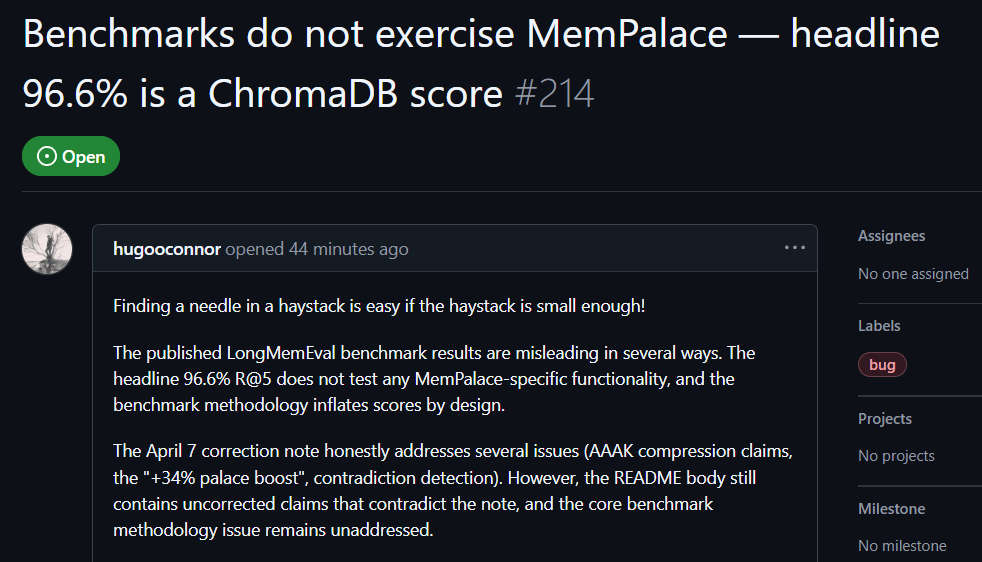
ที่มาของภาพ: GitHub ผู้ใช้ GitHub ทำการทดสอบจริง ชี้ว่า ชุดการทดสอบเกณฑ์มาตรฐานของ MemPalace มีส่วนที่ทำให้เข้าใจผิด
ในขณะเดียวกัน แม้ทีมพัฒนาจะเผยแพร่คำชี้แจงแก้ไข โดยยอมรับว่าเทคนิค AAAK ถูกยืนยันว่าเป็นการบีบอัดแบบสูญเสีย และสัญญาว่าจะปรับปรุงเอกสารและการออกแบบระบบตามคำวิจารณ์อย่างเข้มงวดจากชุมชน แต่เอกสารคำอธิบายหลักของโปรเจกต์ยังคงรักษาข้อกล่าวอ้างที่ยังไม่ได้แก้ไขหลายประการ รวมถึงการอ้างว่า “บีบอัดแบบไม่สูญเสียได้ 30 เท่า” และ “เพิ่มการค้นหา 34%” และกราฟเปรียบเทียบกับคู่แข่งรายอื่นก็ยังขาดแหล่งที่มาที่ชัดเจนโดยสิ้นเชิง
โค้ดต้นฉบับของ MemPalace เผชิญกับ Bug หลายรายการ
เมื่อมีนักพัฒนามากขึ้นเรื่อยๆ ดาวน์โหลดเพื่อทดสอบ ปัจจุบันบนแพลตฟอร์ม GitHub จึงมีรายงาน Bug จำนวนมากเกี่ยวกับโค้ดต้นฉบับของ MemPalace
ผู้ใช้ cktang88 ได้ระบุข้อบกพร่องร้ายแรงหลายประการ รวมถึงคำสั่งสำหรับการบีบอัดใช้งานไม่ได้และทำให้ระบบล่ม ตรรกะการคำนวณจำนวนคำในบทคัดย่อผิดพลาด ข้อมูลสถิติการขุดหาห้องไม่แม่นยำ และทุกครั้งที่มีการเรียกใช้งาน เซิร์ฟเวอร์จะโหลดข้อมูลคำอธิบายทั้งหมดเข้าหน่วยความจำ ส่งผลให้เกิดปัญหาการใช้ทรัพยากรอย่างหนัก
ปัญหาที่ถูกชี้อีกประการยังรวมถึง ระบบจะเขียนชื่อสมาชิกในครอบครัวของนักพัฒนาแบบบังคับลงในไฟล์ตั้งค่าเริ่มต้น และมีขีดจำกัดการแสดงแบบบังคับสำหรับข้อมูล 10,000 รายการเมื่อทำการตรวจสอบสถานะ
เพื่อแก้ไขปัญหาเหล่านี้ ชุมชนโอเพนซอร์สเริ่มลงมือซ่อมแซมอย่างจริงจังแล้ว ผู้ใช้ adv3nt3 ส่งคำขอแก้ไขหลายรายการ รวมถึงการแก้ไขข้อมูลสถิติการขุด การลบชื่อสมาชิกในครอบครัวที่ถูกตั้งค่าไว้ล่วงหน้า และการเลื่อนเวลาเริ่มต้นการสร้างแผนที่ความรู้ (knowledge graph) ทีมพัฒนาภายหลังยังยอมรับความผิดพลาดเหล่านี้ และกำลังแก้ปัญหาด้านโค้ดอย่างต่อเนื่องผ่านความร่วมมือของชุมชน
Vibe Coding ของ Milla Jovovich เท่ห์มาก การตลาดไม่เท่าเทียม
สำหรับโปรเจกต์ MemPalace ผู้ใช้ Hacker News darkhanakh สรุปไว้ว่า: MemPalace ทำให้รู้สึกเหมือนมีภาพของ OpenClaw กล่าวคือ ทำผลการทดสอบเกณฑ์มาตรฐาน (benchmark) ให้ดูสมบูรณ์แบบโดยการปรับแต่ง แล้วค่อยเอามาห่อหุ้มเป็นความก้าวหน้าครั้งสำคัญเพื่อใช้ทำการตลาด
เขามองว่าเทคโนโลยีระดับล่างของ MemPalace อาจจะน่าสนใจจริง แต่ภายใต้เงื่อนไขที่วิธีการทดสอบมีข้อบกพร่องแบบนั้น และยังนำเสนอด้วยการโฆษณา “คะแนนสูงสุดในประวัติศาสตร์ที่เปิดเผยต่อสาธารณะ” ก็ยังไม่ค่อยเหมาะสมนัก “แต่ทว่า ผมคิดว่าการที่ Milla Jovovich เล่น Vibe Coding เรื่องนี้ ผมก็ยังรู้สึกว่ามันเท่อยู่ดี”
อ่านเพิ่มเติม:
AI เขียนโค้ดแล้วเกิดปัญหา! แอป “ผู้ล่าเหยื่อ” สินค้าใกล้หมดอายุในร้านสะดวกซื้อ โดนปัญหาความปลอดภัยทางไซเบอร์ บ้านทั้งหลังกำลัง GPS แบบเปลือยเปิดเผย
